AWS Machine Learning Blog
New Amazon Forecast API that creates up to 40% more accurate forecasts and provides explainability
We’re excited to announce a new forecasting API for Amazon Forecast that generates up to 40% more accurate forecasts and helps you understand which factors, such as price, holidays, weather, or item category, are most influencing your forecasts. Forecast uses machine learning (ML) to generate more accurate demand forecasts, without requiring any ML experience. Forecast brings the same technology used at Amazon to developers as a fully managed service, removing the need to manage resources.
With today’s launch, Forecast can now forecast up to 40% more accurate results by using a combination of ML algorithms that are best suited for your data. In many scenarios, ML experts train separate models for different parts of their dataset to improve forecasting accuracy. This process of segmenting your data and applying different algorithms can be very challenging for non-ML experts. Forecast uses ML to learn not only the best algorithm for each item, but the best ensemble of algorithms for each item, leading to up to 40% better accuracy on forecasts.
To further increase forecast model accuracy, you can add additional information or attributes such as price, promotion, category details, holidays, or weather information, but you may not know how each attribute influences your forecast. Forecasting is mission critical, and therefore having a certain level of attribute explainability is helpful for decision-making. With today’s launch, Forecast now helps you understand and explain how your forecasting model is making predictions by providing explainability reports after your model has been trained. Explainability reports include impact scores, so you can understand how each attribute in your training data contributes to either increasing or decreasing your forecasted values. By understanding how your model makes predictions, you can make more informed business decisions. For example, you can verify that your model is behaving as expected by confirming that attributes with a high impact score represent a valid signal for predictions in your business problem.
You can bring in your recent data to use the latest insights before forecasting for the next period. However, in doing so, you have to train your entire forecasting model again, which is a time-consuming process. Most Forecast customers deploy their forecasting workflow within their operations such as an inventory management solution and run their operations at a set cadence. Because retraining on the entire data can be time-consuming, customer operations may get delayed. With today’s launch, you can save up to 50% of retraining time by selecting to incrementally retrain your models with the new information that you have added.
To get more accurate forecasts, faster retraining, and explainability, use the new experience through the AWS Management Console or the CreateAutoPredictor API. This launch is accompanied with new pricing, which you can review at Amazon Forecast pricing.
Interpreting model explainability
Explainability helps you better understand how the attributes in your datasets, such as price, category, or holidays, impact your forecast values. Forecast uses a metric called impact scores to quantify the relative impact of each attribute and determine whether they generally increase or decrease forecast values.
Impact scores measure the relative impact attributes have on forecast values. For example, if the price attribute has an impact score that is twice as large as the brand_id attribute, you can conclude that the price of an item has twice the impact on forecast values than the product brand. Impact scores also provide information on whether an attribute increases or decreases the forecasted value. A negative impact score reflects that the attribute tends to decrease the value of the forecast.
Impact scores measure the relative impact of attributes to each other, not the absolute impact. If an attribute has a low impact score, that doesn’t necessarily mean that it has a low impact on forecast values; it means that it has a lower impact on forecast values than other attributes used by the predictor. If you change attributes in your predictor, the impact scores may differ, and the attribute with the low impact score may have a higher score relative to other attributes. Also, you can’t use impact scores to determine whether particular attributes improve the model accuracy or not. You should use accuracy metrics such as weighted quantile loss and others provided by Forecast to access predictor accuracy.
In the following graph, we take an example of a predictor where the relative impact of attributes is as follows: US holidays, promos, weather, price, and category. US holidays has the highest impact on the forecast values. US holidays tend to increase the forecasted value. Category has the lowest impact on the forecast values, and this attribute tends to decrease the forecast value.

Train a new predictor with the new Forecast API
In this section, we walk through how to train a new predictor using the newly launched forecasting API through the console. To use the new CreateAutoPredictor API directly, refer to the notebook in our GitHub repo or review Training Predictors.
- On the Forecast console, create a dataset group and upload your historical demand dataset as target time series followed by any related time series or item metadata that you want to use for more accurate forecasting.
- In the navigation pane, under your dataset, choose Predictors.
- Choose Train new predictor.

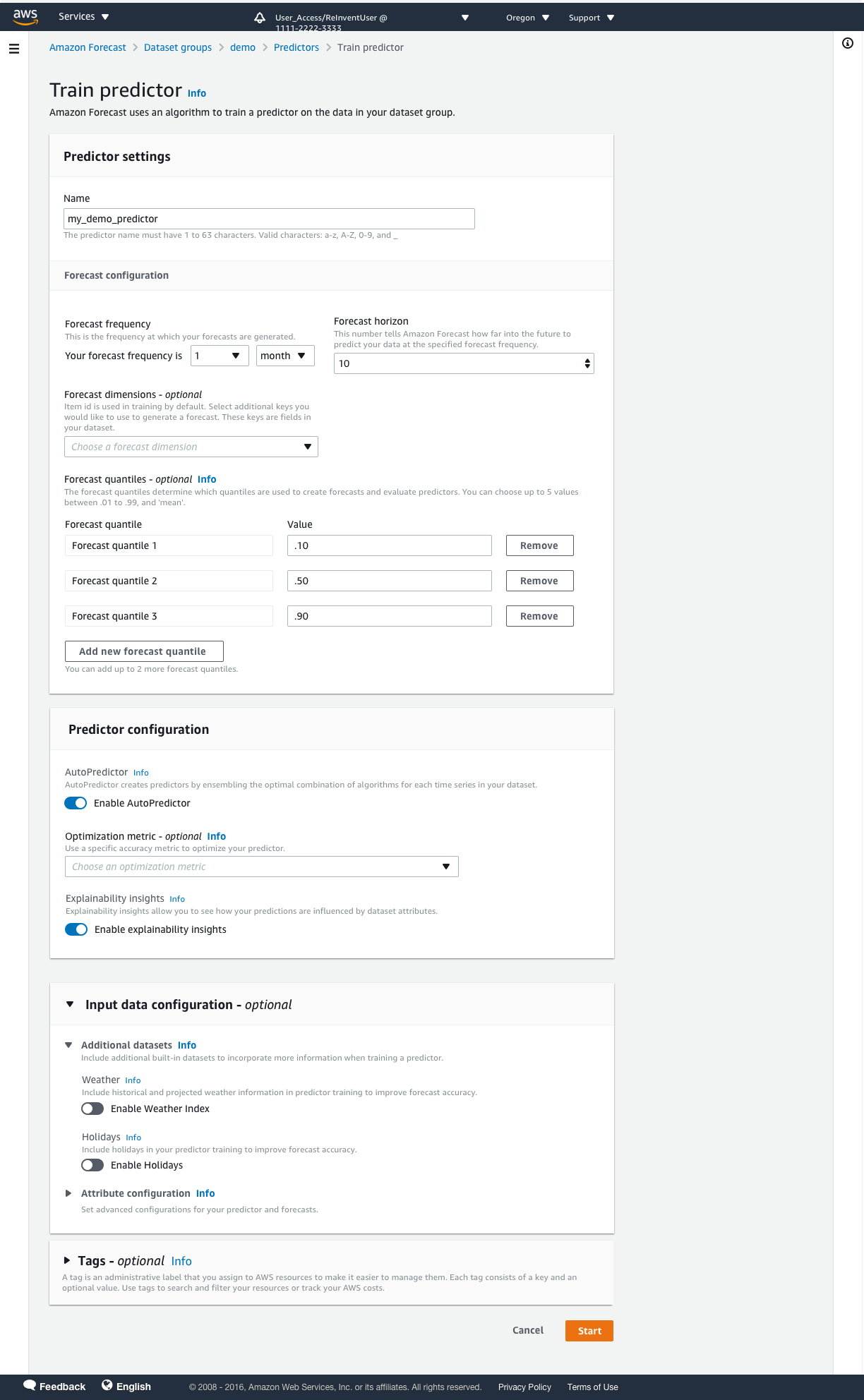
- In the Predictor settings section, enter a name for your predictor, how long in the future you want to forecast with the forecasting frequency, and the number of quantiles you want to forecast for.
- AutoPredictor is enabled by default; no further action is needed from you.
- For Optimization metric, you can choose an optimization metric to optimize AutoPredictor to tune a model for a specific accuracy metric of your choice. We leave this as default for our walkthrough.
- To get the predictor explainability report, select Enable predictor explainability.
- Under the input data configuration, you can add local weather information and national holidays for more accurate demand forecasts.
- In the Attribute configuration section, you can choose filling options for missing values.
- Choose Start to start training your predictor.
- After your predictor is trained, choose your predictor on the Predictors page.

On the predictor’s details page, you can view the overall predictor accuracy metrics and the explainability impact score.

- Now that your model is trained, choose Forecasts in the navigation pane.
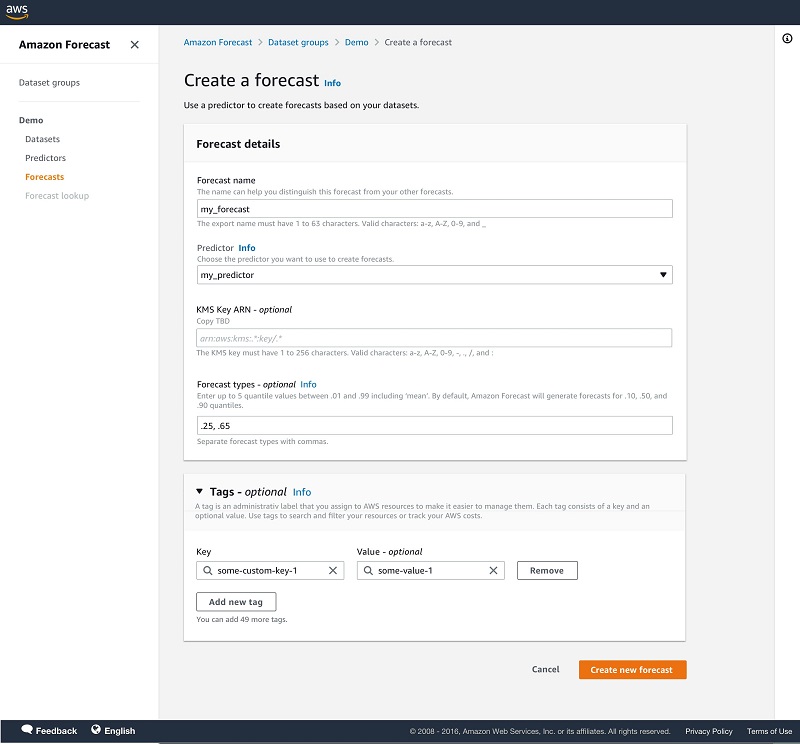
- Choose Create a forecast.
- For Predictor, choose your trained predictor to create a forecast.
Retrain your predictor with new data
We now walk through how to use the Forecast console to retrain your predictor when you have new data for the same forecasting problem. You can also follow the notebook in our GitHub repo to learn how to use the CreateAutoPredictor API for retraining your predictor.
Before you retrain your predictor, you have to re-import your dataset with the latest available historical observations.
- On the Forecast console, under your dataset group in the navigation pane, choose Datasets.
In our example, we only update the target time series data. You can follow the same steps to update the related time series data as well.
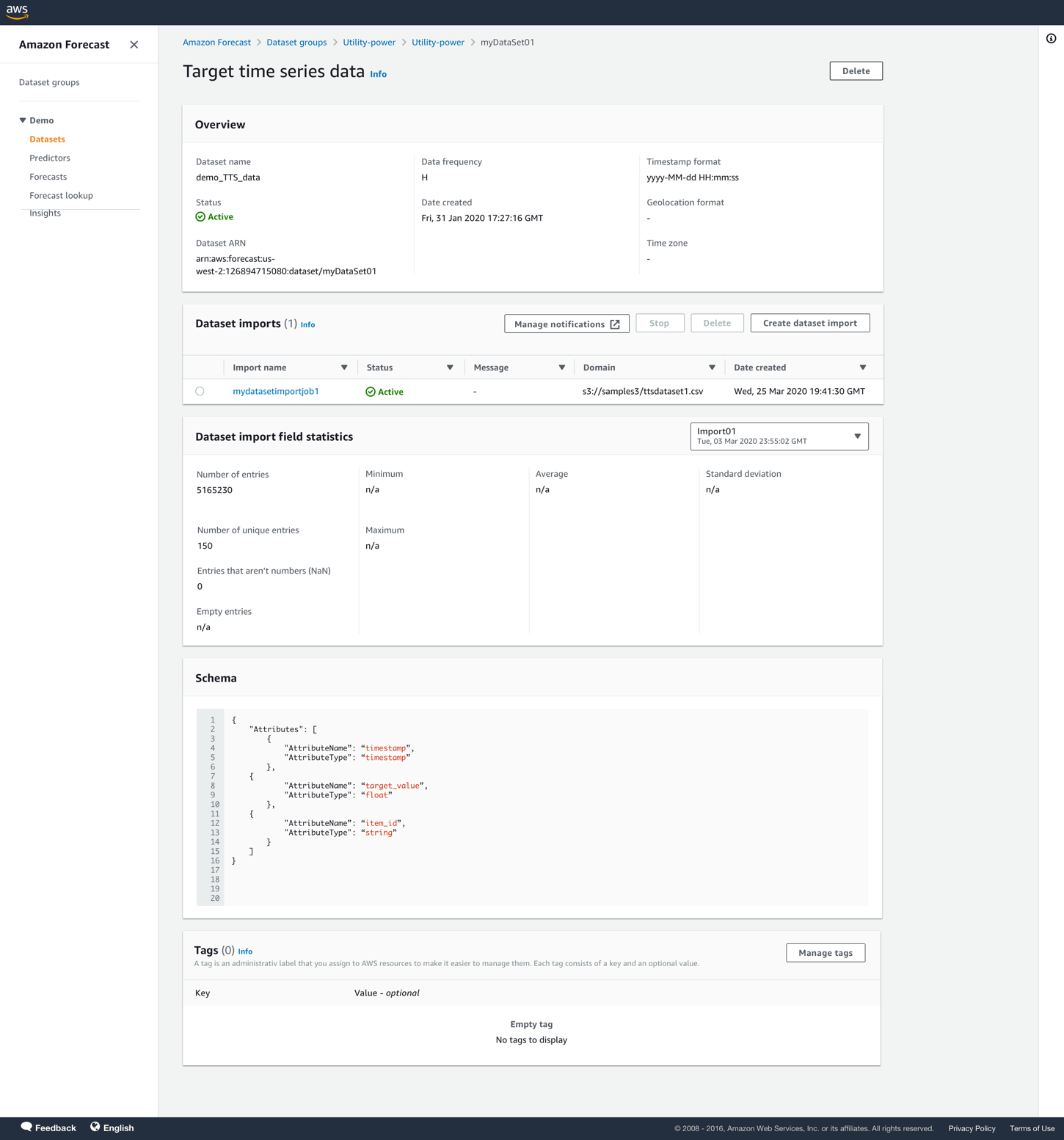
- Choose the dataset name to view the details.

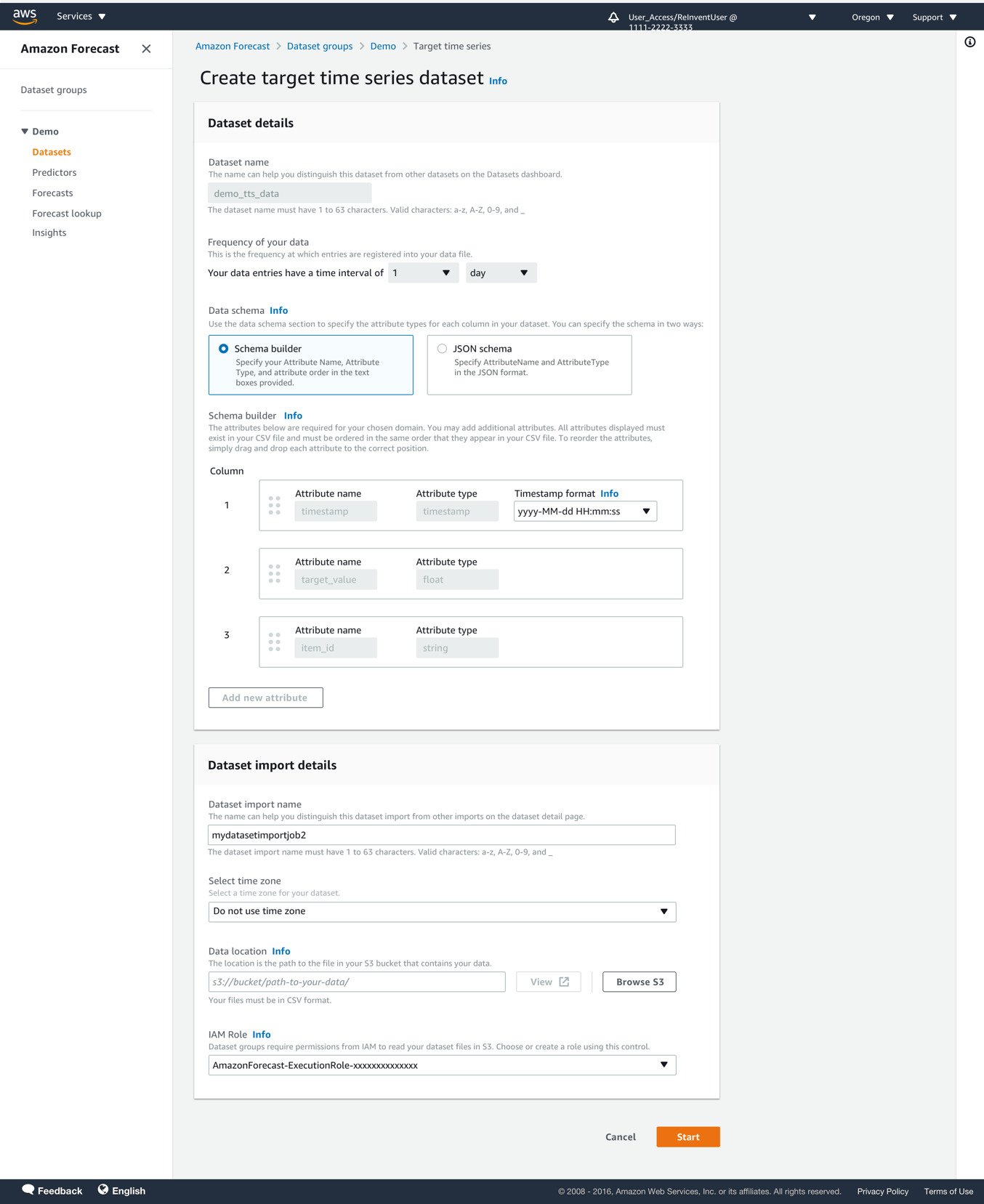
- In the Dataset imports section, choose Create dataset import.
- Provide the Amazon Simple Storage Service (Amazon S3) location of your dataset and complete importing your data.
- After your dataset has been imported, choose Predictors in the navigation pane.

- Select the predictor for which AutoPredictor enabled is True.
Only predictors with AutoPredictor enabled are eligible to be retrained.
- On the Predictor actions menu, choose Retrain.

- Enter a new name for the retrained predictor and choose Retrain predictor.
All the predictor configuration from the source predictor is automatically copied over to the new predictor that you retrain.

You’re redirected to the predictor details page where you can review the predictor settings.

- Now that your model is trained, choose Forecasts in the navigation pane.
- Choose Create a forecast.
- Choose your trained predictor to create a forecast.
Upgrade your existing legacy predictor to AutoPredictor
You can easily move your existing predictors to AutoPredictor to take advantage of more accurate forecasts by using a predictor that selects the best ensemble of algorithms for each item, faster retraining, and predictor explainability. Forecast takes the old predictor as a reference and creates a new AutoPredictor. You can follow the notebook in our GitHub repo to do the same through the CreateAutoPredictor API.
- On the Forecast console, choose a dataset group for which you have previously trained a predictor.
- In the navigation pane, under your dataset, choose Predictors.
An Upgrade link is next to any legacy predictor for which AutoPredictor is False.
- Select your predictor and on the Predictor actions menu, choose Upgrade.
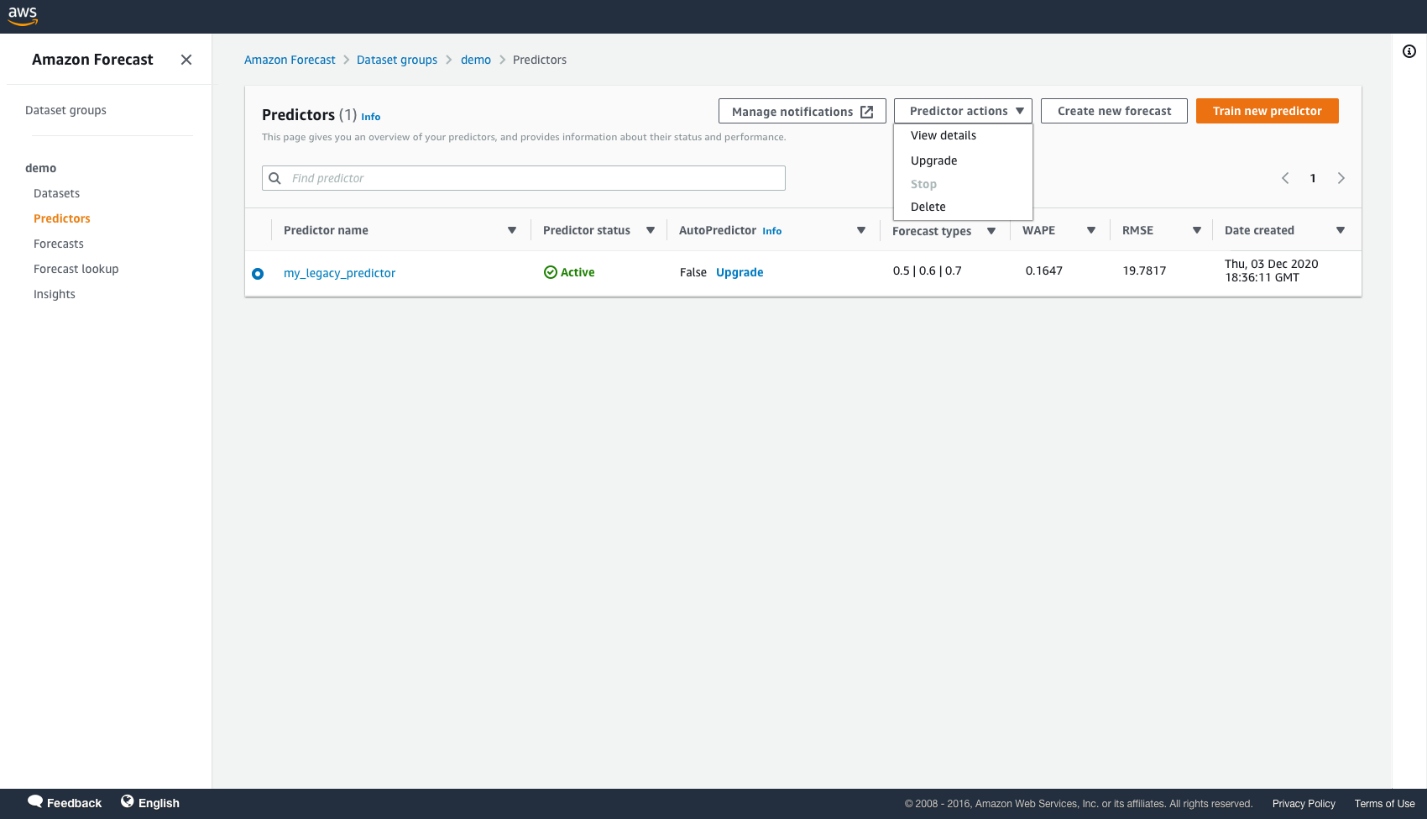
- Enter the name of the new predictor.
All the predictor configurations from the old predictor are automatically copied over to train the new AutoPredictor.
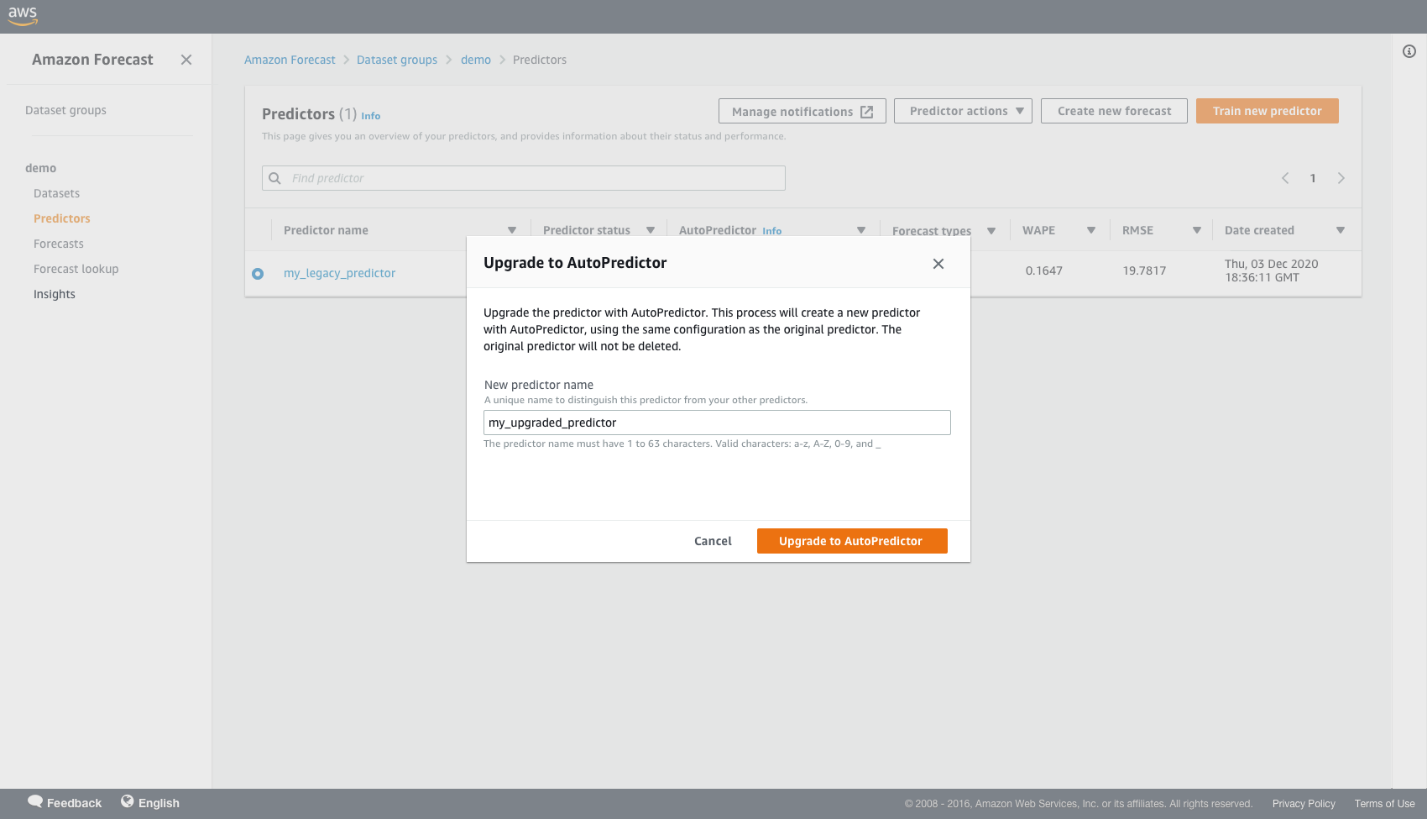
You’re redirected to the predictor details page where you can review the predictor settings.

- Now that your model is trained, choose Forecasts in the navigation pane.
- Choose Create a forecast.
- Choose your trained predictor to create a forecast.
Conclusion
To get more accurate forecasts, faster retraining, and explainability, you can follow the steps mentioned in this post or follow the notebook in our GitHub repo. If you want to upgrade your existing forecasting models to the new CreateAutoPredictor API, you can do so with one click either on through console or as shown in the notebook in our GitHub repo. To learn more, review Training Predictors. We recommend reviewing the pricing for using these new features. All these new capabilities are available in all Regions where Forecast is publicly available. For more information about Region availability, see AWS Regional Services.
About the Authors
 Namita Das is a Sr. Product Manager for Amazon Forecast. Her current focus is to democratize machine learning by building no-code/low-code ML services. On the side, she frequently advises startups and loves training her dog with new tricks.
Namita Das is a Sr. Product Manager for Amazon Forecast. Her current focus is to democratize machine learning by building no-code/low-code ML services. On the side, she frequently advises startups and loves training her dog with new tricks.
 Jitendra Bangani is an Engineering Manager at AWS, leading a growing team of curious and driven engineers for Amazon Forecast. He started his career at Amazon as an intern in 2013; since then he has helped build engaging shopping experiences, hyperscale distributed systems, and autonomous AI services that delight Amazon and AWS customers.
Jitendra Bangani is an Engineering Manager at AWS, leading a growing team of curious and driven engineers for Amazon Forecast. He started his career at Amazon as an intern in 2013; since then he has helped build engaging shopping experiences, hyperscale distributed systems, and autonomous AI services that delight Amazon and AWS customers.
 Hilaf Hasson is a Machine Learning Scientist at AWS, and currently leads the R&D team of scientists working on Amazon Forecast. Before joining AWS, he held multiple faculty positions, including as an Assistant Professor of Mathematics at Stanford University.
Hilaf Hasson is a Machine Learning Scientist at AWS, and currently leads the R&D team of scientists working on Amazon Forecast. Before joining AWS, he held multiple faculty positions, including as an Assistant Professor of Mathematics at Stanford University.
 Adarsh Singh works as a Software Development Engineer in the Amazon Forecast team. In his current role, he focuses on engineering problems and building scalable distributed systems that provide the most value to end users. In his spare time, he enjoys watching anime and playing video games.
Adarsh Singh works as a Software Development Engineer in the Amazon Forecast team. In his current role, he focuses on engineering problems and building scalable distributed systems that provide the most value to end users. In his spare time, he enjoys watching anime and playing video games.
 Chinmay Bapat is a Sr. Software Development Engineer in the Amazon Forecast team. His interests lie in the applications of machine learning and building scalable distributed systems. Outside of work, he enjoys playing board games and cooking.
Chinmay Bapat is a Sr. Software Development Engineer in the Amazon Forecast team. His interests lie in the applications of machine learning and building scalable distributed systems. Outside of work, he enjoys playing board games and cooking.