AWS Machine Learning Blog

Empowering everyone with GenAI to rapidly build, customize, and deploy apps securely: Highlights from the AWS New York Summit
Imagine this—all employees relying on generative artificial intelligence (AI) to get their work done faster, every task becoming less mundane and more innovative, and every application providing a more useful, personal, and engaging experience. To realize this future, organizations need more than a single, powerful large language model (LLM) or chat assistant. They need a […]

Find answers accurately and quickly using Amazon Q Business with the SharePoint Online connector
Amazon Q Business is a fully managed, generative artificial intelligence (AI)-powered assistant that helps enterprises unlock the value of their data and knowledge. With Amazon Q, you can quickly find answers to questions, generate summaries and content, and complete tasks by using the information and expertise stored across your company’s various data sources and enterprise […]

Evaluate conversational AI agents with Amazon Bedrock
As conversational artificial intelligence (AI) agents gain traction across industries, providing reliability and consistency is crucial for delivering seamless and trustworthy user experiences. However, the dynamic and conversational nature of these interactions makes traditional testing and evaluation methods challenging. Conversational AI agents also encompass multiple layers, from Retrieval Augmented Generation (RAG) to function-calling mechanisms that […]

Node problem detection and recovery for AWS Neuron nodes within Amazon EKS clusters
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). This component can quickly detect rare occurrences of issues when Neuron devices fail by tailing monitoring logs. It marks the worker nodes in a defective Neuron device as unhealthy, and promptly replaces them with new worker nodes. By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure.

Mistral Large 2 is now available in Amazon Bedrock
Mistral AI’s Mistral Large 2 (24.07) foundation model (FM) is now generally available in Amazon Bedrock. Mistral Large 2 is the newest version of Mistral Large, and according to Mistral AI offers significant improvements across multilingual capabilities, math, reasoning, coding, and much more. In this post, we discuss the benefits and capabilities of this new […]

LLM experimentation at scale using Amazon SageMaker Pipelines and MLflow
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task. You can customize the model […]
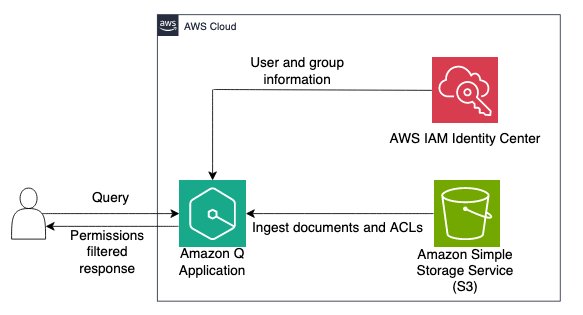
Discover insights from Amazon S3 with Amazon Q S3 connector
Amazon Q is a fully managed, generative artificial intelligence (AI) powered assistant that you can configure to answer questions, provide summaries, generate content, gain insights, and complete tasks based on data in your enterprise. The enterprise data required for these generative-AI powered assistants can reside in varied repositories across your organization. One common repository to […]

Boosting Salesforce Einstein’s code generating model performance with Amazon SageMaker
This post is a joint collaboration between Salesforce and AWS and is being cross-published on both the Salesforce Engineering Blog and the AWS Machine Learning Blog. Salesforce, Inc. is an American cloud-based software company headquartered in San Francisco, California. It provides customer relationship management (CRM) software and applications focused on sales, customer service, marketing automation, […]

Detect and protect sensitive data with Amazon Lex and Amazon CloudWatch Logs
In today’s digital landscape, the protection of personally identifiable information (PII) is not just a regulatory requirement, but a cornerstone of consumer trust and business integrity. Organizations use advanced natural language detection services like Amazon Lex for building conversational interfaces and Amazon CloudWatch for monitoring and analyzing operational data. One risk many organizations face is […]

AWS AI chips deliver high performance and low cost for Llama 3.1 models on AWS
Today, we are excited to announce AWS Trainium and AWS Inferentia support for fine-tuning and inference of the Llama 3.1 models. The Llama 3.1 family of multilingual large language models (LLMs) is a collection of pre-trained and instruction tuned generative models in 8B, 70B, and 405B sizes. In a previous post, we covered how to deploy Llama 3 models on AWS Trainium and Inferentia based instances in Amazon SageMaker JumpStart. In this post, we outline how to get started with fine-tuning and deploying the Llama 3.1 family of models on AWS AI chips, to realize their price-performance benefits.

Use Llama 3.1 405B for synthetic data generation and distillation to fine-tune smaller models
Today, we are excited to announce the availability of the Llama 3.1 405B model on Amazon SageMaker JumpStart, and Amazon Bedrock in preview. The Llama 3.1 models are a collection of state-of-the-art pre-trained and instruct fine-tuned generative artificial intelligence (AI) models in 8B, 70B, and 405B sizes. Amazon SageMaker JumpStart is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. Amazon Bedrock offers a straightforward way to build and scale generative AI applications with Meta Llama models, using a single API.