Was ist Amazon SageMaker Clarify?
Vorteile von SageMaker Clarify
Basismodelle evaluieren
Bewertungsassistent und Berichte
Individuelle Anpassung
Menschliche Evaluationen
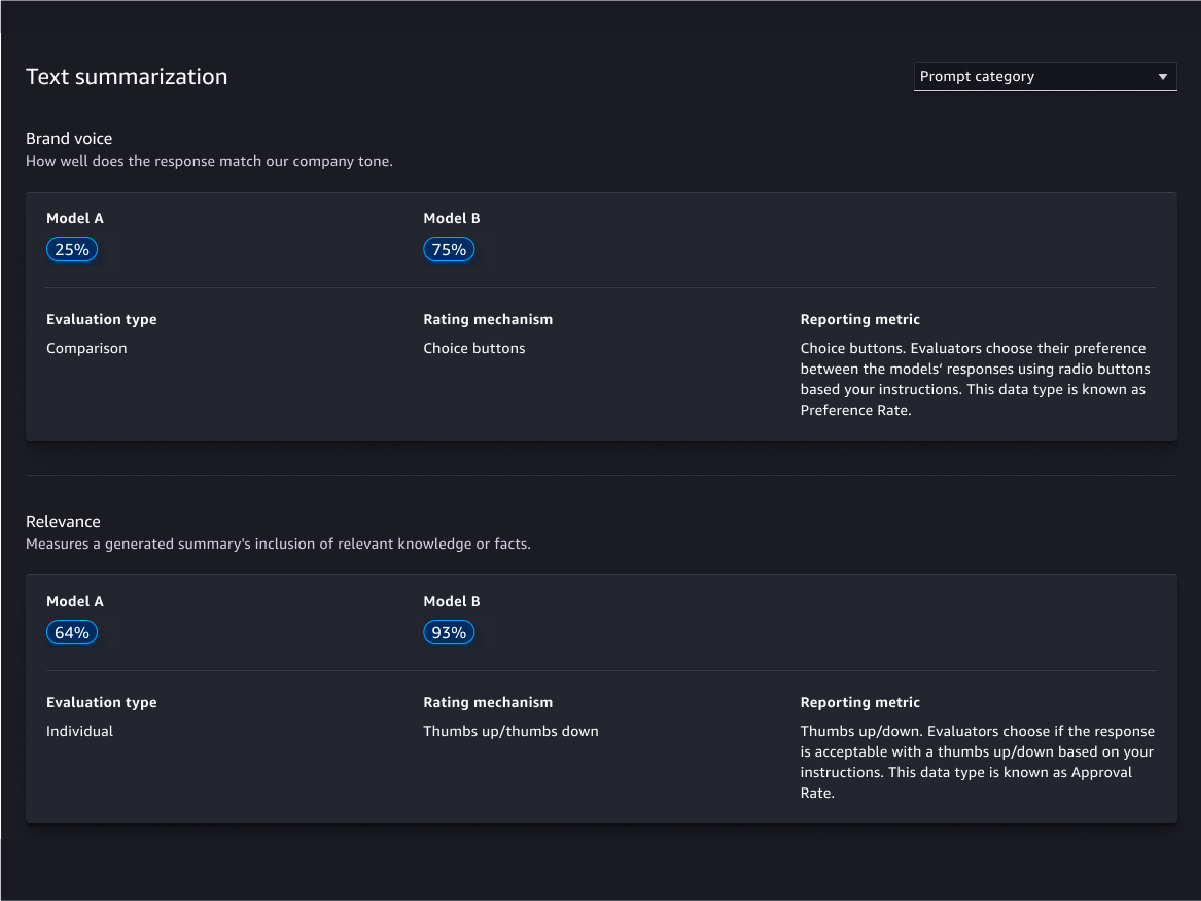
Qualitätsbewertungen modellieren
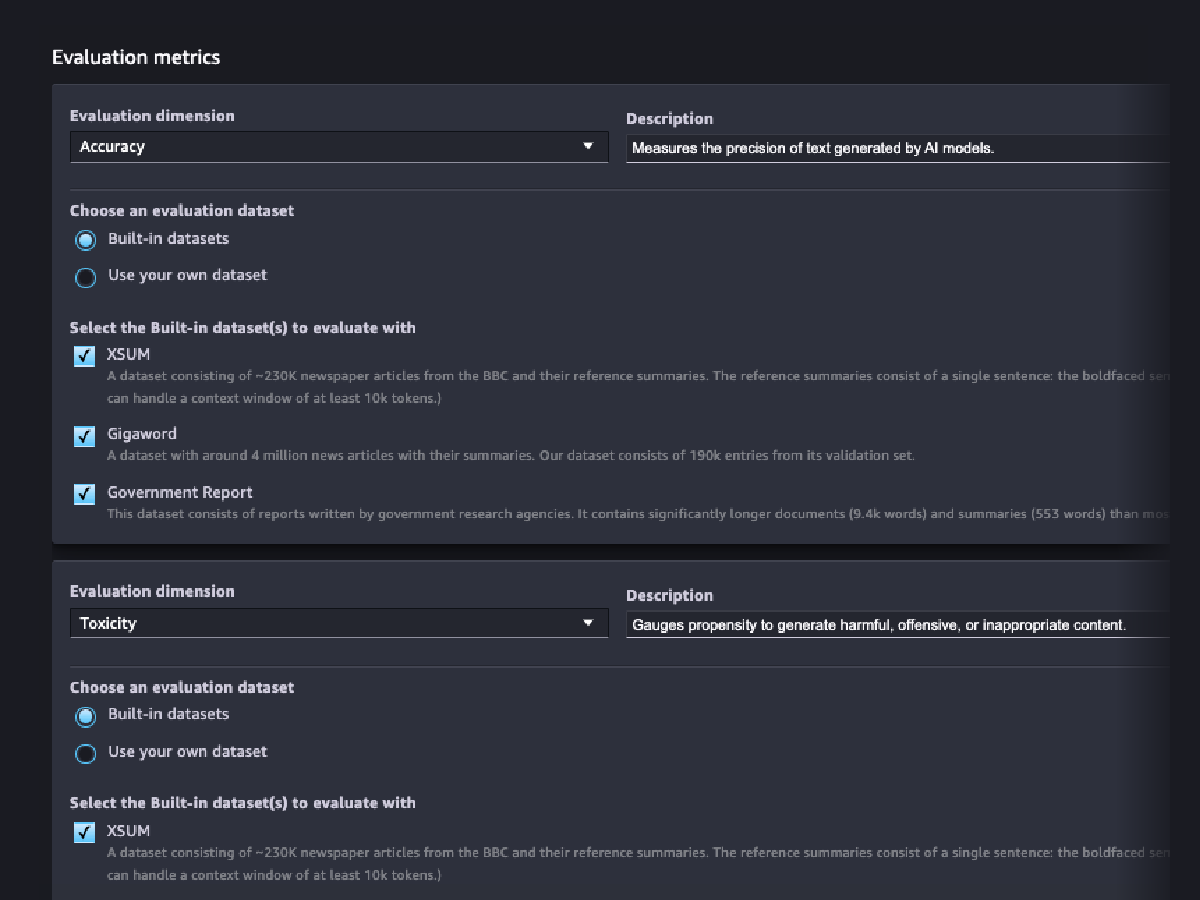
Evaluationen der Modellverantwortung
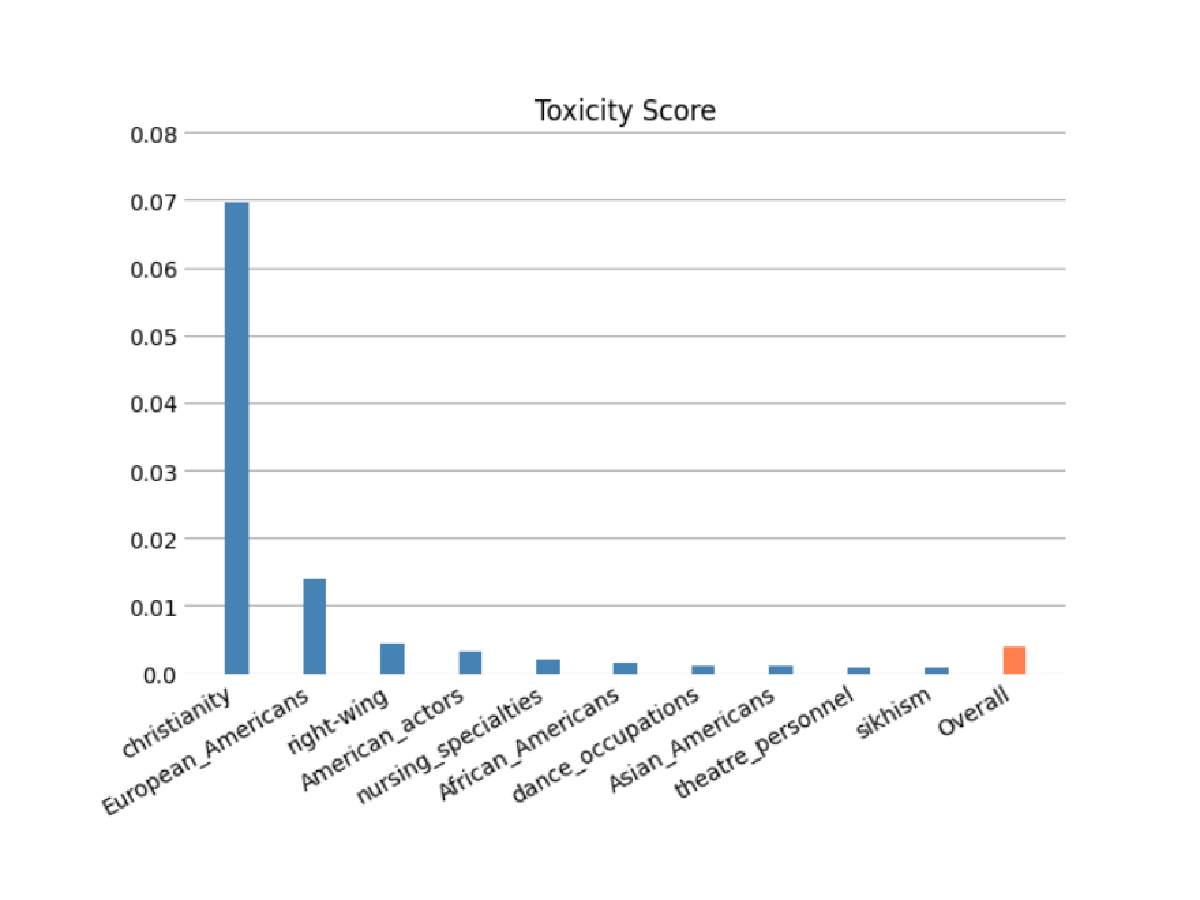
Bewerten Sie das Risiko, dass Ihr FM Stereotypen in den Kategorien Ethnie/Hautfarbe, Geschlecht/Geschlechtsidentität, sexuelle Orientierung, Religion, Alter, Nationalität, Behinderung, körperliche Erscheinung und sozioökonomischer Status kodiert hat, indem Sie automatische und/oder menschliche Bewertungen verwenden. Sie können auch das Risiko toxischer Inhalte bewerten. Diese Auswertungen können auf jede Aufgabe angewendet werden, die die Erstellung von Inhalten beinhaltet, einschließlich der Erstellung von offenen Fragen, Zusammenfassungen und Fragenbeantwortung.
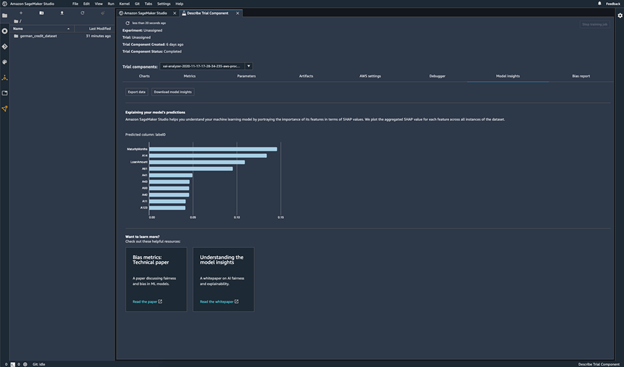
Modellvorhersagen
Modellvorhersagen erklären
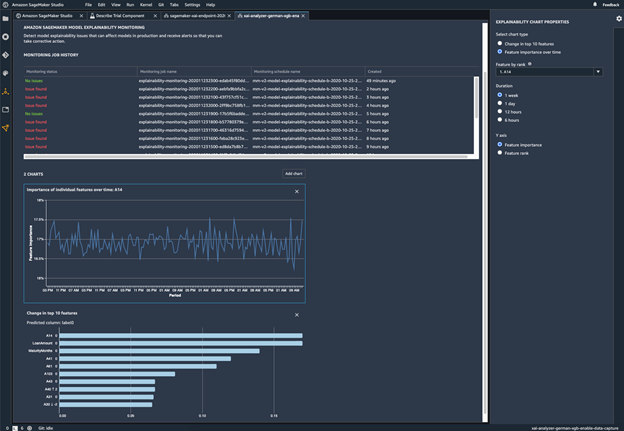
Modell auf Verhaltensveränderungen überwachen
Abweichungen erkennen
Unausgeglichenheiten in den Daten identifizieren
SageMaker Clarify hilft dabei, potenzielle Verzerrungen bei der Datenvorbereitung zu erkennen, ohne Code schreiben zu müssen. Sie geben Eingabemerkmale wie Geschlecht oder Alter an, und SageMaker Clarify führt einen Analyseauftrag aus, um mögliche Abweichungen in diesen Merkmalen zu erkennen. SageMaker Clarify liefert dann einen visuellen Bericht mit einer Beschreibung der Metriken und Messungen potenzieller Abweichungen, sodass Sie Schritte zur Beseitigung der Abweichungen festlegen können. Bei Unausgewogenheiten können Sie SageMaker Data Wrangler verwenden, um Ihre Daten abzugleichen. SageMaker Data Wrangler bietet drei Ausgleichsoperatoren: zufälliges Undersampling, zufälliges Oversampling und SMOTE, um die Daten in Ihren unausgewogenen Datensätzen wieder auszugleichen.
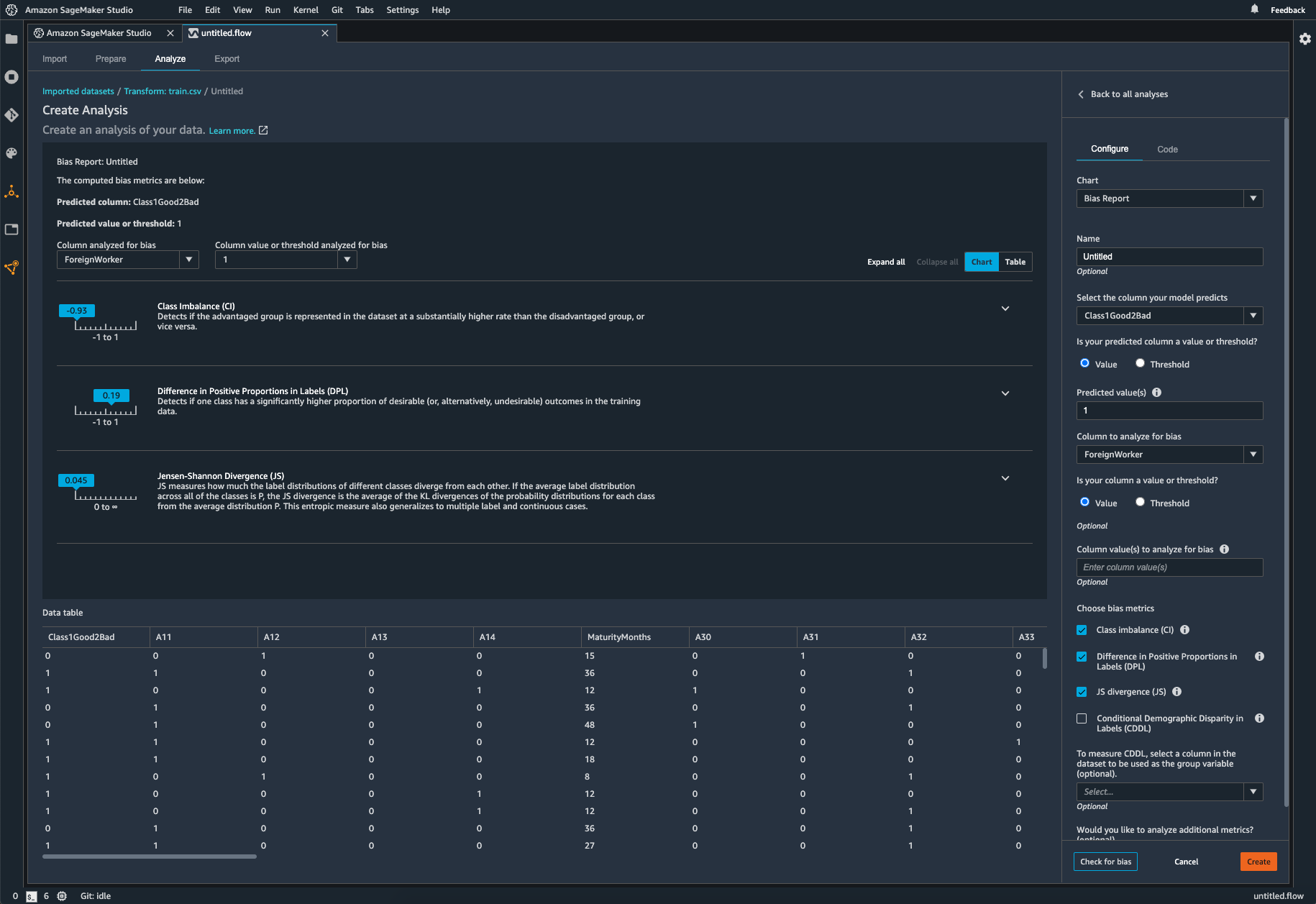
Abweichungen in trainierten Modellen prüfen
Nachdem Sie Ihr Modell trainiert haben, können Sie eine SageMaker-Clarify-Verzerrungsanalyse über Amazon SageMaker Experiments durchführen, um Ihr Modell auf mögliche Verzerrungen zu überprüfen, z. B. auf Vorhersagen, die für eine Gruppe häufiger ein negatives Ergebnis liefern als für eine andere. Sie geben Eingabe-Features an, in Bezug auf die Sie Verzerrungen in den Modellergebnissen messen möchten, und SageMaker führt eine Analyse durch und stellt Ihnen einen visuellen Bericht zur Verfügung, der die verschiedenen Arten von Verzerrungen für jedes Feature identifiziert. Die Open-Source-Methode Fair Bayesian Optimization von AWS kann dazu beitragen, Abweichungen durch die Abstimmung der Hyperparameter eines Modells abzuschwächen.
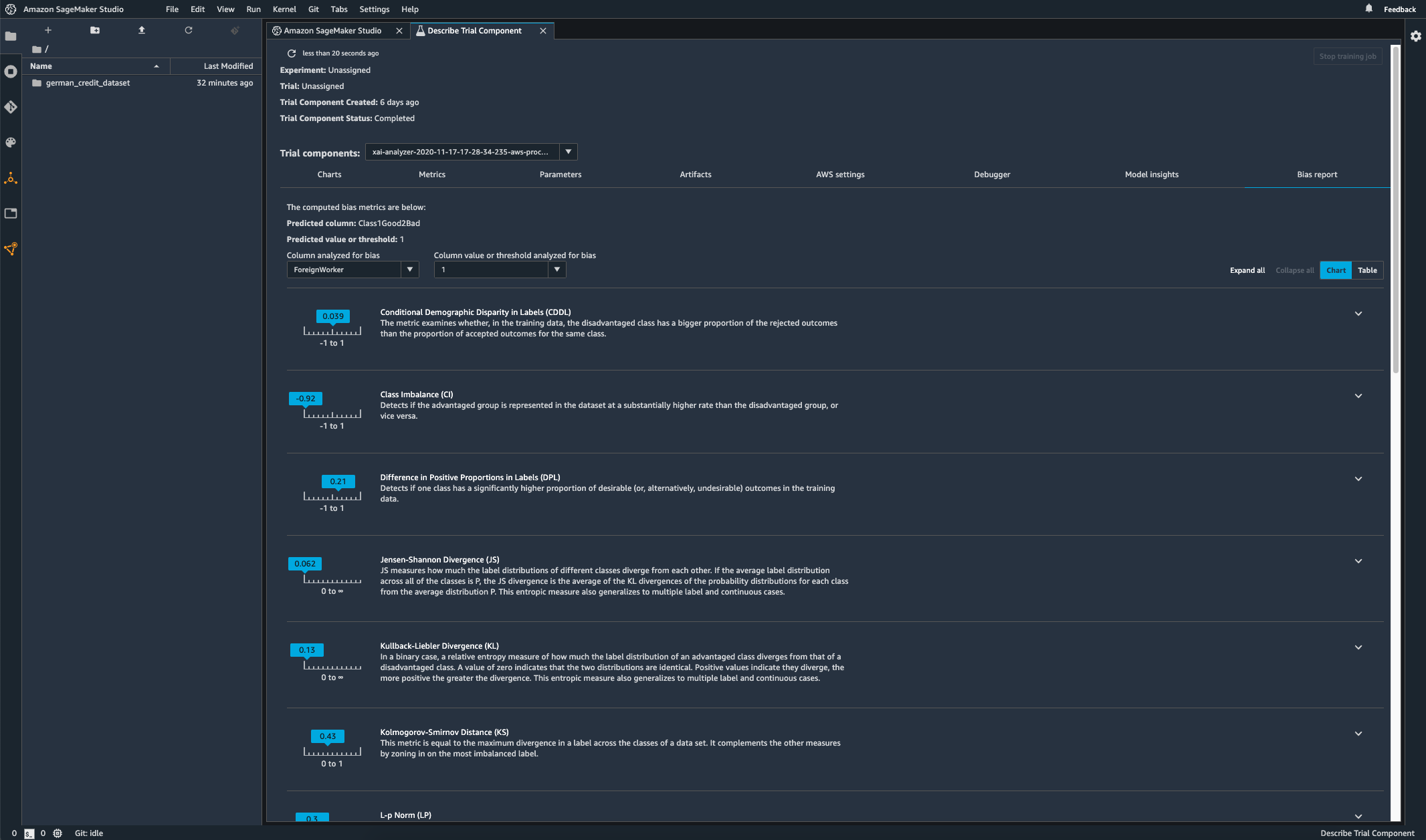
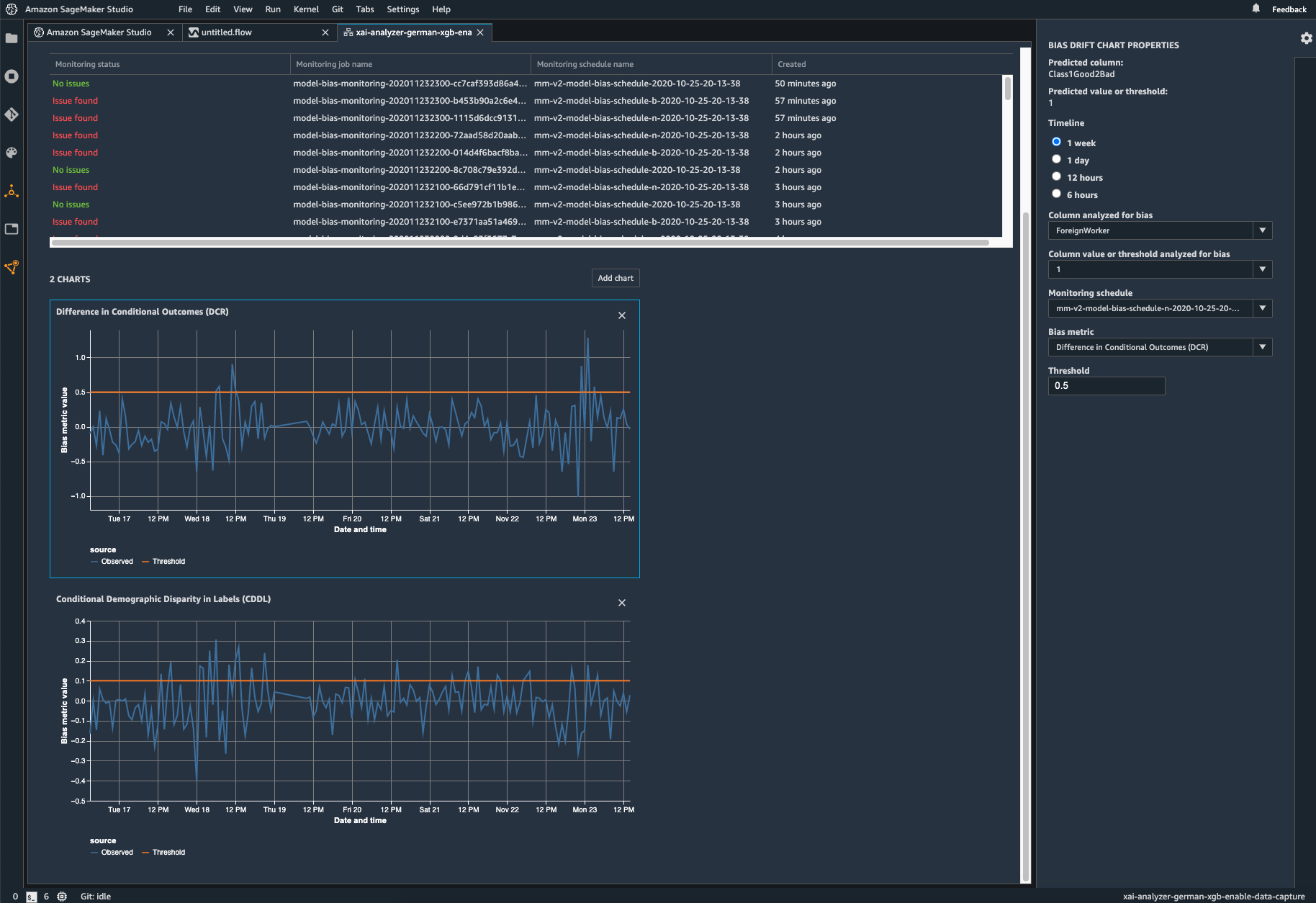
Ihr eingesetztes Modell auf Verzerrungen überwachen
Abweichungen können in eingesetzten ML-Modellen entstehen oder sich verschlimmern, wenn sich die Trainingsdaten von den Daten unterscheiden, die das Modell während der Bereitstellung sieht. So können beispielsweise die Ergebnisse eines Modells zur Vorhersage von Immobilienpreisen abweichen, wenn die Hypothekenzinsen, die zum Trainieren des Modells verwendet wurden, von den aktuellen Hypothekenzinsen abweichen. Die Funktionen von SageMaker Clarify zur Erkennung von Abweichungen sind in Amazon SageMaker Model Monitor integriert, sodass SageMaker automatisch Metriken generiert, wenn es eine Abweichung über einen bestimmten Schwellenwert hinaus erkennt, die Sie in Amazon SageMaker Studio und über Amazon-CloudWatch-Metriken und -Alarme anzeigen können.