Casos de uso de AWS Step Functions
¿Qué se puede automatizar con AWS Step Functions? Obtenga algunas ideas a partir de algunos de los casos de uso más populares a continuación.
AWS Step Functions permite implementar procesos empresariales como una serie de pasos que conforman un flujo de trabajo.
Los pasos individuales del flujo de trabajo pueden invocar una función de Lambda o un contenedor que tenga alguna lógica empresarial, actualizar una base de datos, como DynamoDB, o publicar un mensaje en una cola una vez que ese paso o todo el flujo de trabajo complete su ejecución.
AWS Step Functions dispone de dos opciones de flujo de trabajo: Standard y Express. Si se prevé que el proceso empresarial tardará más de cinco minutos en una sola ejecución, conviene elegir la opción Standard. Algunos ejemplos de flujos de trabajo de larga duración son una canalización de orquestación de extracción, transformación y carga (ETL) o cuando cualquier paso del flujo de trabajo espera la respuesta de un ser humano para pasar al siguiente paso.
Los flujos de trabajo Express son adecuados para los flujos de trabajo que duran menos de cinco minutos. Además, resultan óptimos cuando se trata de un volumen de ejecución elevado, es decir, 100 000 invocaciones por segundo. Puede utilizar Standard o Express de forma separada, o combinarlos de manera que un flujo de trabajo Standard más largo desencadene varios flujos de trabajo Express más cortos que se ejecuten en paralelo.
Orquestación de microservicios
Combine funciones de Lambda para crear una aplicación basada en la web
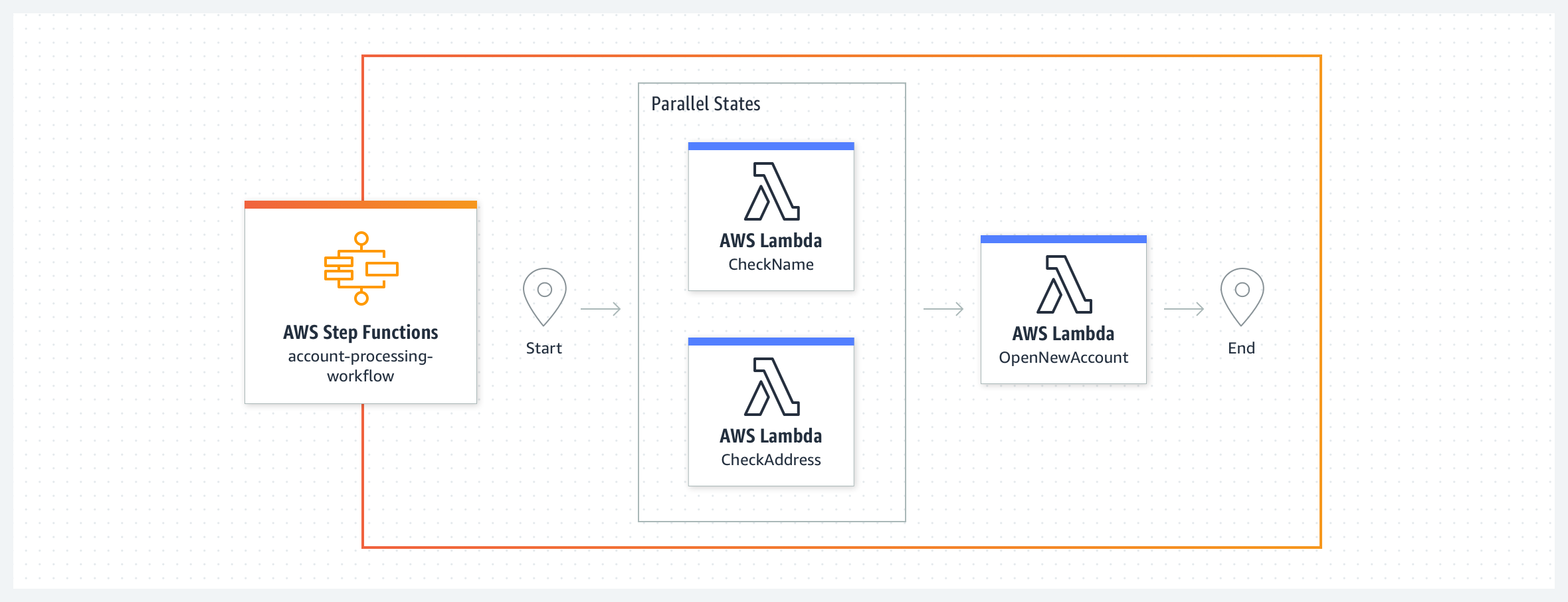
En este ejemplo de sistema bancario sencillo, se crea una nueva cuenta bancaria tras validar el nombre y la dirección del cliente. El flujo de trabajo comienza con dos funciones de Lambda CheckName y CheckAddress que se ejecutan en paralelo como estados de la tarea. Cuando ambas se completan, el flujo de trabajo ejecuta la función de Lambda ApproveApplication (Aprobar solicitud). Se pueden definir las cláusulas de reintento y de captura para gestionar los errores de los estados de las tareas. Es posible utilizar errores predefinidos del sistema o gestionar errores personalizados lanzados por estas funciones Lambda en el flujo de trabajo. Dado que el código del flujo de trabajo se encarga de la gestión de errores, las funciones de Lambda se pueden enfocar en la lógica empresarial y tener menos código. Los flujos de trabajo Express serían más adecuados para este ejemplo, ya que las funciones de Lambda realizan tareas que, en conjunto, tardan menos de cinco minutos, sin dependencias externas.
Combine funciones de Lambda para crear una aplicación basada en la web , con aprobaciones por parte de seres humanos
Es posible que a veces necesite que un humano revise y apruebe o rechace un paso del proceso empresarial de modo que el flujo de trabajo pueda continuar con el siguiente paso. Recomendamos utilizar los flujos de trabajo Standard cuando el flujo de trabajo necesite esperar a un humano o para procesos en los que un sistema externo pueda tardar más de cinco minutos en responder. Aquí se amplía el proceso de apertura de una nueva cuenta con un paso intermedio de notificación al aprobador.El flujo de trabajo comienza con los estados de tarea CheckName (Verificar nombre) y CheckAddress (Verificar dirección) que se ejecutan en paralelo. El siguiente estado ReviewRequired (Revisión requerida) es un estado de elección que tiene dos posibles caminos: enviar un correo electrónico de notificación de SNS al aprobador de la tarea NotifyApprover (Notificar al aprobador) o pasar al estado ApproveApplication (Aprobar la solicitud). El estado de tarea NotifyApprover (Notificar al aprobador) envía un correo electrónico al aprobador y espera una respuesta antes de pasar al siguiente estado de elección “Aprobado”. En función de la decisión del aprobador, la solicitud de crear la cuenta se aprueba o se rechaza mediante funciones de Lambda,

Invoque un proceso empresarial en respuesta a un evento mediante flujos de trabajo Express
En este ejemplo, un evento en un bus personalizado de Eventbridge satisface una regla e invoca un flujo de trabajo de Step Functions como destino. Suponga que dispone de una aplicación de atención al cliente que necesita gestionar las suscripciones de clientes vencidas. Una regla de EventBridge escucha eventos de suscripciones vencidas e invoca un flujo de trabajo de destino como respuesta. El flujo de trabajo de suscripción vencida desactivará todos los recursos que posea la suscripción vencida sin eliminarlos y enviará un correo electrónico al cliente para notificarle que su suscripción ha vencido. Estas dos acciones se pueden realizar en paralelo mediante funciones de Lambda. Al final del flujo de trabajo, se envía un nuevo evento al bus de eventos a través de una función de Lambda en el que se indica que se ha procesado el vencimiento de la suscripción. Para este caso, recomendamos utilizar los flujos de trabajo Express. A medida que la empresa crece y comienza a introducir más eventos en el bus de eventos, la capacidad de invocar 100 000 ejecuciones de flujos de trabajo por segundo con los flujos de trabajo Express resulta sumamente útil. Vea el ejemplo en la práctica con este repositorio de Github.

Seguridad y automatización de las TI
Orqueste una respuesta a incidentes de seguridad para la creación de políticas de IAM
Puede utilizar AWS Step Functions para crear un flujo de trabajo automatizado de respuesta a incidentes de seguridad que incluya un paso de aprobación manual. En este ejemplo, se desencadena un flujo de trabajo de Step Functions al crear una política de IAM. El flujo de trabajo compara la acción de la política respecto a una lista de acciones restringidas que se puede personalizar. El flujo de trabajo revierte la política temporalmente, luego notifica a un administrador y espera a que apruebe o deniegue. Este flujo de trabajo se puede ampliar para remediar automáticamente, por ejemplo, mediante la aplicación de acciones alternativas o la restricción de acciones a ARN específicos. Vea cómo funciona este ejemplo en la práctica aquí.

Responda a eventos operativos de la cuenta de AWS
Puede reducir los gastos generales operativos que conlleva mantener una infraestructura en la nube de AWS al automatizar la forma en que se responde a los eventos operativos de los recursos de AWS. Amazon EventBridge proporciona un flujo casi en tiempo real de eventos del sistema que describen la mayoría de los cambios y notificaciones de los recursos de AWS. A partir de esta secuencia, se pueden crear reglas para dirigir eventos específicos a AWS Step Functions, AWS Lambda y otros servicios de AWS para su posterior procesamiento y acciones automatizadas. En este ejemplo, se desencadena un flujo de trabajo de AWS Step Functions en función de un evento procedente de AWS Health. AWS supervisa de forma proactiva los sitios de repositorios de código más conocidos en busca de claves de acceso de IAM que se hayan expuesto públicamente. Supongamos que una clave de acceso de IAM fue expuesta en GitHub. AWS Health genera un evento AWS_RISK_CREDENTIALS_EXPOSED en la cuenta de AWS relacionado con la clave expuesta. Una regla configurada de Amazon Eventbridge detecta este evento e invoca un flujo de trabajo de Step Functions. Con la ayuda de las funciones de AWS Lambda, a continuación el flujo de trabajo elimina la clave de acceso de IAM expuesta, resume la actividad reciente de la API correspondiente a la clave expuesta y envía el mensaje de resumen a un tema de Amazon SNS para notificar a los suscriptores, en ese orden. Vea cómo funciona este ejemplo en la práctica aquí.

Sincronice datos entre buckets de S3 de origen y destino
Puede utilizar Amazon S3 para alojar un sitio web estático y Amazon CloudFront para distribuir el contenido por todo el mundo. Como propietario de un sitio web, es posible que necesite dos buckets de S3 para subir el contenido del sitio: uno para la fase de preparación y pruebas y otro para la de producción. Desea actualizar el bucket de producción con todos los cambios del bucket de preparación, sin tener que crear un nuevo bucket desde cero cada vez que actualice el sitio web. En este ejemplo, el flujo de trabajo de Step Functions realiza las tareas en dos ciclos paralelos e independientes: un ciclo copia todos los objetos del bucket de origen en el de destino, pero deja fuera los objetos ya presentes en el bucket de destino. El segundo ciclo elimina todos los objetos del bucket de destino que no se encuentren en el bucket de origen. Un conjunto de funciones de AWS Lambda lleva a cabo los pasos individuales: validar la entrada, obtener las listas de objetos de los buckets de origen y destino, y copiar o eliminar objetos por lotes. Vea este ejemplo junto con el código en detalle aquí. Obtenga más información sobre cómo crear ramificaciones paralelas de ejecución en la máquina de estados aquí.

Procesamiento de datos y orquestación de extracción, transformación y carga (ETL)
Cree una canalización de procesamiento de datos para la transmisión de datos
En este ejemplo, Freebird creó una canalización de procesamiento de datos para procesar datos de webhooks de múltiples orígenes en tiempo real y ejecutar funciones de Lambda que modifican los datos. En este caso de uso, los datos de webhook de varias aplicaciones de terceros se envían a través de Amazon API Gateway a una secuencia de datos de Amazon Kinesis. Una función de AWS Lambda extrae datos de esta secuencia de Kinesis y desencadena un flujo de trabajo Express. Este flujo de trabajo sigue una serie de pasos para validar, procesar y normalizar estos datos. Al final, una función de Lambda actualiza el tema de SNS que desencadena mensajes a funciones de Lambda posteriores para realizar los siguientes pasos a través de una cola de SQS. Podría tener hasta 100 000 invocaciones de este flujo de trabajo por segundo para escalar la canalización de procesamiento de datos.

Automatice los pasos de un proceso de extracción, transformación y carga (ETL)
Puede utilizar Step Functions para orquestar todos los pasos de un proceso de ETL, con diferentes orígenes y destinos de datos.
En este ejemplo, el flujo de trabajo de ETL de Step Functions actualiza Amazon Redshift cada vez que hay nuevos datos disponibles en el bucket de S3 de origen. La máquina de estado de Step Functions inicia un trabajo de AWS Batch y supervisa su estado para comprobar si se ha completado o si se han producido errores. El trabajo de AWS Batch obtiene el script .sql del flujo de trabajo de ETL del origen, es decir, Amazon S3, y lo actualiza en el destino, es decir, Amazon Redshift, a través de un contenedor PL/SQL. El archivo .sql contiene el código de SQL de cada paso de la transformación de datos. Puede desencadenar el flujo de trabajo de ETL con un evento de EventBridge o manualmente a través de la CLI de AWS o con los SDK de AWS o incluso mediante un script de automatización personalizado. Puede alertar a un administrador a través de una notificación de SNS que desencadene un correo electrónico en caso de errores en cualquier paso del flujo de trabajo o al final de su ejecución. Este flujo de trabajo de ETL es un ejemplo en el que se pueden utilizar flujos de trabajo Standard. Vea cómo funciona este ejemplo en la práctica aquí. Puede obtener más información sobre cómo enviar un trabajo de AWS Batch a través de un proyecto de muestra aquí.

Ejecute una canalización de extracción, transformación y carga (ETL) con varios trabajos en paralelo
Las operaciones de extracción, carga y transformación (ETL) transforman los datos sin procesar en conjuntos de datos útiles, con lo que los datos se convierten en información procesable.
Puede utilizar Step Functions para ejecutar varios trabajos de ETL en paralelo en los que los conjuntos de datos de origen pueden estar disponibles en distintos momentos, y cada trabajo de ETL se desencadena únicamente cuando su conjunto de datos correspondiente está disponible. Estos trabajos de ETL pueden ser administrados por diferentes servicios de AWS, como AWS, Glue, Amazon EMR, Amazon Athena u otros servicios ajenos a AWS.
En este ejemplo, hay dos trabajos de ETL independientes que se ejecutan en AWS Glue y que procesan un conjunto de datos de ventas y un conjunto de datos de marketing. Una vez que ambos conjuntos de datos se han procesado,un tercer trabajo de ETL combina la salida de los trabajos de ETL anteriores para producir un conjunto de datos combinado. El flujo de trabajo de Step Functions espera hasta que los datos estén disponibles en S3. Mientras que el flujo de trabajo principal se pone en marcha según una programación, se configura un controlador de eventos de EventBridge en un bucket de Amazon S3, de forma que cuando los archivos de los conjuntos de datos de ventas o marketing se cargan en el bucket, la máquina de estados puede activar el trabajo de ETL “ProcessSales Data” (Procesar datos de ventas) o “ProcessMarketingData” (Procesar datos de marketing) en función del conjunto de datos que esté disponible.
Consulte esta arquitectura en detalle aquí para configurar la arquitectura de orquestación de ETL en la cuenta de AWS. Aprenda a administrar un trabajo de AWS Batch desde Step Functions aquí.

Procesamiento de datos a gran escala
Puede utilizar Step Functions para iterar sobre decenas de millones de elementos de un conjunto de datos, como una matriz JSON, una lista de objetos en S3 o un archivo CSV en un bucket de S3. A continuación, podrá procesar los datos en paralelo con alta simultaneidad.
En este ejemplo, el flujo de trabajo de Step Functions utiliza la asignación de estados en modo distribuido para procesar una lista de objetos S3 en un bucket S3. Step Functions itera sobre la lista de objetos y luego lanza miles de flujos de trabajo paralelos, que se ejecutan simultáneamente, para procesar los elementos. Puede utilizar servicios de computación, como Lambda, que permiten escribir código en cualquier lenguaje admitido. También puede elegir entre más de 220 servicios de AWS creados específicamente para incluirlos en el flujo de trabajo de asignación de estados. Una vez finalizadas las ejecuciones de los flujos de trabajo secundarios, Step Functions puede exportar los resultados a un bucket de S3 de modo que estén disponibles para su revisión o para su procesamiento posterior.

Operaciones de Machine Learning
Ejecute un trabajo de ETL y cree, entrene e implemente un modelo de machine learning
En este ejemplo, se ejecuta un flujo de trabajo de Step Functions en una programación activada por EventBridge para que se ejecute una vez al día. El flujo de trabajo comienza por comprobar si hay nuevos datos disponibles en S3. A continuación, realiza un trabajo de ETL para transformar los datos. Posteriormente, entrena e implementa un modelo de machine learning a partir de estos datos con el uso de funciones de Lambda que activan un trabajo de SageMaker y esperan a que se complete antes de que el flujo de trabajo pase al siguiente paso. Por último, el flujo de trabajo activa una función de Lambda para generar predicciones que se guardan en S3. Repase el proceso paso a paso para crear este flujo de trabajo aquí.

Automatice un flujo de trabajo de machine learning mediante el SDK de ciencia de datos de AWS Step Functions
El SDK de ciencia de datos de AWS Step Functions es una biblioteca de código abierto que permite crear flujos de trabajo que procesan y publican modelos de machine learning mediante Amazon SageMaker y AWS Step Functions. El SDK proporciona una API de Python que cubre cada paso de una canalización de machine learning: entrenar, ajustar, transformar, modelar y configurar puntos de conexión. Puede administrar y ejecutar estos flujos de trabajo directamente en Python, y en blocs de notas de Jupyter. El ejemplo que aparece a continuación ilustra los pasos de entrenamiento y transformación de un flujo de trabajo de machine learning. El paso de entrenamiento inicia un trabajo de entrenamiento de Sagemaker y envía los artefactos del modelo a S3. El paso de guardar el modelo crea un modelo en SageMaker que usa los artefactos del modelo procedentes de S3. El paso de transformación inicia un trabajo de transformación de SageMaker. El paso para crear una configuración de punto de conexión define la configuración del punto de conexión en SageMaker. El paso de creación del punto de conexión implementa el modelo entrenado en el punto de conexión configurado. Consulte el bloc de notas aquí.

Procesamiento de contenidos multimedia
Extraiga datos de PDF o imágenes para procesarlos
En este ejemplo, aprenderá a utilizar AWS Step Functions, AWS Lambda y Amazon Textract conjuntamente para digitalizar una factura en PDF con el fin de extraer su texto y datos para procesar un pago. Amazon Textract analiza el texto y los datos de la factura y desencadena un flujo de trabajo de Step Functions a través de SNS, SQS y Lambda para cada finalización satisfactoria del trabajo. El flujo de trabajo comienza con una función de Lambda que guarda en S3 los resultados de los análisis de facturas realizados correctamente. Esto desencadena otra función de Lambda que procesa el documento analizado para ver si se puede procesar el pago de dicha factura y actualiza la información en DynamoDB. Si la factura se puede procesar, el flujo de trabajo comprueba si está aprobada para el pago. En caso contrario, notifica a un revisor a través de SNS para que este apruebe manualmente la factura. Si es aprobada, una función de Lambda archiva la factura procesada y finaliza el flujo de trabajo. Vea este ejemplo junto con el código en detalle aquí.

Divida y transcodifique video mediante paralelización masiva
En este ejemplo, Thomson Reuters creó una solución de transcodificación de video dividida sin servidor mediante AWS Step Functions y AWS Lambda. Necesitaban transcodificar unos 350 videoclips de noticias al día en 14 formatos para cada videoclip, lo más rápidamente posible. La arquitectura utiliza FFmpeg, un codificador de audio y video de código abierto que solo procesa un archivo de contenido multimedia en serie. Con el fin de mejorar el rendimiento para ofrecer la mejor experiencia al cliente, la solución consistió en utilizar AWS Step Functions y Amazon S3 para procesar objetos en paralelo. Cada video se divide en segmentos de 3 segundos, se procesan en paralelo y se juntan al final.
El primer paso es una función de Lambda llamada Localizar fotogramas clave que identifica la información necesaria para fragmentar el vídeo. A continuación, la función de Lambda Dividir video divide el video en función de los fotogramas clave y almacena los segmentos en un bucket de S3. A continuación, cada segmento se procesa en paralelo mediante funciones de Lambda y se coloca en un bucket de destino. La máquina de estados sigue el procesamiento hasta que se procesan todos los segmentos N. A continuación, desencadena una función de Lambda final que concatena los segmentos procesados y almacena el video resultante en un bucket de S3.
Cree una canalización de transcodificación de video sin servidor mediante Amazon MediaConvert
En este ejemplo, aprenderemos cómo AWS Step Functions, AWS Lambda y AWS Elemental MediaConvert se pueden orquestar conjuntamente para lograr capacidades de transcodificación completamente administradas al servicio del contenido bajo demanda. Este caso de uso se aplica a empresas con volúmenes elevados o variables de contenido de video de origen que desean procesar contenido de video en la nube o desean trasladar cargas de trabajo a la nube en el futuro.
La solución de video bajo demanda tiene tres subflujos de trabajo que se activan desde un flujo de trabajo principal de Step Functions:
- Ingestión: se puede tratar de un flujo de trabajo Express. Un archivo de origen depositado en S3 desencadena este flujo de trabajo para la ingesta de datos.
- Procesamiento: este flujo de trabajo examina la altura y la anchura del video y crea un perfil de codificación. Después del procesamiento, se activa un trabajo de codificación a través de AWS Elemental MediaConvert.
- Publicación: el último paso comprueba si los activos están disponibles en los buckets de S3 de destino y notifica al administrador que el trabajo ha finalizado.

Introducción a AWS Step Functions