Amazon SageMaker Data Wrangler
Die schnellste und einfachste Methode, Daten für Machine Learning vorzubereiten – jetzt in SageMaker Canvas
Warum SageMaker Data Wrangler?
Amazon SageMaker Data Wrangler reduziert die Datenvorbereitungszeit für Tabellen-, Bild- und Textdaten von Wochen auf Minuten. Mit SageMaker Data Wrangler können Sie die Datenaufbereitung und das Feature Engineering durch eine visuelle Schnittstelle in natürlicher Sprache vereinfachen. Wählen, importieren und transformieren Sie Daten schnell mit SQL und über 300 integrierten Transformationen, ohne Code schreiben zu müssen. Erstellen Sie intuitive Datenqualitätsberichte, um Anomalien zwischen Datentypen zu erkennen und die Modellleistung abzuschätzen. Skalieren Sie für die Verarbeitung von Petabytes an Daten.
Vorteile von SageMaker Data Wrangler
Funktionsweise
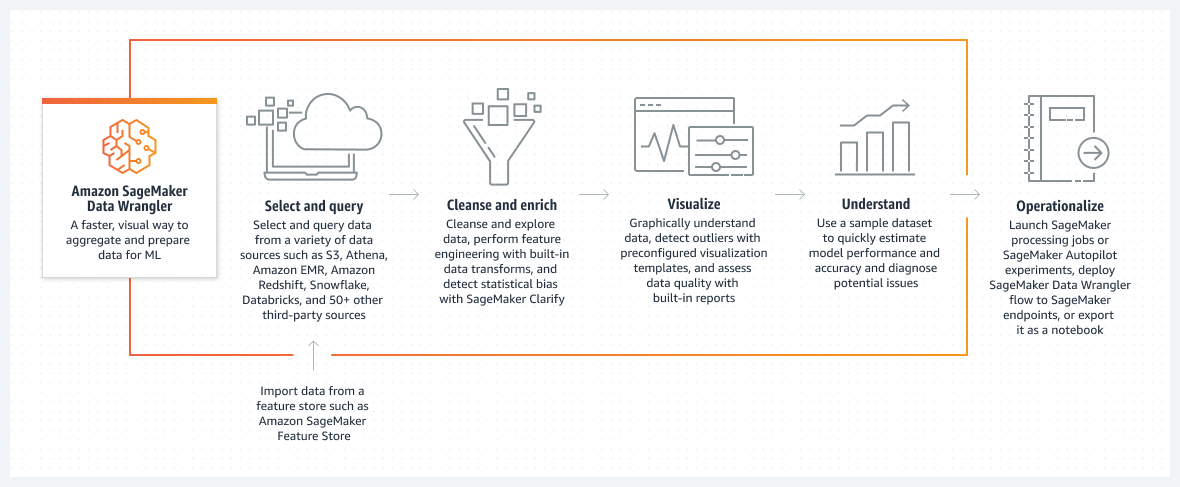
Funktionsweise

Titel 1: Amazon SageMaker Data Wrangler
Beschreibungstext: Eine schnellere, visuelle Methode zur Aggregation und Vorbereitung von Daten für ML
Titel 2: Auswählen und Abfragen
Beschreibungstext: Daten aus einer Vielzahl von Datenquellen wie Amazon S3, Athena, Amazon EMR, Amazon Redshift, Snowflake, Databricks und mehr als 50 weiteren Drittanbieterquellen auswählen und abfragen
Unter Beschreibung: Importieren Sie Daten aus einem Feature Store wie Amazon SageMaker Feature Store
Titel 3: Reinigen und bereichern
Beschreibungstext: Bereinigen und untersuchen Sie Daten, führen Sie Feature Engineering mit integrierten Datentransformationen durch und erkennen Sie statistische Verzerrungen mit SageMaker Clarify
Titel 4: Visualisieren
Beschreibungstext: Verstehen Sie Daten grafisch, erkennen Sie Ausreißer mit vorkonfigurierten Visualisierungsvorlagen und bewerten Sie die Datenqualität mit integrierten Berichten.
Titel 5: Verstehen
Beschreibungstext: Verwenden Sie einen Beispieldatensatz, um die Leistung und Genauigkeit des Modells schnell abzuschätzen und mögliche Probleme zu diagnostizieren
Titel 6: Operationalisieren
Beschreibungstext: Starten Sie SageMaker-Verarbeitungsaufträge oder SageMaker-Autopilot-Experimente, setzen Sie SageMaker-Data-Wrangler-Flows an SageMaker-Endpunkten ein oder exportieren Sie sie als Notizbuch.
Schnellerer Zugriff, Auswahl und Abfrage von Daten
Mit SageMaker Data Wrangler können Sie schnell auf Tabellen-, Text- und Bilddaten von Amazon-Services wie S3, Athena, Redshift und mehr als 50 Quellen von Drittanbietern zugreifen. Sie können Daten mit dem Visual Query Builder auswählen, SQL-Abfragen schreiben oder Daten direkt in verschiedenen Formaten wie CSV und Parquet importieren.

Datenerkenntnisse generieren und die Datenqualität verstehen
SageMaker Data Wrangler bietet einen Bericht über Datenqualität und -erkenntnisse, der automatisch die Datenqualität (z. B. fehlende Werte, doppelte Zeilen und Datentypen) überprüft und hilft, Anomalien (z. B. Ausreißer, Klassenungleichgewicht und Datenlecks) in Ihren Daten zu erkennen. Sobald Sie die Datenqualität effektiv überprüfen können, können Sie Domainwissen schnell anwenden, um Datensätze für das ML-Modelltraining zu verarbeiten.

Verstehen Sie Ihre Daten mit Visualisierungen
SageMaker Data Wrangler hilft Ihnen, Ihre Daten durch robuste integrierte Visualisierungsvorlagen wie Histogramme, Streudiagramme, Merkmalsbedeutung und Korrelationen zu verstehen. Beschleunigen Sie die Datenuntersuchung mit intuitiven Datenqualitätsberichten, die Anomalien in verschiedenen Datentypen erkennen und Empfehlungen zur Verbesserung der Datenqualität geben.

Daten effizienter transformieren
SageMaker Data Wrangler bietet über 300 vorgefertigte PySpark-Transformationen und eine natürliche Sprachschnittstelle zur Aufbereitung von Tabellen-, Zeitreihen-, Text- und Bilddaten ohne Codierung. Gängige Anwendungsfälle wie die Vektorisierung von Text, die Funktion von Datum und Uhrzeit, Codierung, Datenausgleich oder Bilderweiterung werden behandelt. Sie können auch benutzerdefinierte Transformationen in PySpark, SQL und Pandas erstellen oder eine Schnittstelle für natürliche Sprache verwenden, um Code zu generieren. Eine integrierte Bibliothek mit Codeschnipseln vereinfacht das Schreiben benutzerdefinierter Transformationen.

Verstehen Sie die Vorhersagekraft Ihrer Daten
SageMaker Data Wrangler bietet eine Schnellmodellanalyse, um die Vorhersagekraft Ihrer Daten abzuschätzen. Sie erhalten die geschätzte Modellgenauigkeit, die Merkmalsbedeutung und eine Konfusionsmatrix, mit der Sie Ihre Datenqualität vor dem Training von Modellen überprüfen können.

ML-Datenvorbereitungs-Workflows automtisieren und bereitstellen
Mit SageMaker Data Wrangler können Sie skalieren, um Petabyte an Daten vorzubereiten, ohne PySpark zu programmieren oder Cluster zu starten. Starten Sie Verarbeitungsaufträge direkt von der Benutzeroberfläche aus, oder integrieren Sie die Datenvorbereitung in ML-Workflows, indem Sie Daten in den SageMaker Feature Store exportieren oder in SageMaker Pipelines integrieren. Sie können Datenflüsse auch als Jupyter Notebooks oder Python-Skript exportieren, um Ihre Datenvorbereitungsschritte programmatisch zu replizieren.

Kunden
„Bei INVISTA sind wir von Transformation getrieben und wollen Produkte und Technologien entwickeln, von denen Kunden auf der ganzen Welt profitieren. Wir sehen ML als eine Möglichkeit, das Kundenerlebnis zu verbessern. Angesichts der Datensätze, die sich über Hunderte von Millionen Zeilen erstrecken, brauchten wir jedoch eine Lösung, die uns hilft, Daten vorzubereiten und ML-Modelle in großem Maßstab zu entwickeln, bereitzustellen und zu verwalten. Mit Amazon SageMaker Data Wrangler können wir unsere Daten jetzt interaktiv auswählen, bereinigen, untersuchen und verstehen, sodass unser Data-Science-Team Feature-Engineering-Pipelines erstellen kann, die mühelos auf Datensätze skaliert werden können, die Hunderte von Millionen von Zeilen umfassen. Mit Amazon SageMaker Data Wrangler können wir unsere ML-Workflows schneller operationalisieren.“
Caleb Wilkinson, ehemaliger Lead Data Scientist – INVISTA
„Mit ML verbessert 3M bewährte Produkte wie Sandpapier und treibt Innovationen in mehreren anderen Bereichen voran, darunter im Gesundheitswesen. Da wir planen, ML auf weitere Bereiche von 3M zu skalieren, sehen wir, dass die Menge an Daten und Modellen schnell wächst und sich jedes Jahr verdoppelt. Wir sind von den neuen SageMaker-Funktionen begeistert, weil sie uns bei der Skalierung helfen. Amazon SageMaker Data Wrangler macht es viel einfacher, Daten für das Modelltraining vorzubereiten, und der Amazon SageMaker Feature Store macht es überflüssig, immer wieder dieselben Modellfunktionen zu erstellen. Schließlich wird uns Amazon SageMaker Pipelines dabei helfen, die Datenvorbereitung, Modellerstellung und Modellbereitstellung in einen End-to-End-Workflow zu automatisieren, damit wir die Markteinführungszeit für unsere Modelle verkürzen können. Unsere Forscher freuen sich darauf, die neue Geschwindigkeit der Wissenschaft bei 3M zu nutzen.“
David Frazee, ehemaliger Technical Director, 3M Corporate Research Systems Lab
„Amazon SageMaker Data Wrangler ermöglicht es uns, mit einer umfangreichen Sammlung von Transformationstools, die den Prozess der ML-Datenvorbereitung, der für die Markteinführung neuer Produkte erforderlich ist, zu beschleunigen, um unsere Anforderungen an Datenvorbereitung zu erfüllen. Unsere Kunden wiederum profitieren von der Geschwindigkeit, mit der wir eingesetzte Modelle skalieren, die es uns ermöglicht, innerhalb von Tagen statt Monaten messbare, nachhaltige Ergebnisse zu liefern, die die Bedürfnisse unserer Kunden erfüllen.“
Frank Farrall, Principal, AI Ecosystems and Platforms Leader, Deloitte
„Als AWS Premier Consulting Partner arbeiten unsere Engineering-Teams sehr eng mit AWS zusammen, um innovative Lösungen zu entwickeln, die unseren Kunden dabei helfen, die Effizienz ihres Betriebs kontinuierlich zu verbessern. ML ist der Kern unserer innovativen Lösungen, aber unser Datenvorbereitungs-Workflow umfasst ausgefeilte Datenvorbereitungstechniken, deren Operationalisierung in einer Produktionsumgebung daher viel Zeit in Anspruch nimmt. Mit Amazon SageMaker Data Wrangler können unsere Datenwissenschaftler jeden Schritt des Datenvorbereitungs-Workflows abschließen, einschließlich Datenauswahl, Bereinigung, Exploration und Visualisierung, was uns hilft, den Datenvorbereitungsprozess zu beschleunigen und unsere Daten einfach für ML vorzubereiten. Mit Amazon SageMaker Data Wrangler können wir Daten schneller für ML vorbereiten.“
Shigekazu Ohmoto, Senior Corporate Managing Director, NRI Japan
„Da sich unsere Präsenz auf dem Markt für bevölkerungsbezogenes Gesundheitsmanagement weiter auf immer mehr Gesundheitszahler, Leistungserbringer, Apothekenleistungsverwalter und andere Gesundheitswesenorganisationen ausdehnt, benötigten wir eine Lösung zur Automatisierung von End-to-End-Prozessen für Datenquellen, die unsere Modelle für ML füttern, einschließlich Anspruchsdaten, Registrierungsdaten und Apothekendaten. Mit Amazon SageMaker Data Wrangler können wir jetzt die Zeit zum Aggregieren und Vorbereiten von Daten für ML beschleunigen, indem wir eine Reihe von Workflows verwenden, die einfacher zu validieren und wiederzuverwenden sind. Dies hat die Lieferzeit und Qualität unserer Modelle dramatisch verbessert, die Effektivität unserer Datenwissenschaftler erhöht und die Datenvorbereitungszeit um fast 50 % reduziert. Darüber hinaus hat uns SageMaker Data Wrangler geholfen, mehrere Iterationen von ML und erhebliche GPU-Zeit zu sparen und den gesamten End-to-End-Prozess für unsere Kunden zu beschleunigen, da wir jetzt Data Marts mit Tausenden von Funktionen erstellen können, darunter Apotheken, Diagnosecodes, Notaufnahmebesuche, stationäre Patientenaufenthalte sowie demografische und andere soziale Determinanten. Mit SageMaker Data Wrangler können wir unsere Daten mit überlegener Effizienz zum Erstellen von Trainingsdatensätzen transformieren, Datenerkenntnisse in Datensätze generieren, bevor Modelle für ML ausgeführt werden und reale Daten für maßstabsgetreue Inferenz/Vorhersagen vorbereiten.“
Lucas Merrow, CEO, Equilibrium Point IoT