



Was ist Datenmodellierung?
Bei der Datenmodellierung handelt es sich um den Prozess der Erstellung einer visuellen Darstellung oder eines Entwurfs, der die Informationssammlungs- und -verwaltungssysteme eines Unternehmens definiert. Diese Vorlage oder dieses Datenmodell hilft verschiedenen Beteiligten, wie Datenanalysten, Wissenschaftlern und Ingenieuren, eine einheitliche Sicht auf die Daten des Unternehmens zu erstellen. Das Modell beschreibt, welche Daten das Unternehmen erfasst, und legt die Beziehung zwischen den verschiedenen Datensätzen und die Methoden fest, die zum Speichern und Analysieren der Daten verwendet werden sollen.
Warum ist Datenmodellierung wichtig?
Organisationen sammeln heute eine große Menge an Daten aus vielen verschiedenen Quellen. Rohdaten reichen jedoch oft nicht aus. Man muss Daten analysieren, um umsetzbare Erkenntnisse zu gewinnen, die zu profitablen Geschäftsentscheidungen führen können. Eine genaue Datenanalyse erfordert eine effiziente Datenerfassung, -speicherung und -verarbeitung. Es gibt mehrere Datenbanktechnologien und Datenverarbeitungstools, und unterschiedliche Datensätze erfordern unterschiedliche Tools für eine effiziente Analyse.
Die Datenmodellierung gibt Ihnen die Möglichkeit, Ihre Daten zu verstehen und die richtigen technologischen Entscheidungen zum Speichern und Verwalten dieser Daten zu treffen. Auf die gleiche Art und Weise, wie ein Architekt einen Entwurf entwirft, bevor er ein Haus baut, entwerfen Business-Stakeholder ein Datenmodell, bevor sie Datenbanklösungen für ihre Organisation entwickeln.
Die Datenmodellierung bringt folgende Vorteile:
- Reduziert Fehler bei der Entwicklung von Datenbanksoftware
- Erleichtert die Geschwindigkeit und Effizienz von Datenbankdesign und -erstellung
- Schafft Konsistenz in der Datendokumentation und im Systemdesign im gesamten Unternehmen
- Erleichtert die Kommunikation zwischen Dateningenieuren und Business-Intelligence-Teams
Welche Arten von Datenmodellierung gibt es?
Die Datenmodellierung beginnt typischerweise damit, die Daten konzeptionell darzustellen und sie dann erneut im Kontext der gewählten Technologien darzustellen. Analysten und Stakeholder erstellen während der Datendesign-phase mehrere verschiedene Arten von Datenmodellen. Im Folgenden sind drei Haupttypen von Datenmodellen aufgeführt:
Konzeptionelles Datenmodell
Konzeptionelle Datenmodelle geben einen Überblick über die Daten. Sie erklären Folgendes:
- Welche Daten das System enthält
- Datenattribute und Bedingungen oder Einschränkungen für die Daten
- Auf welche Geschäftsregeln sich die Daten beziehen
- Wie die Daten am besten organisiert sind
- Anforderungen an Sicherheit und Datenintegrität
Die Business-Stakeholder und Analysten erstellen in der Regel das konzeptionelle Modell. Es handelt sich um eine einfache schematische Darstellung, die keinen formalen Datenmodellierungs-Regeln folgt. Was zählt, ist, dass es sowohl technischen als auch nichttechnischen Stakholdern hilft, eine gemeinsame Vision zu teilen und sich auf Zweck, Umfang und Design ihres Datenprojekts zu einigen.
Beispiel für konzeptionelle Datenmodelle
Beispielsweise könnte das konzeptionelle Datenmodell für ein Autohaus die Daten-Entitäten wie folgt anzeigen:
- Eine Showroom-Entität, die Informationen über die verschiedenen Verkaufsstellen des Autohauses darstellt
- Eine Auto-Entität, die die verschiedenen Autos repräsentiert, die das Autohaus derzeit auf Lager hat
- Eine Kunden-Entität, die alle Kunden repräsentiert, die einen Kauf bei dem Händler getätigt haben
- Eine Verkaufs-Entität, die die Informationen über den tatsächlichen Verkauf darstellt
- Eine Verkäufer-Entität, die die Informationen über alle Verkäufer darstellt, die für das Autohaus arbeiten
Dieses konzeptionelle Modell würde auch Geschäftsanforderungen wie die folgenden umfassen:
- Jedes Auto muss zu einem bestimmten Showroom gehören.
- Jedem Verkauf muss mindestens ein Verkäufer und ein Kunde zugeordnet sein.
- Jedes Auto muss einen Markennamen und eine Produktnummer haben.
- Jeder Kunde muss seine Telefonnummer und E-Mail-Adresse angeben.
Konzeptionelle Modelle fungieren somit als Brücke zwischen den Geschäftsregeln und dem zugrunde liegenden physischen Datenbank-Managementsystem (DBMS). Konzeptionelle Datenmodelle werden auch Domänenmodelle genannt.
Logisches Datenmodell
Logische Datenmodelle bilden die konzeptionellen Datenklassen auf technische Datenstrukturen ab. Sie geben weitere Details zu den Datenkonzepten und komplexen Datenbeziehungen, die im konzeptionellen Datenmodell identifiziert wurden, wie z. B. diese:
- Datentypen der verschiedenen Attribute (z. B. Zeichenfolge oder Zahl)
- Beziehungen zwischen den Daten-Entitäten
- Primärattribute oder Schlüsselfelder in den Daten
Datenarchitekten und Analysten arbeiten zusammen, um das logische Modell zu erstellen. Sie folgen einem von mehreren formalen Datenmodellierungs-Systemen, um die Darstellung zu erstellen. Manchmal entscheiden sich agile Teams dafür, diesen Schritt zu überspringen und direkt von konzeptionellen zu physischen Modellen überzugehen. Diese Modelle sind jedoch nützlich zum Entwerfen großer Datenbanken, sogenannter Data Warehouses und zum Entwerfen automatischer Berichtssysteme.
Beispiel für logische Datenmodelle
In unserem Autohaus-Beispiel würde das logische Datenmodell das konzeptionelle Modell erweitern und die Datenklassen wie folgt genauer betrachten:
- Die Showroom-Entität hat Felder wie Name und Standort als Textdaten und eine Telefonnummer als numerische Daten.
- Die Kunden-Entität hat eine Feld-E-Mail-Adresse im Format xxx@example.com oder xxx@example.com.yy. Der Feldname darf maximal 100 Zeichen lang sein.
- Die Verkaufs-Entität hat einen Kundennamen und einen Verkäufernamen als Felder, zusammen mit dem Verkaufsdatum als Datumsdatentyp und dem Betrag als dezimaler Datentyp.
Logische Modelle fungieren somit als Brücke zwischen dem konzeptionellen Datenmodell und der zugrunde liegenden Technologie und Datenbanksprache, die Entwickler zum Erstellen der Datenbank verwenden. Sie sind jedoch technologieunabhängig und können in jeder Datenbanksprache implementiert werden. Dateningenieure und Stakeholder treffen in der Regel Technologieentscheidungen, nachdem sie ein logisches Datenmodell erstellt haben.
Physische Datenmodell
Physische Datenmodelle ordnen die logischen Datenmodelle einer bestimmten DBMS-Technologie zu und verwenden die Terminologie der Software. Sie geben beispielsweise Auskunft über Folgendes:
- Datenfeldtypen, wie sie im DBMS dargestellt werden
- Datenbeziehungen, wie sie im DBMS dargestellt werden
- Zusätzliche Details, wie z. B. Leistungsoptimierung
Dateningenieure erstellen das physische Modell vor der endgültigen Designimplementierung. Sie befolgen auch formale Datenmodellierungs-Techniken, um sicherzustellen, dass sie alle Aspekte des Designs abgedeckt haben.
Beispiel für physische Datenmodelle
Angenommen, das Autohaus hat beschlossen, ein Datenarchiv in Amazon S3 Glacier Flexible Retrieval zu erstellen. Ihr physisches Datenmodell beschreibt die folgenden Spezifikationen:
- In Verkauf ist der Verkaufsbetrag ein Float-Datentyp und das Verkaufsdatum ist ein Zeitstempel-Datentyp.
- Bei Kunden ist der Kundenname ein Zeichenfolgen-Datentyp.
- In der Terminologie von S3 Glacier Flexible Retrieval ist ein Tresor der geografische Standort Ihrer Daten.
Ihr physisches Datenmodell enthält auch zusätzliche Details, z. B. in welcher AWS-Region Sie Ihren Tresor erstellen werden. Das physische Datenmodell fungiert somit als Brücke zwischen dem logischen Datenmodell und der endgültigen Technologie-Implementierung.
Welche Arten von Datenmodellierungs-Techniken gibt es?
Datenmodellierungs-Techniken sind die verschiedenen Methoden, mit denen Sie verschiedene Datenmodelle erstellen können. Die Ansätze haben sich im Laufe der Zeit als Ergebnis von Innovationen bei Datenbankkonzepten und Daten-Governance weiterentwickelt. Im Folgenden sind die wichtigsten Arten der Datenmodellierung aufgeführt:
Hierarchische Datenmodellierung
Bei der hierarchischen Datenmodellierung können Sie die Beziehungen zwischen den verschiedenen Datenelementen in einem baumähnlichen Format darstellen. Hierarchische Datenmodelle stellen 1:n-Beziehungen dar, wobei übergeordnete oder Root-Datenklassen mehreren untergeordneten Elementen zugeordnet sind.
Im Beispiel eines Autohauses hätte die übergeordnete Klasse Showrooms beide Entitäten Auto und Verkäufer als untergeordnete Einheiten, da in einem Showroom mehrere Autos und Verkäufer arbeiten.
Graphische Datenmodellierung
Die hierarchische Datenmodellierung hat sich im Laufe der Zeit zur Diagramm-Datenmodellierung entwickelt. Graphische Datenmodelle stellen Datenbeziehungen dar, die Entitäten gleich behandeln. Entitäten können in 1:n- oder n:m-Beziehungen ohne jegliches Konzept einer über- oder untergeordneter Beziehung verknüpft werden.
Beispielsweise kann ein Showroom mehrere Verkäufer haben, und ein Verkäufer kann auch in mehreren Showrooms arbeiten, wenn seine Schicht je nach Standort variiert.
Relationale Datenmodellierung
Relationale Datenmodellierung ist ein beliebter Modellierungsansatz, der Datenklassen als Tabellen visualisiert. Unterschiedliche Datentabellen werden mithilfe von Schlüsseln, die die Entitäts-Beziehung in der realen Welt darstellen, miteinander verbunden oder verknüpft. Sie können relationale Datenbanktechnologie verwenden, um strukturierte Daten zu speichern, und ein relationales Datenmodell ist eine nützliche Methode, um Ihre relationale Datenbankstruktur darzustellen.
Beispielsweise hätte das Autohaus relationale Datenmodelle, die die Tabellen „Verkäufer“ und „Autos“ darstellen, wie hier gezeigt:
| Verkäufer-ID | Name |
| 1 | Jane |
| 2 | John |
| Auto-ID | Automarke |
| C1 | XYZ |
| C2 | ABC |
Verkäufer-ID und Auto-ID sind Primärschlüssel, die einzelne reale Entitäten eindeutig identifizieren. In der Showroom-Tabelle fungieren diese Primärschlüssel als Fremdschlüssel, die die Datensegmente verknüpfen.
| Showroom-ID | Showroom-Name | Verkäufer-ID | Auto-ID |
| S1 | NY Showroom | 1 | C1 |
In relationalen Datenbanken arbeiten Primär- und Fremdschlüssel zusammen, um die Datenbeziehung darzustellen. Die vorstehende Tabelle zeigt, dass Showrooms Verkäufer und Autos haben können.
Entity-Relationship-Datenmodellierung
Entity-Relationship (ER)-Datenmodellierung verwendet formale Diagramme, um die Beziehungen zwischen Entitäten in einer Datenbank darzustellen. Datenarchitekten verwenden mehrere ER-Modellierungstools, um Daten darzustellen.
Objektorientierte Datenmodellierung
Die objektorientierte Programmierung verwendet Datenstrukturen, die als Objekte bezeichnet werden, um Daten zu speichern. Diese Datenobjekte sind Software-Abstraktionen von realen Entitäten. Beispielsweise hätte das Autohaus in einem objektorientierten Datenmodell Datenobjekte wie Kunden mit Attributen wie Name, Adresse und Telefonnummer. Sie würden die Kundendaten so speichern, dass jeder reale Kunde als Kundendatenobjekt dargestellt wird.
Objektorientierte Datenmodelle überwinden viele der Einschränkungen relationaler Datenmodelle und sind in Multimedia-Datenbanken beliebt.
Dimensionale Datenmodellierung
Modernes Computing für Unternehmen verwendet Data-Warehouse-Technologie, um große Datenmengen für die Analytik zu speichern. Sie können dimensionale Datenmodellierungs-Projekte zum Hochgeschwindigkeits-Speichern und -Abrufen von Daten aus einem Data Warehouse verwenden. Dimensionsmodelle verwenden doppelte oder redundante Daten und priorisieren die Leistung gegenüber der Verwendung von weniger Speicherplatz für die Datenspeicherung.
Beispielsweise hat das Autohaus in dimensionalen Datenmodellen Dimensionen wie Auto, Showroom und Zeit. Die Auto-Dimension hat Attribute wie Name und Marke, aber die Showroom-Dimension hat Hierarchien wie Staat, Stadt, Straßenname und Showroom-Name.
Was ist der Datenmodellierungs-Prozess?
Der Datenmodellierungs-Prozess folgt einer Abfolge von Schritten, die Sie wiederholt ausführen müssen, bis Sie ein umfassendes Datenmodell erstellt haben. In jeder Organisation kommen verschiedene Interessengruppen zusammen, um eine vollständige Datenansicht zu erstellen. Obwohl die Schritte je nach Art der Datenmodellierung variieren, ist das Folgende eine allgemeine Übersicht.
Schritt 1: Identifizieren Sie Entitäten und ihre Eigenschaften
Identifizieren Sie alle Entitäten in Ihrem Datenmodell. Jede Entität sollte sich logisch von allen anderen Entitäten unterscheiden und kann Personen, Orte, Dinge, Konzepte oder Ereignisse darstellen. Jede Entität ist einzigartig, weil sie eine oder mehrere einzigartige Eigenschaften hat. Sie können sich in Ihrem Datenmodell Entitäten als Substantive und Attribute als Adjektive vorstellen.
Schritt 2: Identifizieren Sie die Beziehungen zwischen Entitäten
Die Beziehungen zwischen den verschiedenen Entitäten sind das Herzstück der Datenmodellierung. Geschäftsregeln definieren diese Beziehungen zunächst auf konzeptioneller Ebene. Sie können sich Beziehungen als die Wörter in Ihrem Datenmodell vorstellen. Beispielsweise verkauft der Verkäufer viele Autos oder der Showroom beschäftigt viele Verkäufer.
Schritt 3: Identifizieren Sie die Datenmodellierungs-Technik
Nachdem Sie Ihre Entitäten und ihre Beziehungen konzeptionell verstanden haben, können Sie die Datenmodellierungs-Technik bestimmen, die am besten zu Ihrem Anwendungsfall passt. Beispielsweise können Sie relationale Datenmodellierung für strukturierte Daten, aber dimensionale Datenmodellierung für unstrukturierte Daten verwenden.
Schritt 4: Optimieren und Iterieren
Sie können Ihr Datenmodell weiter optimieren, um es an Ihre Technologie- und Leistungsanforderungen anzupassen. Wenn Sie beispielsweise planen, Amazon Aurora und eine strukturierte Abfragesprache (SQL) zu verwenden, platzieren Sie Ihre Entitäten direkt in Tabellen und geben Beziehungen mithilfe von Fremdschlüsseln an. Wenn Sie sich dagegen für die Verwendung von Amazon DynamoDB entscheiden, müssen Sie über Zugriffsmuster nachdenken, bevor Sie Ihre Tabelle modellieren. Da DynamoDB der Geschwindigkeit Priorität einräumt, legen Sie zunächst fest, wie Sie auf Ihre Daten zugreifen, und modellieren dann Ihre Daten in der Form, in der auf sie zugegriffen wird.
Sie werden diese Schritte in der Regel wiederholt wiederholen, wenn sich Ihre Technologie und Anforderungen im Laufe der Zeit ändern.
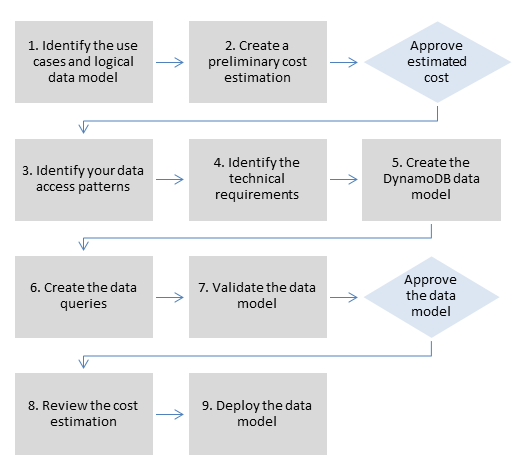
Wie kann AWS mit Datenmodellierung helfen?
Sie können AWS Amplify DataStore auch für eine schnellere und einfachere Datenmodellierung zum Erstellen von Mobil- und Webanwendungen verwenden. Es verfügt über eine visuelle und codebasierte Schnittstelle, um Ihr Datenmodell mit Beziehungen zu definieren, was Ihre Anwendungsentwicklung beschleunigt.
Beginnen Sie mit der Datenmodellierung auf AWS, indem Sie noch heute ein kostenloses Konto erstellen.
Nächste Schritte auf AWS
Sie erhalten sofort Zugriff auf das kostenlose Kontingent von AWS.
Starten Sie mit der Entwicklung in der AWS-Managementkonsole.