Automatisches Erstellen eines Machine Learning-Modells
mit Amazon SageMaker Autopilot
Amazon SageMaker ist ein vollständig verwalteter Dienst, der jedem Entwickler und Daten-Wissenschaftler die Möglichkeit bietet, schnell Modelle für Machine Learning (ML) zu erstellen, zu trainieren und bereitzustellen.
In diesem Tutorial erstellen Sie Machine Learning-Modelle automatisch, ohne eine einzige Codezeile zu schreiben! Sie verwenden Amazon SageMaker Autopilot, eine AutoML-Funktion, die automatisch die besten Machine Learning-Modelle für Klassifizierung und Regression erstellt und gleichzeitig volle Kontrolle und Transparenz ermöglicht.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen eines AWS-Kontos
- Einrichten von Amazon SageMaker Studio für den Zugriff auf Amazon SageMaker Autopilot
- Herunterladen eines öffentlichen Datensatzes mithilfe von Amazon SageMaker Studio
- Erstellen eines Trainingsexperiments mit Amazon SageMaker Autopilot
- Erkunden der verschiedenen Phasen des Trainingsexperiments
- Identifizieren und Bereitstellen des Modells mit der besten Leistung aus dem Trainingsexperiment
- Erstellen von Prognosen mit Ihrem bereitgestellten Modell
Für dieses Tutorial übernehmen Sie die Rolle eines Entwicklers, der für eine Bank tätig ist. Sie wurden gebeten, ein Machine-Learning-Modell zu entwickeln, mit dem vorhergesagt werden kann, ob ein Kunde ein Einlagenzertifikat zeichnen wird. Zum Trainieren des Modells wird der Marketingdatensatz verwendet, der Informationen zur Demographie des Kunden, seine Reaktionen auf Marketinginitiativen und externe Faktoren enthält.
| Über dieses Tutorial | |
|---|---|
| Zeit | 10 Minuten |
| Kosten | Weniger als 10 USD |
| Anwendungsfall | Machine Learning |
| Produkte | Amazon SageMaker |
| Zielgruppe | Entwickler |
| Level | Einsteiger |
| Letzte Aktualisierung | 12. Mai 2020 |
Schritt 1: AWS-Konto erstellen
Die Kosten für diesen Workshop betragen weniger als 10 USD. Weitere Informationen finden Sie unter Amazon SageMaker Studio – Preise.
Sie haben bereits ein Konto? Anmelden
Schritt 2: Einrichten von Amazon SageMaker Studio
Schließen Sie die folgenden Schritte ab, um Amazon SageMaker Studio für den Zugriff auf Amazon SageMaker Autopilot einzurichten.
Hinweis: Weitere Informationen finden Sie unter Erste Schritte mit Amazon SageMaker Studio in der Amazon SageMaker-Dokumentation.
a. Melden Sie sich bei der Amazon SageMaker-Konsole an.
Hinweis: Wählen Sie oben rechts unbedingt eine AWS-Region aus, in der Amazon SageMaker Studio verfügbar ist. Eine Liste der Regionen finden Sie im Thema zum Einrichten von Amazon SageMaker Studio.


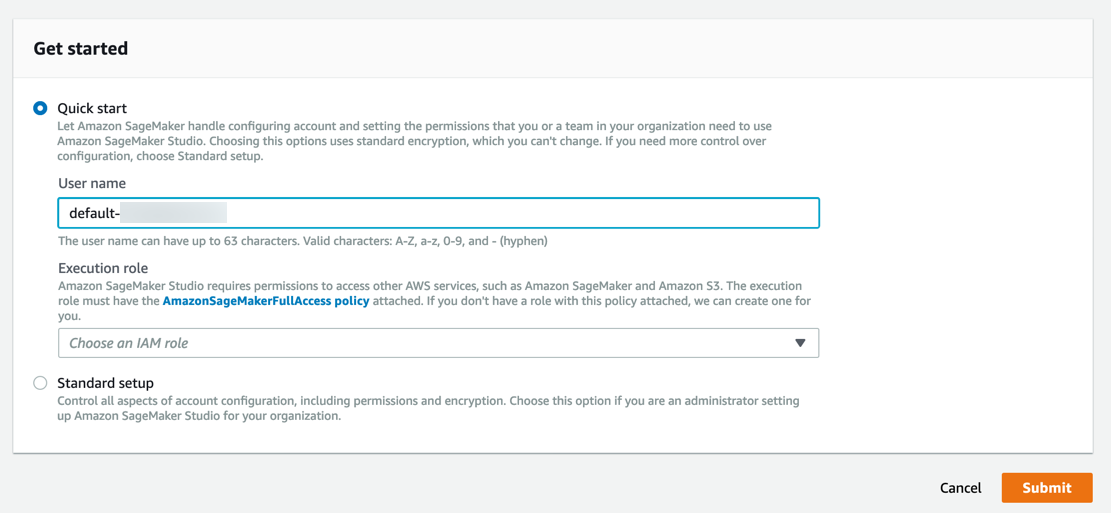
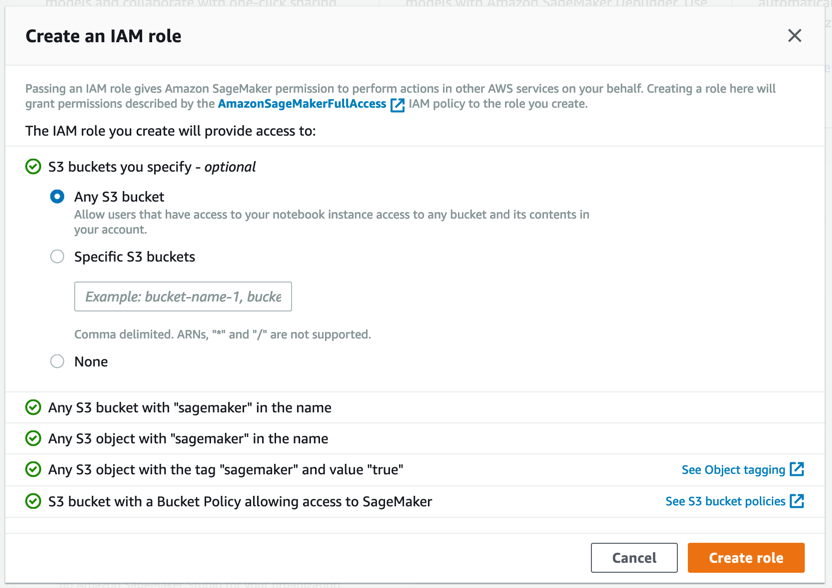
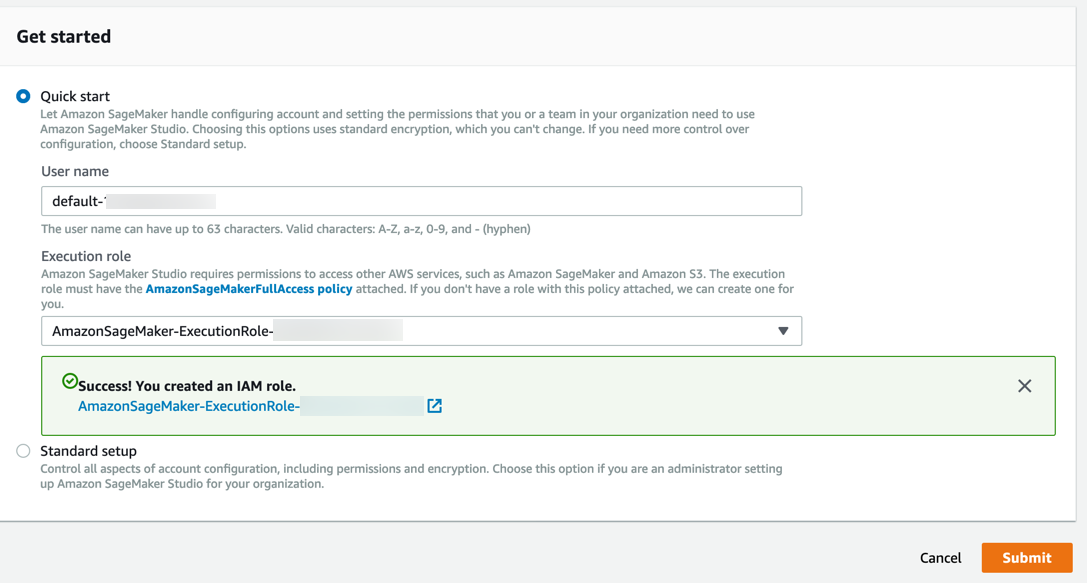
Amazon SageMaker erstellt eine Rolle mit den erforderlichen Berechtigungen und weist sie Ihrer Instance zu.
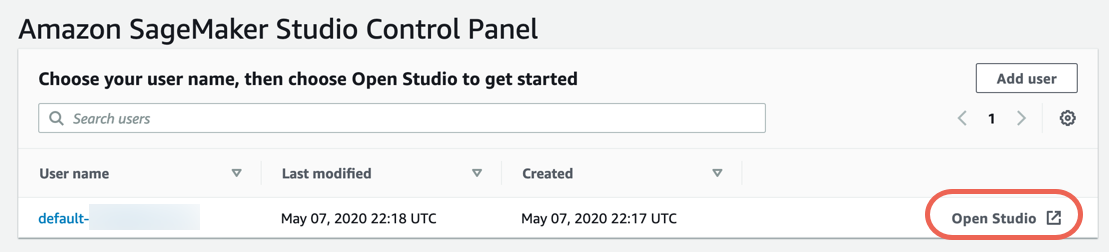
Schritt 3: Herunterladen des Datensatzes
Schließen Sie die folgenden Schritte ab, um den Datensatz herunterzuladen und zu erkunden.
Hinweis: Weitere Informationen finden Sie unter Amazon SageMaker Studio-Tour in der Amazon SageMaker-Dokumentation.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Kopieren Sie den folgenden Code in eine neue Codezelle und wählen Sie Run aus.
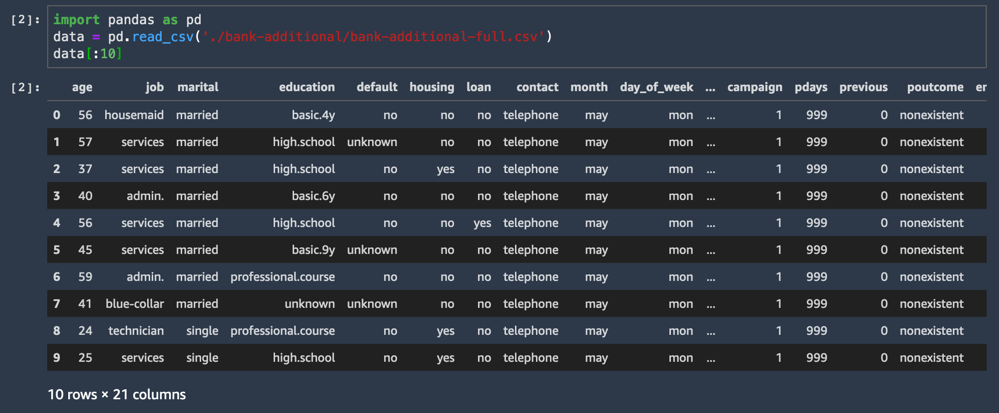
Der CSV-Datensatz wird geladen und die ersten zehn Zeilen werden angezeigt.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]Eine der Datensatzspalten hat den Namen y und stellt die Bezeichnung für die einzelnen Beispiele dar: Hat dieser Kunde das Angebot akzeptiert oder nicht?
In diesem Schritt würden Daten-Wissenschaftler mit dem Erforschen der Daten, dem Erstellen neuer Funktionen usw. beginnen. Mit Amazon SageMaker Autopilot sind diese zusätzlichen Schritte nicht erforderlich. Sie laden Tabellendaten einfach in eine Datei mit durch Kommata getrennten Werten hoch (z. B. aus einem Spreadsheet oder einer Datenbank) und wählen die Zielspalte für die Prognose aus. Autopilot erstellt dann ein Prognosemodell.
d. Kopieren Sie den folgenden Code in eine neue Codezelle und wählen Sie Run aus.
In diesem Schritt wird der CSV-Datensatz in einen Amazon S3-Bucket hochgeladen. Sie müssen keinen Amazon S3-Bucket erstellen; Amazon SageMaker erstellt automatisch einen Standard-Bucket in Ihrem Konto, wenn Sie die Daten hochladen.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
Fertig! Die Codeausgabe zeigt den URI des S3-Buckets wie im folgenden Beispiel an:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvNotieren Sie sich den S3-URI, der in Ihrem eigenen Notebook angegeben wird. Sie benötigen ihn im nächsten Schritt.

Schritt 4: Erstellen eines SageMaker Autopilot-Experiments
Da Sie Ihren Datensatz jetzt heruntergeladen und in Amazon S3 bereitgestellt haben, können Sie ein Amazon SageMaker Autopilot-Experiment erstellen. Eine Experiment ist eine Sammlung aus Verarbeitungs- und Trainingsaufgaben für ein- und dasselbe Machine Learning-Projekt.
Schließen Sie die folgenden Schritte ab, um ein neues Experiment zu erstellen.
Hinweis: Weitere Informationen finden Sie unter Erstellen eines Amazon SageMaker Autopilot-Experiments in SageMaker Studio in der Amazon SageMaker-Dokumentation.
a. Wählen Sie im linken Navigationsbereich von Amazon SageMaker Studio die Option Experiments (Flaschen- bzw. Kolbensymbol) und dann Create Experiment aus.
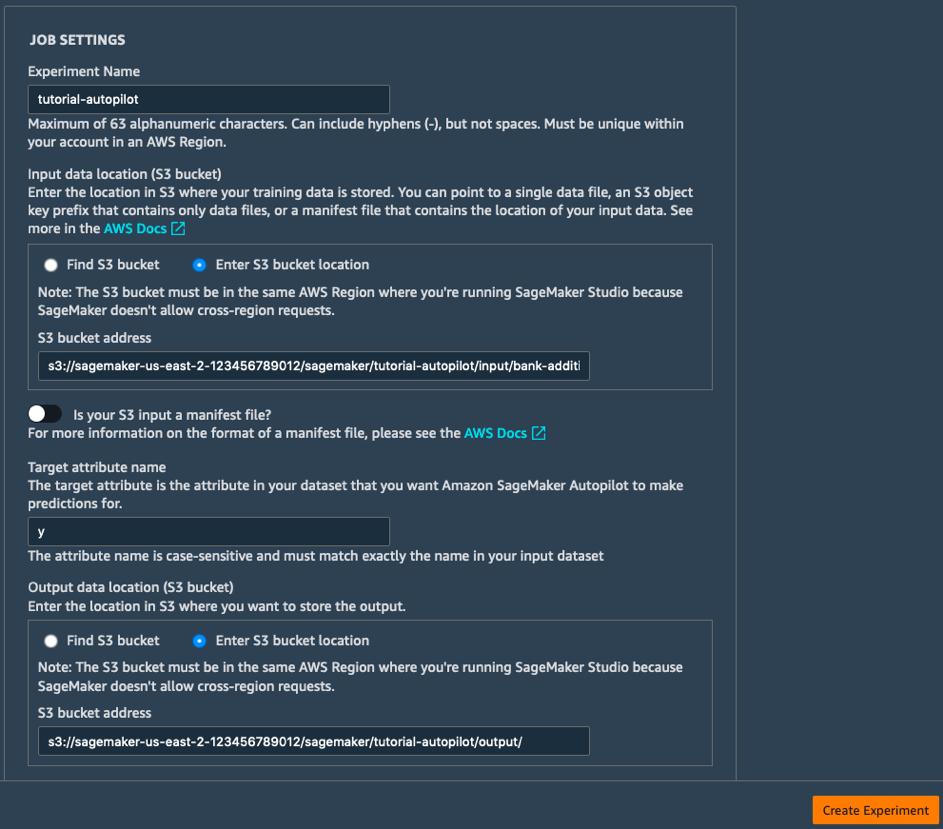
b. Füllen Sie die Job Settings-Felder wie folgt aus:
- Experiment Name: tutorial-autopilot
- S3 location of input data: S3-URI, den Sie sich weiter oben notiert haben
(z. B. s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Target attribute name: y
- S3 location for output data: s3://sagemaker-us-east-2-[KONTONUMMER]/sagemaker/tutorial-autopilot/output
(Verwenden Sie für [KONTONUMMER] Ihre eigene Kontonummer.)
c. Behalten Sie sonst alle Standardeinstellungen bei und wählen Sie Create Experiment aus.
Erfolg! Auf diese Weise wird das Amazon SageMaker Autopilot-Experiment gestartet! Der Prozess generiert ein Modell und Statistiken, die Sie in Echtzeit anzeigen können, während das Experiment ausgeführt wird. Nach Abschluss des Experiments können Sie die Tests anzeigen, sie nach objektiven Metriken sortieren und das Modell per Rechtsklick für die Verwendung in anderen Umgebungen bereitstellen.
Schritt 5: Erkunden der SageMaker Autopilot-Experimentphasen
Während Ihr Experiment ausgeführt wird, können Sie die unterschiedlichen Phasen des SageMaker Autopilot-Experiments erkunden und zugehörige Informationen erhalten.
In diesem Abschnitt werden weitere Details zu den SageMaker Autopilot-Experimentphasen bereitgestellt:
- Datenanalyse
- Funktions-Engineering
- Modelloptimierung
Hinweis: Weitere Informationen finden Sie in der SageMaker Autopilot-Notebook-Ausgabe.
Datenanalyse
In der Phase der Datenanalyse wird der zu lösende Problemtyp identifiziert (lineare Regression, binäre Klassifizierung, Multiklassen-Klassifizierung). Dann werden zehn Kandidatenpipelines generiert. Eine Pipeline kombiniert einen Datenverarbeitungsschritt (Verarbeitung fehlender Werte, Entwickeln neuer Funktionen usw.) mithilfe eines ML-Algorithmus, der zum Problemtyp passt, mit einem Modelltrainingsschritt. Nach Abschluss dieses Schrittes wird die Aufgabe zum Funktions-Engineering weitergegeben.
Funktions-Engineering
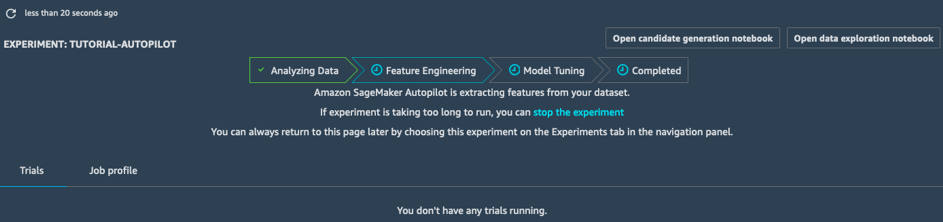
In der Phase des Funktions-Engineerings erstellt das Experiment Trainings- und Validierungsdatensätze für die einzelnen Kandidatenpipelines und speichert alle Artefakte in Ihrem S3-Bucket. In der Funktions-Engineering-Phase können Sie zwei automatisch generierte Notebooks öffnen und anzeigen:
- Das Data Exploration Notebook enthält Informationen und Statistiken zum Datensatz.
- Das Candidate Generation Notebook enthält die Definitionen der zehn Pipelines. Hierbei handelt es sich um ein ausführbares Notebook: Sie können genau reproduzieren, was die AutoPilot-Aufgabe macht, nachvollziehen, wie die unterschiedlichen Modelle erstellt werden, und diese auf Wunsch sogar optimieren.
Mithilfe dieser zwei Notebooks können Sie detailliert nachvollziehen, wie Daten vorverarbeitet und wie Modelle erstellt und optimiert werden. Diese Transparenz ist eine wichtige Funktion von Amazon SageMaker Autopilot.
Modelloptimierung
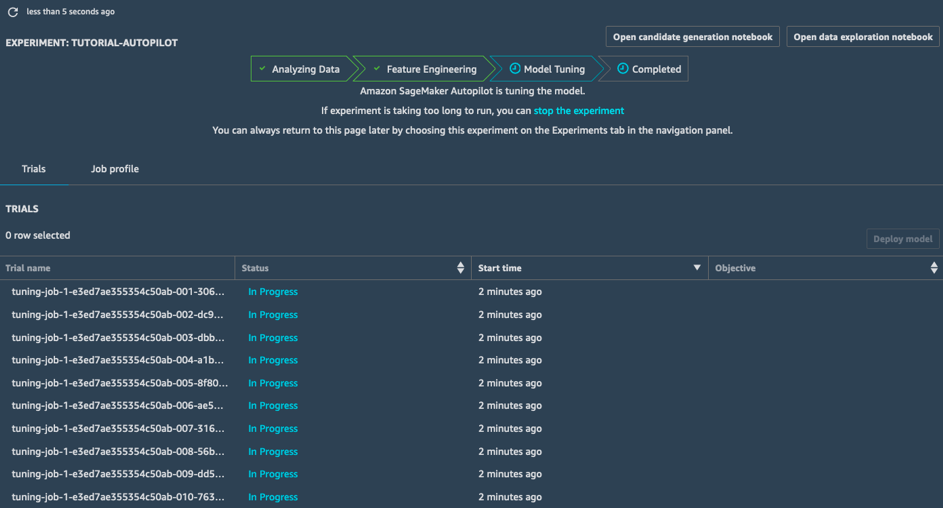
In der Phase der Modelloptimierung startet SageMaker Autopilot für jede Kandidatenpipeline und die entsprechenden vorverarbeiteten Datensätze eine Hyperparameter-Optimierungsaufgabe. Die zugehörigen Trainingsaufgaben untersuchen ganz verschiedene Hyperparameter-Werte und laufen schnell zu Hochleistungsmodellen zusammen.
Nach Abschluss dieser Phase ist auch die SageMaker Autopilot-Aufgabe abgeschlossen. Sie können alle Aufgaben in SageMaker Studio anzeigen und erforschen.
Schritt 6: Bereitstellen des besten Modells
Da Ihr Experiment jetzt abgeschlossen ist, können Sie die beste Optimierungsaufgabe auswählen und das Modell auf einem von Amazon SageMaker verwalteten Endpunkt bereitstellen.
Folgen Sie diesen Schritten, um die beste Optimierungsaufgabe auszuwählen und das Modell bereitzustellen.
Hinweis: Weitere Informationen finden Sie unter Auswählen und Bereitstellen des besten Modells.
a. Wählen Sie in der Liste Trials Ihres Experiments die Karotte neben Objective aus, um die Optimierungsaufgaben in absteigender Reihenfolge zu sortieren. Die beste Optimierungsaufgabe wird durch einen Stern gekennzeichnet.
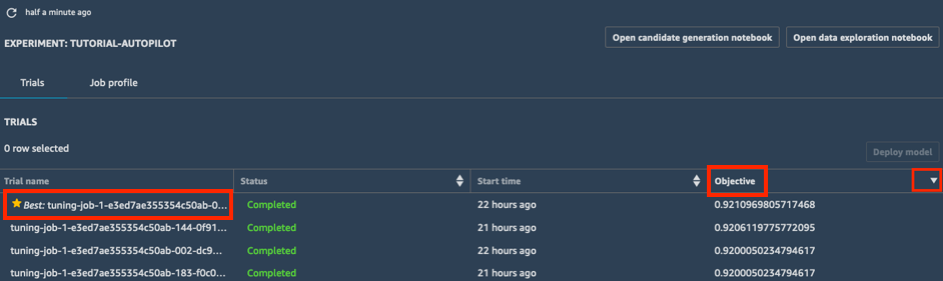
b. Wählen Sie die beste Optimierungsaufgabe (durch einen Stern gekennzeichnet) und dann Deploy model aus.
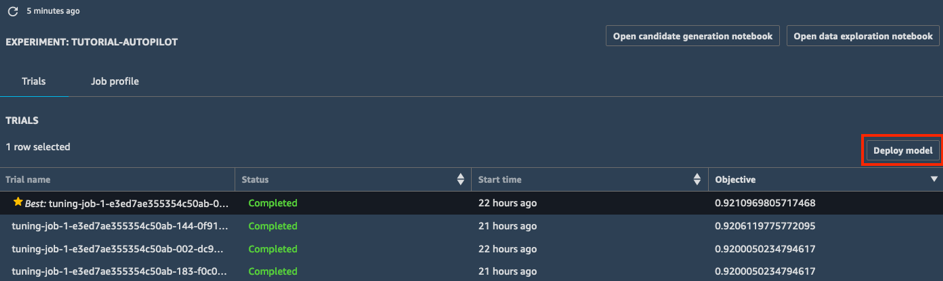
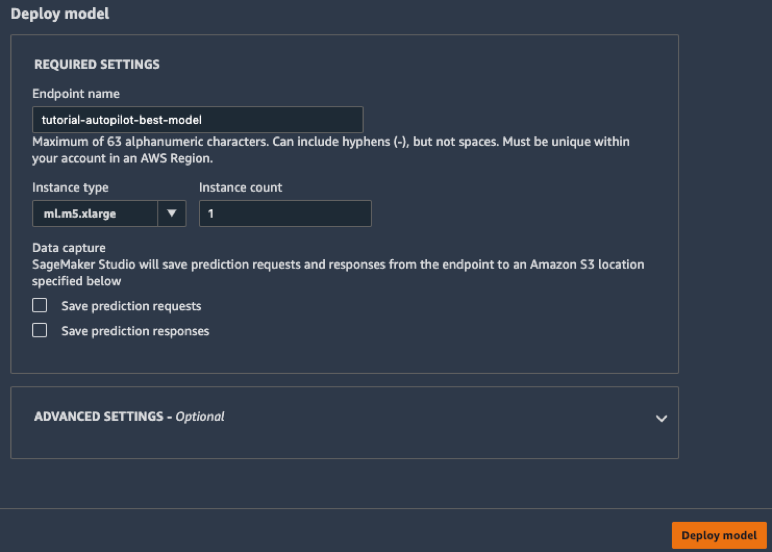
c. Geben Sie im Feld Deploy model den Namen Ihres Endpunkts an (z. B. tutorial-autopilot-best-model) und behalten Sie alle Standardeinstellungen bei. Wählen Sie Deploy model aus.
Ihr Modell wird auf einem von Amazon SageMaker verwalteten HTTPS-Endpunkt bereitgestellt.
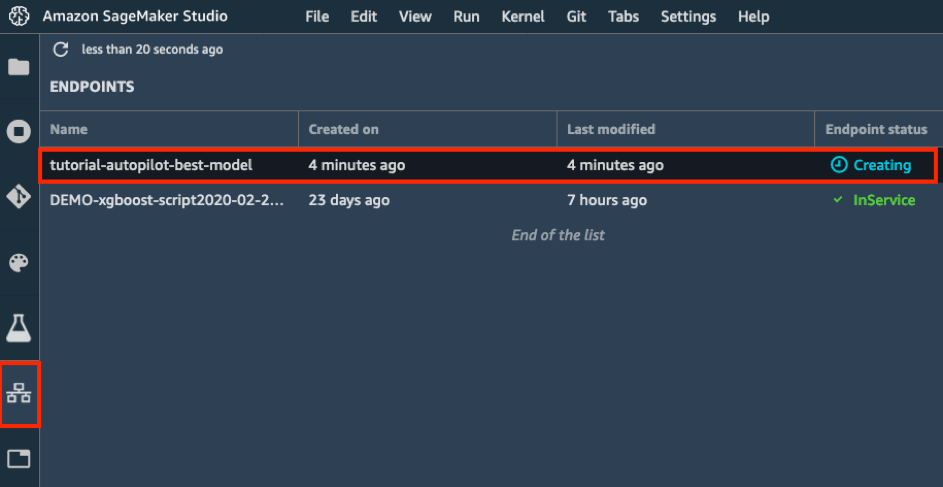
d. Wählen Sie in der linken Symbolleiste das Symbol Endpoints aus. Sie sehen, dass Ihr Modell erstellt wird. Das kann einige Minuten dauern. Sobald der Endpunktstatus InService lautet, können Sie Daten senden und Prognosen erhalten!
Schritt 7: Erstellen von Prognosen mit Ihrem Modell
Da das Modell jetzt bereitgestellt ist, können Sie die ersten 2 000 Beispiele des Datensatzes prognostizieren. Zu diesem Zweck verwenden Sie die invoke_endpoint-API aus dem boto3-SDK. In diesem Vorgang berechnen Sie wichtige Machine Learning-Metriken: Genauigkeit, Präzision, Widerruf und den F1-Score.
Folgen Sie diesen Schritten, um mit Ihrem Modell Prognosen zu erstellen.
Hinweis: Weitere Informationen finden Sie unter Verwalten von Machine Learning mit Amazon SageMaker-Experimenten.
Kopieren Sie den folgenden Code in Ihr Jupyter-Notebook und wählen Sie Run aus.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
Sie sollten die folgende Ausgabe sehen:
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
Diese Ausgabe ist eine Fortschrittsanzeige, die die Anzahl der prognostizierten Beispiele zeigt.
Schritt 8: Bereinigen
In diesem Schritt beenden Sie die in dieser Übung verwendeten Ressourcen.
Wichtig: Die Beendigung von Ressourcen, die nicht aktiv genutzt werden, senkt die Kosten und ist eine bewährte Methode. Wenn Sie Ihre Ressourcen nicht beenden, fallen Gebühren für Ihr Konto an.
Löschen Sie Ihren Endpunkt: Kopieren Sie den folgenden Code in Ihr Jupyter-Notebook und wählen Sie Run aus.
sess.delete_endpoint(endpoint_name=ep_name)Wenn Sie alle Trainingsartefakte (Modelle, vorverarbeitete Datensätze usw.) bereinigen möchten, kopieren Sie den folgenden Code in Ihre Codezelle. Wählen Sie dann Run aus.
Hinweis: Verwenden Sie für [KONTONUMMER] Ihre eigene Kontonummer.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Herzlichen Glückwunsch!
Sie haben ein Machine Learning-Modell mit der höchsten Genauigkeit automatisch mithilfe von Amazon SageMaker Autopilot erstellt.
Empfohlene nächste Schritte
Unternehmen Sie eine Tour durch Amazon SageMaker Studio
Erhalt weiterer Informationen zu Amazon SageMaker Autopilot
Falls Sie weitere Informationen benötigen, lesen Sie den Blog-Beitrag oder sehen Sie sich die Autopilot-Videoreihe an.