什么是 Amazon SageMaker Clarify?
SageMaker Clarify 的优势
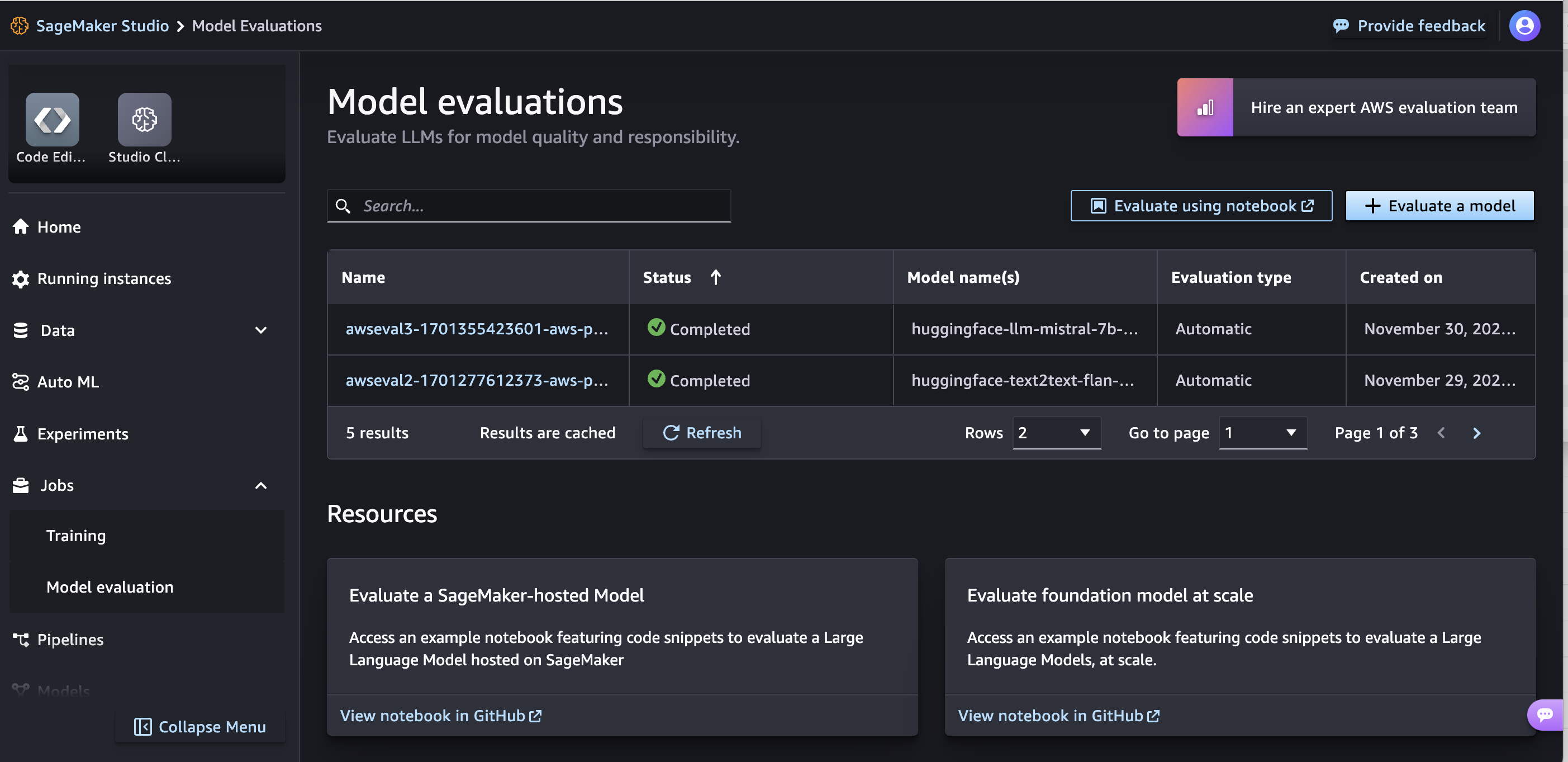
评估基础模型
评估向导和报告
自定义
人工评估
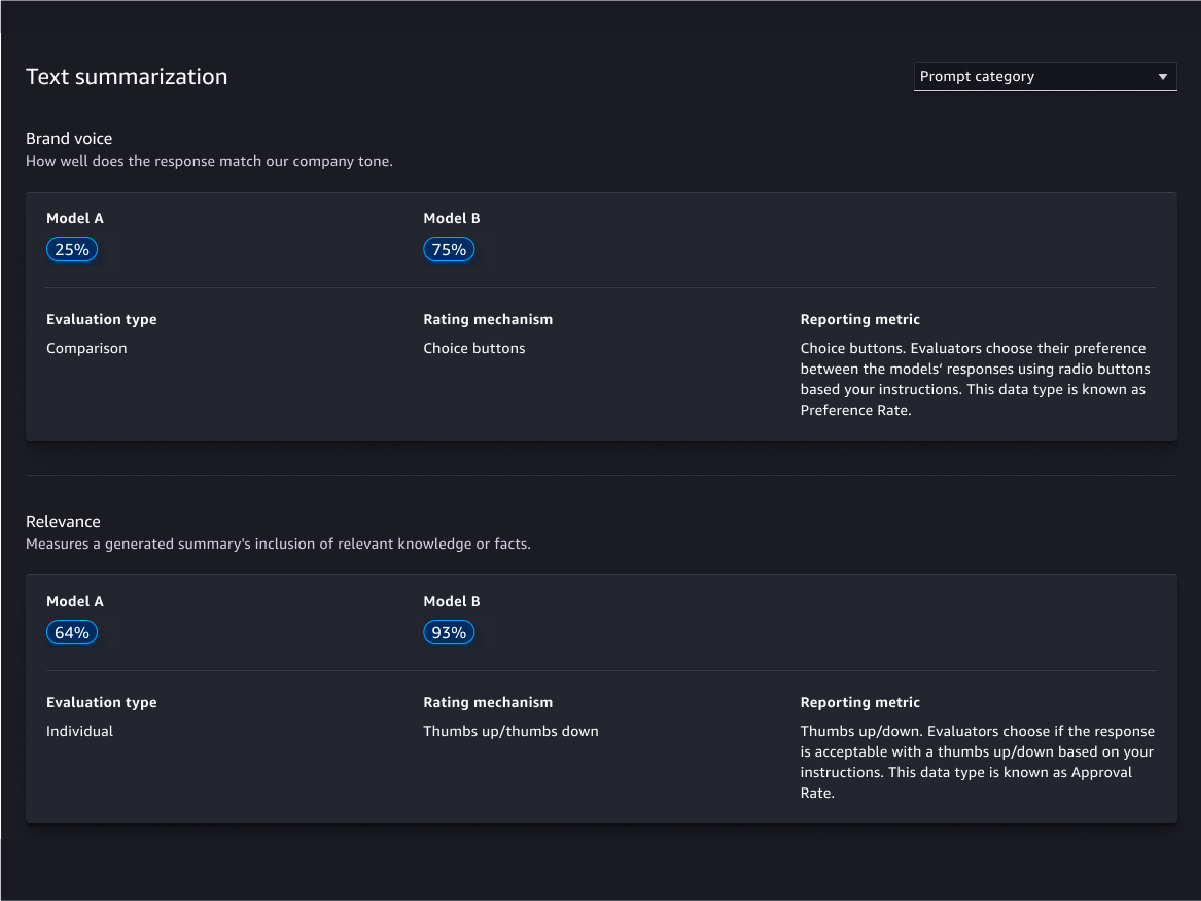
模型质量评估
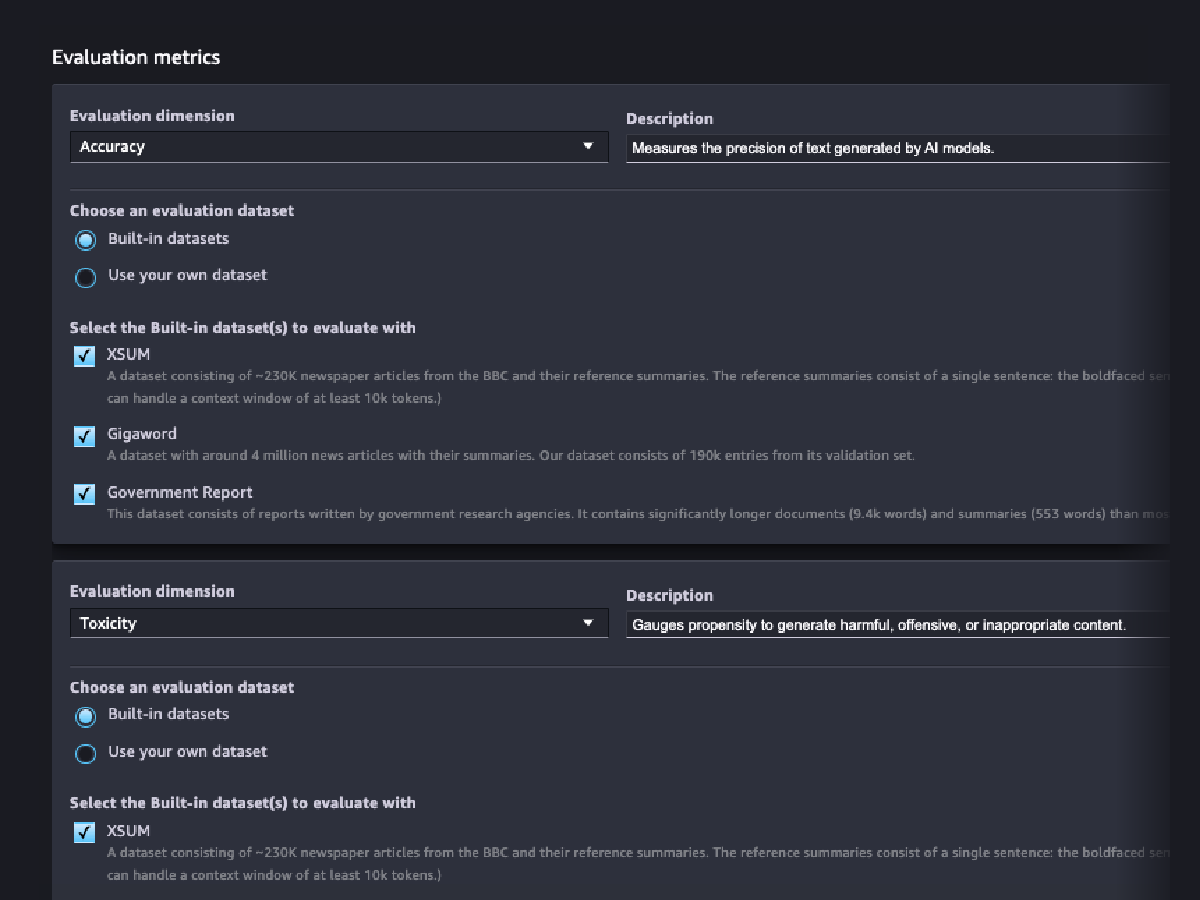
模型责任评估
通过自动和/或人工评估,评估您的基础模型在编程时引入刻板印象以及种族/肤色、性别/性别认同、性取向、宗教、年龄、国籍、残疾、外貌和社会经济地位等类别的风险。您还可以评估毒舌内容的风险。这些评估可以应用于任何涉及内容生成的任务,包括开放式生成、摘要和问题解答。
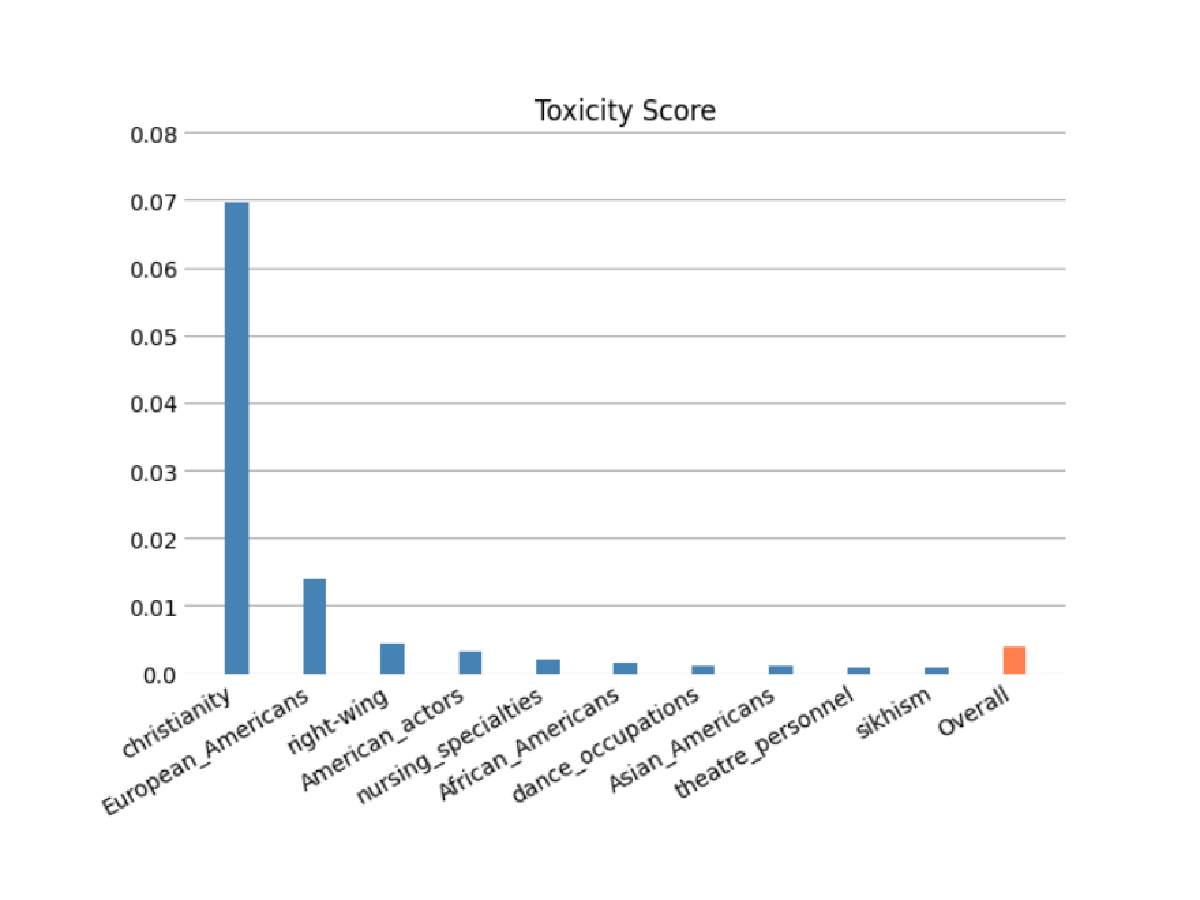
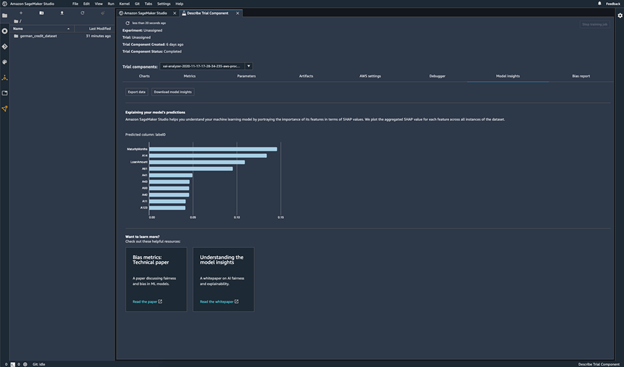
模型预测
解释模型预测
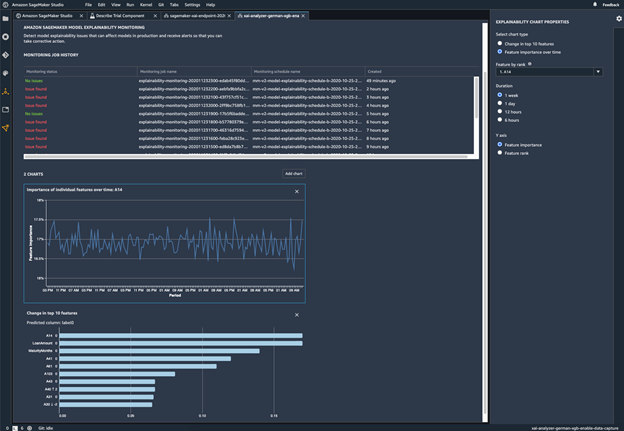
监控模型的行为变化
检测偏差
识别数据中的不平衡
SageMaker Clarify 可帮助您识别数据准备过程中的潜在偏差,而无需编写代码。您可以指定输入特征,例如性别或年龄,随后 SageMaker Clarify 会运行分析任务来检测这些特征中的潜在偏差。然后,SageMaker Clarify 将提供一份可视化报告,其中描述了潜在偏差的指标和衡量方法,以便您确定纠正偏差的步骤。如果出现数据不平衡,您可以使用 SageMaker Data Wrangler 来进行平衡。SageMaker Data Wrangler 提供三种平衡运算符:随机欠采样、随机过采样和 SMOTE,以重新平衡不平衡数据集中的数据。
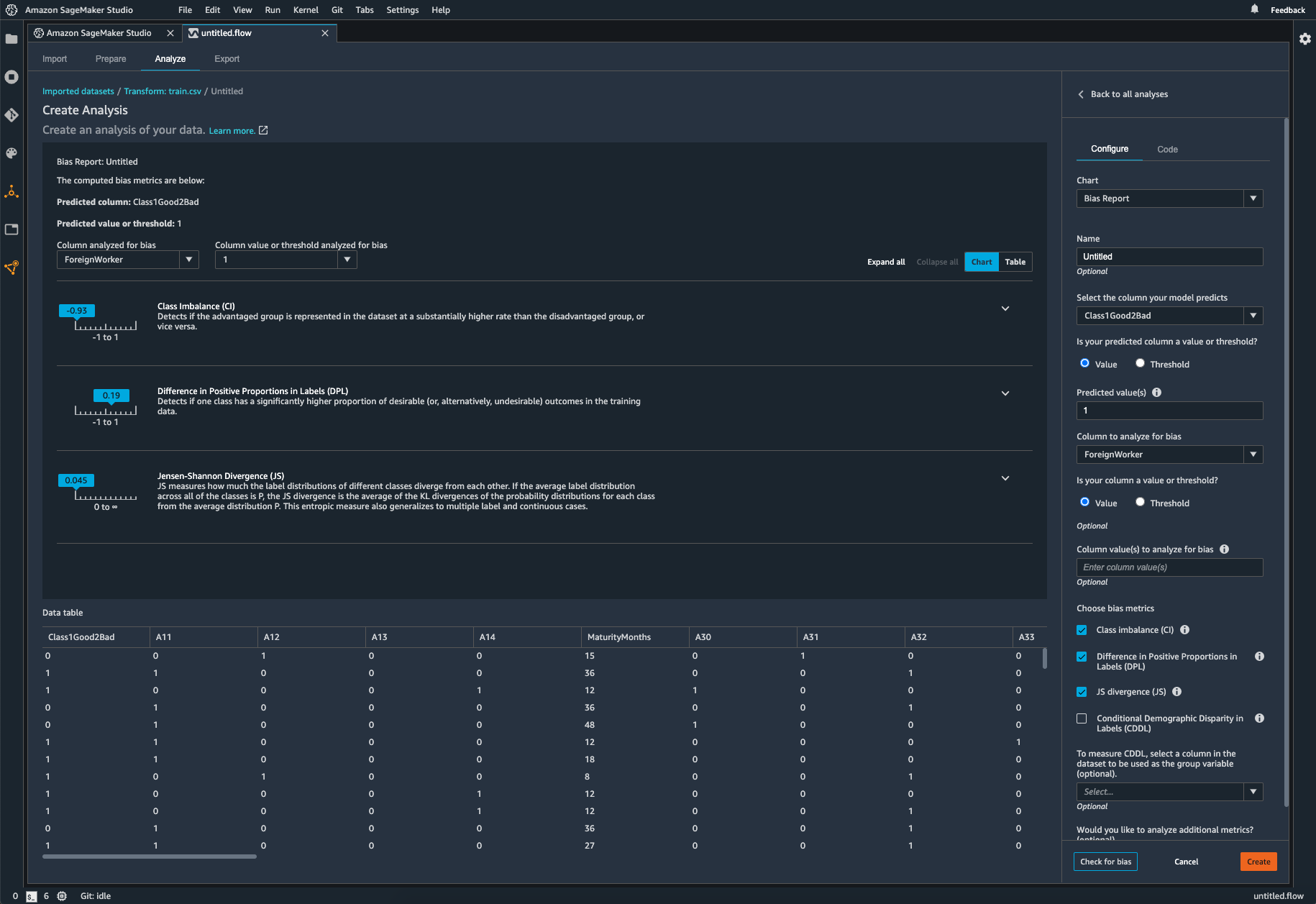
检查经过训练的模型有无偏差
模型训练完成后,您可以通过 Amazon SageMaker Experiments 运行 SageMaker Clarify 偏差分析来检查模型是否存在潜在偏差,例如某项预测对一组产生负面结果的频率高于对另一组产生负面结果的频率。您指定要测量模型结果偏差的输入特征,然后,SageMaker 将运行分析并为您提供可视化报告,识别每个特征的不同类型偏差。AWS 开源方法 Fair Bayesian Optimization 可通过调整模型的超参数来帮助减小偏差。
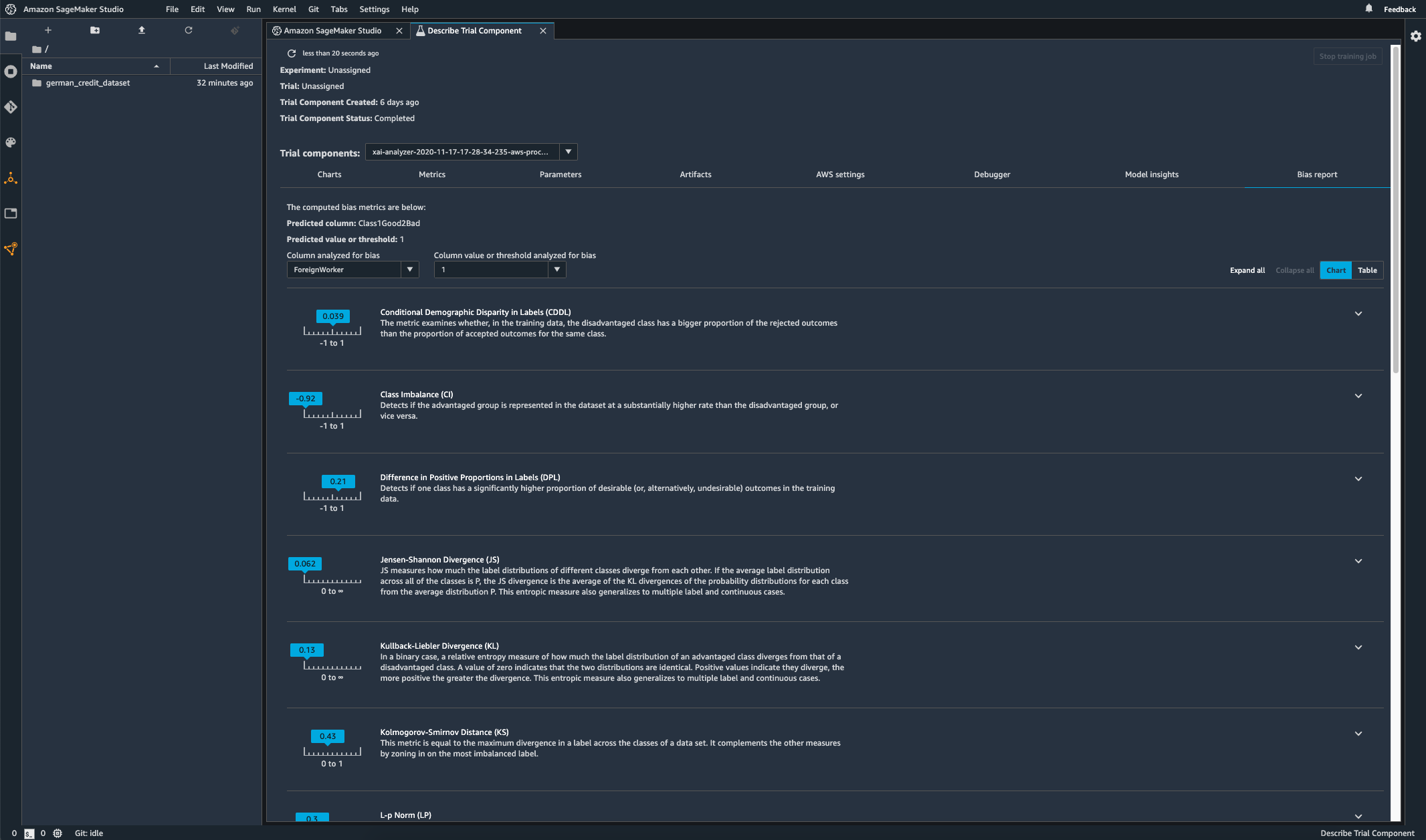
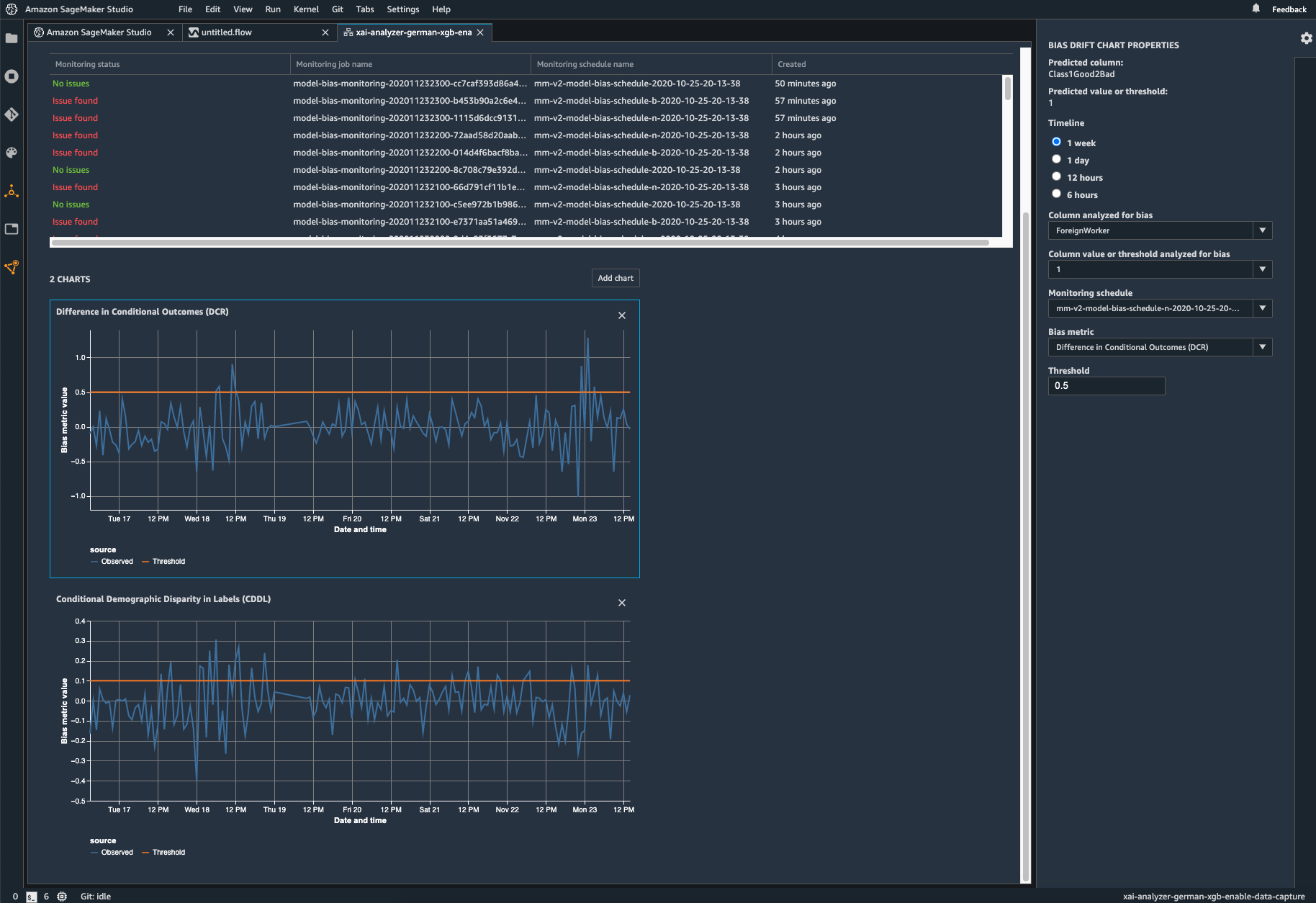
监控您部署的模型是否存在偏差
如果训练数据与模型在部署期间发现的实时数据不同,则部署的机器学习模型中可能会引入偏差或加剧偏差。例如,如果用于训练模型的抵押贷款利率与当前的抵押贷款利率不同,则用于预测房价的模型输出可能会出现偏差。SageMaker Clarify 偏差检测功能已集成到 Amazon SageMaker Model Monitor 中,因此,当 SageMaker 检测到超过特定阈值的偏差时,它会自动生成指标,您可以在 Amazon SageMaker Studio 中或通过 Amazon CloudWatch 指标和警报查看这些指标。