为什么选择 SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler 将表格、图像和文本数据的数据准备时间从几周缩短到几分钟。借助 SageMaker Data Wrangler,您可以通过可视化自然语言界面简化数据准备和特征工程。使用 SQL 和 300 多个内置的转换快速选择、导入和转换数据,无需编写代码。生成直观的数据质量报告,以检测不同数据类型的异常,并估算模型性能。扩展以处理数 PB 的数据。
SageMaker Data Wrangler 的优势
工作原理
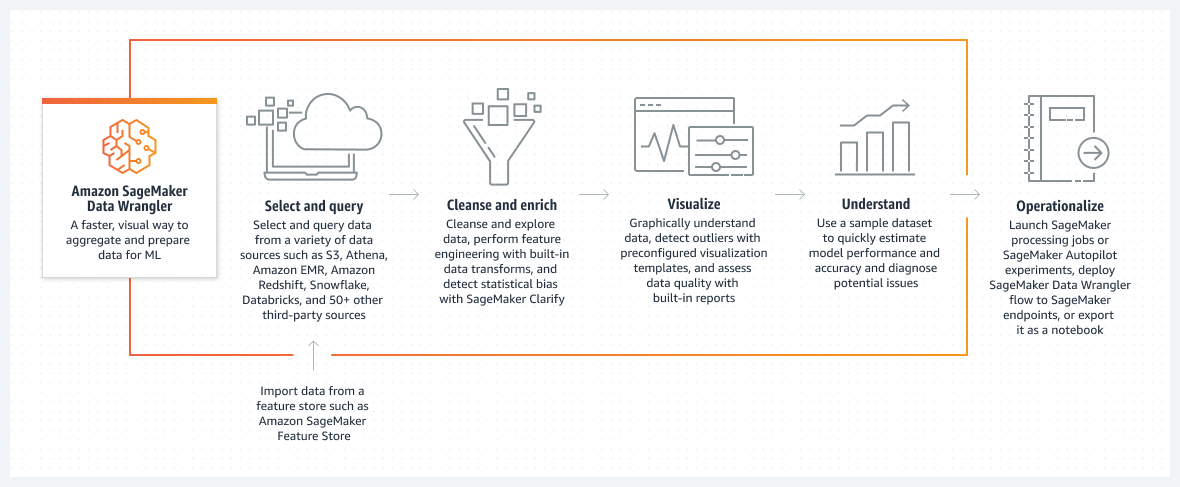
工作原理

标题 1:Amazon SageMaker Data Wrangler
描述文本:为 ML 聚合和准备数据的更快、更直观的方式
标题 2:选择和查询
描述文本:从各种数据来源中选择和查询数据,例如 Amazon S3、Athena、Amazon EMR、Amazon Redshift、Snowflake、Databricks 和 50 多个其他第三方来源
子描述:从 Amazon SageMaker Feature Store 等特征存储导入数据
标题 3:清理和扩充
描述文本:清理和探索数据,使用内置数据转换进行特征工程,并使用 SageMaker Clarify 检测统计偏差
标题 4:可视化
描述文本:以图形方式理解数据,使用预配置的可视化模板检测异常值,并使用内置报告评估数据质量
标题 5:理解
描述文本:使用示例数据集快速评估模型性能和准确性并诊断潜在问题
标题 6:操作化
描述文本:启动 SageMaker 处理作业或 SageMaker Autopilot 实验,将 SageMaker Data Wrangler 流部署到 SageMaker 端点,或将其导出为笔记本。
更快地访问、选择和查询数据
借助 SageMaker Data Wrangler,您可以快速访问来自 Amazon 服务(例如 S3、Athena、Redshift 和 50 多个第三方来源)的表格、文本和图像数据。您可以使用可视化查询生成器选择数据,编写 SQL 查询,或直接以各种格式(例如 CSV 和 Parquet)导入数据。

生成数据洞察并理解数据质量
SageMaker Data Wrangler 提供数据质量和洞察报告,自动验证数据质量(如缺失值、重复行和数据类型)并帮助检测数据中的异常情况(如异常值、类不平衡和数据泄漏)。一旦可以有效地验证数据质量,就可以快速应用领域知识处理数据集,进行 ML 模型训练。

通过可视化理解您的数据
SageMaker Data Wrangler 通过强大的内置可视化模板(例如直方图、散点图、特征重要性和相关性)帮助您了解数据。使用直观的数据质量报告加速数据探索,这些报告可检测数据类型中的异常并提供改进数据质量的建议。

更高效地转换数据
SageMaker Data Wrangler 提供 300 多种预构建的 PySpark 转换和自然语言界面,无需编码即可准备表格、时间序列、文本和图像数据。涵盖向量化文本、特征化日期时间、编码、平衡数据或图像增强等常见使用案例。您还可以在 PySpark、SQL 和 Pandas 中编写自定义转换,或使用自然语言界面生成代码。内置的代码片段库可以简化编写自定义转换的过程。

了解数据的预测能力
SageMaker Data Wrangler 提供快速模型分析来估计数据的预测能力。您可以获得估计的模型准确率、特征重要性和混淆矩阵,以帮助您在训练模型之前验证数据质量。

自动化和部署 ML 数据准备工作流程
通过 SageMaker Data Wrangler,您无需编写 PySpark 代码或启动集群即可进行扩展以准备 PB 级数据。直接从用户界面启动处理作业,或通过将数据导出到 SageMaker Feature Store 或与 SageMaker Pipelines 集成,将数据准备集成到 ML 工作流中。您还可以将数据流导出为 Jupyter Notebook 或 Python 脚本,以便以编程方式复制数据准备步骤。

客户
“在 INVISTA,我们以转型为动力,并致力于开发可让全球客户从中受益的产品和技术。我们将机器学习视为改善客户体验的一种方式。但是,对于包含数亿行的数据集,我们需要一个解决方案来帮助我们准备数据,并大规模地开发、部署和管理机器学习模型。借助 Amazon SageMaker Data Wrangler,我们现在可以以交互方式有效地选择、清理、探索和理解我们的数据,使我们的数据科学团队能够创建特征工程管道,这些管道可以毫不费力地扩展到跨越数亿行的数据集。有了 Amazon SageMaker Data Wrangler,我们可以更快地执行机器学习工作流程。”
Caleb Wilkinson,INVISTA 前首席数据科学家
“通过使用机器学习,3M 正在改进久经考验的产品,比如砂纸,并推动其他领域的创新,包括医疗保健。随着我们计划将机器学习扩展到 3M 的更多领域,我们看到数据和模型的数量正在快速增长 – 每年翻一番。我们热衷于新的 SageMaker 功能,因为它们将帮助我们实现扩展。Amazon SageMaker Data Wrangler 使准备模型训练数据变得更加容易,并且 Amazon SageMaker Feature Store 消除了重复创建相同模型功能的需要。最后,Amazon SageMaker Pipelines 将帮助我们自动准备数据、构建模型并将模型部署到端到端工作流程中,以便缩短模型的上市时间。我们的研究人员期待着利用 3M 的新科学速度。”
David Frazee,3M 公司系统研究实验室前技术主管
“Amazon SageMaker Data Wrangler 使我们能够利用丰富的转换工具集来满足数据准备需求,这些转换工具可加快将新产品推向市场所需的机器学习数据准备过程。反过来,我们的客户可以从我们扩展部署模型的速度中受益,这使我们能够在几天而不是几个月的时间内提供可衡量、可持续的结果,以满足客户的需求。”
Frank Farrall,Deloitte AI 生态系统和平台首席负责人
“作为 AWS 高级咨询合作伙伴,我们的工程团队正在与 AWS 紧密合作,以构建创新的解决方案来帮助我们的客户不断提高其运营效率。机器学习是我们创新解决方案的核心,但是我们的数据准备工作流程涉及复杂的数据准备技术,因此在生产环境中投入使用需要花费大量的时间。借助 Amazon SageMaker Data Wrangler,我们的数据科学家可以完成数据准备工作流程的各个步骤,包括数据选择、清理、探索和可视化,这有助于我们加速数据准备过程并轻松准备用于机器学习的数据。有了 Amazon SageMaker Data Wrangler,我们可以更快地为机器学习准备数据。”
Shigekazu Ohmoto,NRI Japan 高级企业常务董事
“随着我们在人口健康管理市场中持续扩展到更多健康支付机构、提供商、药品福利管理者和其他卫生机构,我们需要一种自动完成端到端流程的解决方案,作为向机器学习模型提供信息的数据来源,包括索赔数据、参加数据和药店数据。使用 Amazon SageMaker Data Wrangler,我们现在能够使用一组更容易验证和重复利用的工作流程缩短为机器学习聚合和准备数据所用的时间。这极大地提高了我们模型的交付速度和质量,提升了数据科学家的效率,并将数据准备时间缩短了接近 50%。此外,SageMaker Data Wrangler 还帮助我们节省了多重机器学习迭代并显著减少了 GPU 时间,为客户加快了整个端到端流程的速度,因为我们现在能够构建具有数千种特点的数据集市,包括药店、诊断代码、ER 访视、住院以及人口统计学和其他社会决定因素。通过 SageMaker Data Wrangler,我们可以极其高效地转换数据以构建训练数据集,在运行机器学习模型之前根据数据集生成数据见解,并为大规模推理/预测准备真实数据。”
Lucas Merrow,Equilibrium Point IoT 首席执行官