Containers
Catching up with Managed Node Groups in Amazon EKS
Since its launch in 2018, Amazon Elastic Kubernetes Service (Amazon EKS) has continued to deliver upon and expand its mission to simplify the process of building, securing, operating, and maintaining Kubernetes clusters. The first realization of that mission was a managed Kubernetes control plane, swapping the heavy lifting of provisioning, curating, and assembling the various software components that make up a cluster control plane with a single API call. In 2019, EKS expanded the scope of lifecycle management operations to include support for provisioning and managing cluster compute resources with managed node groups.
Amazon EKS managed node groups automates the provisioning and lifecycle management of nodes for your Kubernetes clusters. It provides an abstraction to Amazon EC2 instances and Auto Scaling groups, enabling a set of simple one-step operations in EKS to provision and manage groups of cluster nodes. When using managed node groups in EKS, your Kubernetes nodes are backed by EC2 instances in your account which are managed by an Auto Scaling group. With managed node groups, you don’t need to separately provision EC2 instances, curate your own Kubernetes node AMIs, or worry about your nodes joining the cluster. You can create, upgrade, and terminate groups of nodes with simple operations in EKS.
We are always improving and expanding the capabilities of the service for our customers. We’ve been motivated since the launch of managed node groups to lower the barrier to entry and provide all of the customizations, configurations, and automation that customers need. The goal is for managed node groups to be the default and best method of rolling out EC2 compute resources for your EKS clusters, removing even more infrastructure heavy lifting for our customers.
As managed node groups were designed initially for the best out-of-the-box experience, at launch only the curated Amazon EKS-optimized Amazon Linux 2 AMIs were supported with a consistent, default configuration. Last year we introduced support for custom AMIs as well as customization through EC2 launch template specifications, which enabled a wide array of customer use cases. We’ve also increased the capacity of groups and their default service quotas, allowing for 30 groups of 450 nodes each.
With EKS managed node groups adoption accelerating, we’re very motivated to make this feature the best way to provision discrete Kubernetes compute resources on EC2. Over the last few months, the team has shipped several improvements, unlocking more use cases and simplifying operations for our customers. In the remainder of this post, we’ll walk through these recent features and wrap up with a look to the future.
Managed node groups feature roundup
Parallel node upgrades
Kicking things off with the most recent EKS feature, we launched parallel node upgrades for managed node groups at the start of the month. When you upgrade a managed node group in EKS, the process is automated and designed to incur the least disruption to your scheduled workloads. Kubernetes nodes are cordoned and drained then replaced with the upgraded node version during this process. This is described more fully in the Amazon EKS User Guide. Since the launch of managed node groups, this operation was done one node at a time to offer the least disruptive default behavior.
This feature offers you a new configurable element that specifies either the number of nodes or the percentage of total nodes within a group that can be unavailable during an upgrade operation. This configuration allows you to decide how many nodes EKS will update at a time based upon your application’s ability to tolerate larger numbers of nodes being cycled. This configuration can be specified when creating a new node group, or you can modify an existing group. Either way, you’ll see a configuration element like the one shown here from the ‘Edit Node Group’ dialog on an existing group.
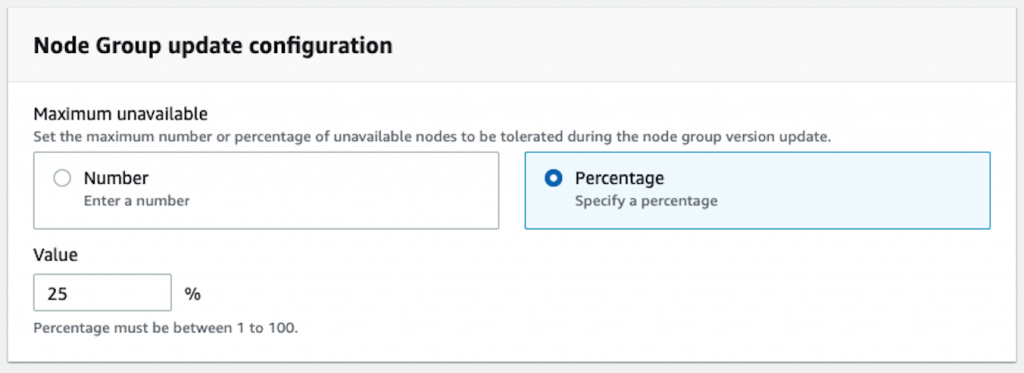
This feature can substantially reduce the overall upgrade operation time of a node group. How you set this will be largely related to the design of your application, how resources are scaled within your clusters, and the size of your node groups. We think that 10-25% is a good range to start testing with.
For more information, please refer to the documentation on node group update configuration in the Amazon EKS User Guide.
Kubernetes node taints
Next up is native support for specifying Kubernetes node taints through the managed node groups API. This is one of the most upvoted issues on the AWS Container Services Roadmap, and we were very excited to get this launched a couple of months back. EKS has supported adding Kubernetes labels to nodes automatically as part of managed node group configuration. But to add node taints prior to this feature, customers had to apply them via the Kubernetes API once the nodes joined the cluster.
This feature allows you to specify taints for the nodes within a managed node group specification. These can be specified during node group creation, or by modifying an existing group configuration. Either way, you’ll see a configuration element like the one shown here, again from the ‘Edit Node Group’ dialog.
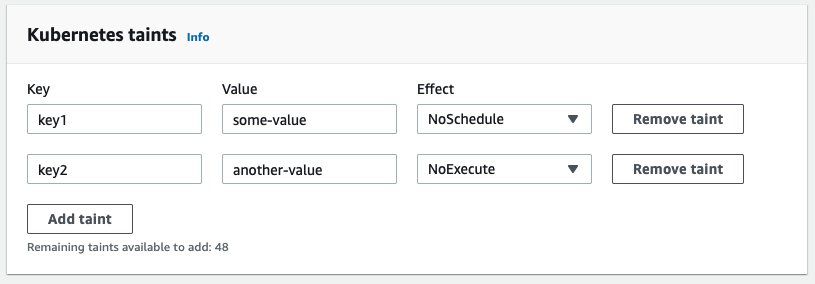
Once your node group is created, or an update is complete, your nodes will be tainted as specified.

In Kubernetes, taints can be used along with tolerations to target workload scheduling such that applications and services run only on specified compute resources within your cluster.
The pattern consists of adding taints to a set of nodes to indicate that it should not accept pods from the scheduler unless those pods have specific tolerations which allow them to be scheduled. Taints are key-value pairs tied to specific scheduling actions. Tolerations can be used in pod specifications to match these taints, giving you an explicit configuration pattern to bind pods to particular nodes.
This combination can be used to target workload scheduling based upon node attributes, for example runtime architecture or a specific access to a resource.
For more information on taints and tolerations, check out the Kubernetes documentation. To start working with taints in managed node groups, please refer to the Amazon EKS User Guide.
Scale-to-zero in the managed node groups API
This feature introduces a first phase in support for scaling EKS managed node groups up from and back down to zero. With this change, you can now set both minimum and desired size to zero in a node group’s configuration. This allows you to invoke operations against the node group to scale down to zero nodes, and also scale up from a group with zero nodes.
You can achieve a node group configuration that allows for scaling in to zero by setting the group configuration’s minimum size to zero.
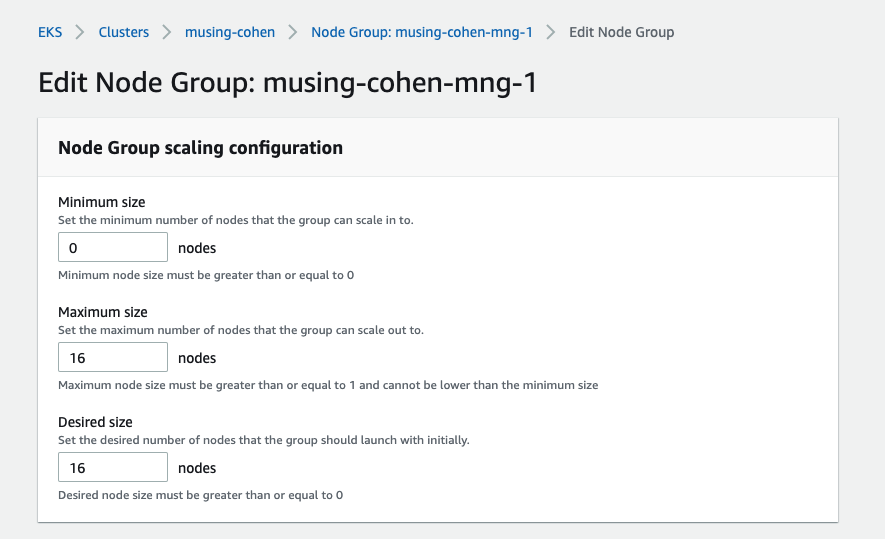
You can then scale the desired size in to zero, and back out to a desired size up to the configured maximum. You can do this easily using eksctl scale, as shown below.

This is handy for development clusters that you can shut down compute resources on when not in use, and you can build this into pipelines to scale temporary workload resources out and back in to zero. The next phase of this work will enable Cluster Autoscaler support upstream, modifying the autoscaler to call EKS MNG APIs to discover nodes and taints of node groups that are scaled to zero as described in the proposal upstream.
Amazon EKS-optimized AMI changes and version support
To close out our list of recent features, I wanted to call out a couple of changes in and around the EKS-optimized Amazon Linux 2 AMIs.
The first change of note is that managed node groups now support the use of all versions of its curated set of EKS-optimized AMIs. Until recently, only the latest version for a given Kubernetes release was available when creating a new node group. Now, you may specify which version you’d like to use. This gives you the ability to test and deploy applications with a specific AMI release version, including previous versions. You can review the list of available AMIs in the Amazon EKS User Guide, and specify which to use via the CreateNodegroup API.
Another recent change relates to the content of the EKS-optimized AMIs more directly. Starting with the 20210621 AMI release version, the AWS Systems Manager Agent (SSM Agent) is now installed and enabled by default. This saves you from needing to add user data in a launch template or installation post-group creation by other means. Now, EC2 instances spun up as part of a node group will automatically join in Fleet Management and Application Manager in AWS Systems Manager features. To learn more about how to use SSM with EKS, check out the Systems Manager documentation.
Looking ahead
We plan to continue to deliver on our goal to make managed node groups the best way to provision discrete compute resources for EKS. Below are a few of the features we have planned next, with more on the horizon.
Bottlerocket in managed node groups
Botttlerocket is an open source Linux distribution maintained by AWS which is expressly designed to host container workloads. It’s minimized and secure-by-default, containing only the software needed to run containers in an orchestration environment such as Amazon EKS. When installed, the host root file system is mounted read-only, and the networking configuration and secure and minimal. You can currently use Bottlerocket for your self-managed node groups, and with managed node groups using the custom AMI feature support mentioned before. The team is currently working on adding Bottlerocket as a native option when creating managed node groups in EKS, to monitor this feature check out the roadmap issue.
Scale-to-zero in Cluster Autoscaler
As mentioned above, the team is working on the next phase of scale-to-zero for managed node groups. This work is upstream in the Cluster Autoscaler project, and has been reviewed and approved in this proposal. Phase two of this work won’t impact the manual interaction and scaling to zero as discussed above, but of course automated scaling of compute resources in and out based on workload demand is what is needed for most production use cases. To follow the progress of this next phase, see the roadmap issue as we continue to deliver on this end-to-end solution for managed compute scaling.
Managed node groups as default in eksctl
The eksctl project is the official open source CLI of Amazon EKS, maintained by Weaveworks and supported by AWS. It’s a tool for creating and managing EKS clusters, and this includes adding and managing the lifecycle of node groups. If you’re new to EKS, it’s a great way to get started using the service. It’s a daily go-to tool for managing cluster instances imperatively, and is also commonly used in infrastructure pipelines enabled by its YAML-based configuration files.
Currently the default behavior resulting from eksctl create cluster or eksctl create nodegroup is to provision an unmanaged node group. EKS Managed Node Groups are reaching a feature parity with unmanaged node options, and overall MNG offers a better usability experience. With this change, which will be released in the next upstream version of eksctl, it will now create managed node groups by default.
What’s next?
As always, our work is motivated by our customers and defined by your needs. We will continue our work in making managed node groups the best way to provision and manage EC2 compute instances for your EKS clusters. If you have ideas for new features, or if you’re experiencing blockers to managed node group adoption in EKS, we want to hear from you! Please take a look at the AWS Containers Roadmap on GitHub and open an issue, or upvote existing issues to let us know they matter to you. Reach out if you have questions about these or any other EKS features, and if there’s any particular content you’d like to see, let us know!