¿“Burns Cliff”, “Columbia Hills”, ”Endeavour” y “Bonneville Crater” son conocidos en este mundo? ¡Pues sí! Se trata de algunas de las estructuras geográficas que han visitado los rovers de exploración de Marte (Mars Exploration Rover, MER) de la NASA. Con los años, los rovers esconden tesoros de datos interesantes que comprenden imágenes de alta resolución del Planeta Rojo. Ahora, Amazon Simple Workflow Service (Amazon SWF) se suma a algunas de las tecnologías informáticas clave de estas misiones, a fin de permitir a los científicos de la NASA administrar las operaciones críticas de la misión con fiabilidad y procesar con eficacia los conocimientos cada vez más amplios que recopilamos sobre nuestro Universo.
Mars Exploration Rover
El Jet Propulsion Laboratory (JPL) de la NASA utiliza Amazon SWF como parte integrante de varias misiones, entre otras, Mars Exploration Rover (MER) y Carbon in the Arctic Reservoir Vulnerability Experiment (CARVE). Estas misiones generan constantemente grandes volúmenes de datos que han de procesarse, analizarse y almacenarse de manera eficaz y con confianza. Las canalizaciones de procesamiento de datos para operaciones tácticas y análisis científicos implican una ejecución de pasos ordenados a gran escala con amplias oportunidades de comparación entre varias máquinas. Como ejemplos destacan la generación de datos estereoscópicos a partir de pares de imágenes, la unión de panoramas de varios gigapíxeles para sumergir al científico en el terreno de Marte y la división en cuadrículas de estas imágenes de gigapíxeles para que los datos se puedan cargar bajo demanda. Existe una comunidad global de operadores y científicos que utilizan tales datos. Esta comunidad está sometida a plazos ajustados para las operaciones tácticas, incluso plazos de tan solo unas horas. Para satisfacer estas necesidades, los ingenieros de JPL se marcan el objetivo de procesar y difundir las imágenes de Marte en cuestión de minutos.
JPL lleva mucho tiempo almacenando y procesando datos en AWS. La mayor parte de este trabajo se realiza con el marco Polyphony, que es la implementación de referencia de la arquitectura orientada en la cloud de JPL. Ofrece soporte para el aprovisionamiento, el almacenamiento, la monitorización y la orquestación de tareas en relación con el procesamiento de datos en la cloud. El conjunto de herramientas existente de Polyphony para el análisis y el procesamiento de los datos comprendía Amazon EC2 para la capacidad informática, Amazon S3 para la distribución de los datos y el almacenamiento, e implementaciones de Amazon SQS y MapReduce como Hadoop para la ejecución y distribución de tareas. No obstante, faltaba una pieza clave: un servicio de orquestación para administrar con fiabilidad las tareas de grandes y complejos flujos de trabajo.
Si bien las colas ofrecen un enfoque eficaz para distribuir trabajos paralelos de manera masiva, los ingenieros no tardaron en notar deficiencias. La incapacidad de expresar el orden y las dependencias en las colas no les permitía afrontar flujos de trabajo complejos. Los ingenieros de JPL también tuvieron que abordar la duplicación de mensajes al utilizar las colas. Por ejemplo, al unir las imágenes, la duplicación de una tarea de unión de una imagen daría lugar a un procesamiento caro y redundante, por lo que resultaría inútil la costosa capacidad informática adicional utilizada a medida que la canalización avanza hasta su finalización. JPL también tiene numerosos casos de uso que van más allá del procesamiento de datos brutos y que requieren mecanismos para administrar el flujo de control. A pesar de que los ingenieros lograron implementar los flujos de datos con facilidad gracias a MapReduce, les resultó difícil expresar cada paso de la canalización dentro de la semántica del marco. En particular, a medida que aumentaba la complejidad del procesamiento de datos, se enfrentaban a dificultades para representar las dependencias entre los pasos de procesamiento y la administración de los errores de la informática distribuida.
Los ingenieros de JPL identificaron la necesidad de disponer de un servicio de orquestación con las siguientes características:
- Alta disponibilidad: para soportar las operaciones críticas
- Escalabilidad: para facilitar la ejecución paralela y simultánea desde cientos de instancias de Amazon EC2
- Consistencia: una tarea programada debe ejecutarse una vez con una probabilidad muy alta
- Expresión: expresión sencilla de flujos de trabajo complejos para agilizar el desarrollo
- Flexibilidad: la ejecución de los flujos de trabajo no debe limitarse a Amazon EC2 y las tareas deben ser enrutables
- Alto desempeño: las tareas deben programarse con la mínima latencia
Los ingenieros de JPL utilizaron Amazon SWF e integraron el servicio con los canales de Polyphony responsables del procesamiento de datos de las imágenes de Marte para las operaciones tácticas. Han conseguido un control y una visibilidad sin precedentes de la ejecución distribuida de sus canalizaciones. Y lo que es más importante aún, han logrado expresar flujos de trabajo complejos de manera sucinta sin verse obligados a expresar el problema en ningún paradigma específico.
Para prestar soporte en la prueba de campo de rápido movimiento del rover Curiosity, también conocido como el laboratorio científico de Marte, los ingenieros de JPL tuvieron que procesar imágenes, generar imágenes tridimensionales y crear panoramas. Las imágenes tridimensionales requieren un par de imágenes tomadas al mismo tiempo, y generan datos de intervalos que informan al operador táctico sobre la distancia y la dirección desde el receptor móvil hasta los píxeles de las imágenes. Las imágenes izquierda y derecha se pueden procesar en paralelo. No obstante, el procesamiento tridimensional no puede comenzar hasta que no se hayan procesado ambas imágenes. Este flujo de trabajo clásico de separación-unión resulta difícil de expresar con un sistema basado en colas, mientras que para expresarlo con SWF solo se requieren algunas líneas sencillas de código Java junto con anotaciones de AWS Flow Framework.


La generación de panoramas también se implementa como un flujo de trabajo. A efectos tácticos, los panoramas se generan en cada ubicación en que se detiene el rover para hacer fotografías. Por tanto, cada vez que lleva una imagen nueva de una ubicación concreta, la panorámica se aumenta con la información nueva disponible. Habida cuenta de la amplia escala de los panoramas y de la necesidad de generarlos lo más rápido posible, el problema debe dividirse y coordinarse entre varias máquinas. El algoritmo empleado por los ingenieros divide el panorama en varias filas de gran tamaño. La primera tarea del flujo de trabajo consiste en generar cada una de las filas en función de las imágenes disponibles en la ubicación. Tras generar las filas, se reduce su escala a varias resoluciones y se dividen para que puedan utilizarlas los clientes remotos. Gracias al conjunto enriquecido de características de Amazon SWF, los ingenieros de JPL han podido expresar el flujo de esta aplicación como un flujo de trabajo de Amazon SWF.
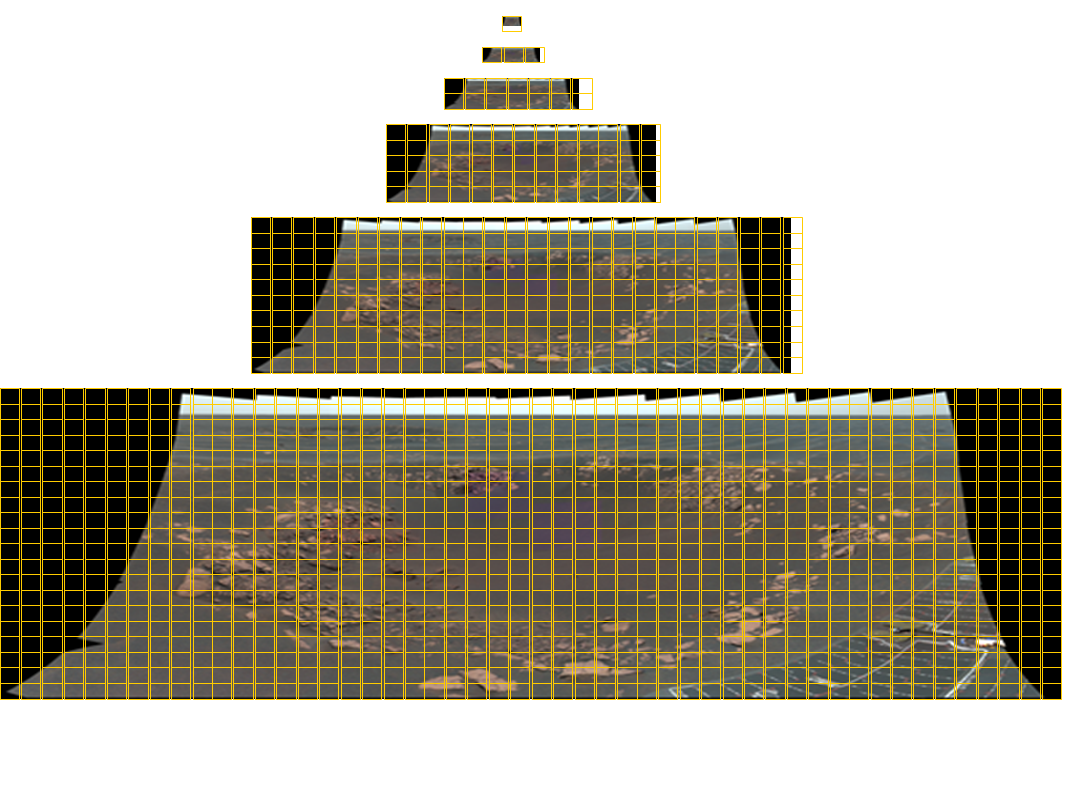
Un mosaico de Opportunity Pancam con un tamaño total de 11 280 × 4 280 píxeles que contiene 77 imágenes en color. Las cuadrículas con seis niveles de detalle resultan necesarias para entregar esta imagen a un visualizador de cualquier tamaño arbitrario. Las líneas de cuadrícula amarillas indican las cuadrículas necesarias para cada imagen. Los panoramas del instrumento Mastcam del laboratorio científico de Marte se componen de hasta 1 296 imágenes con una resolución de casi 2 gigapíxeles. A continuación se muestra la imagen panorámica correspondiente.

Al permitir la instrumentación en la cloud, Amazon SWF brinda al JPL la posibilidad de aprovechar los recursos dentro y fuera de su entorno, así como de distribuir perfectamente la ejecución de la aplicación en la cloud pública, lo cual permite a sus aplicaciones escalar dinámicamente y ejecutarse de forma totalmente distribuida.
Muchos canales de procesamiento de datos de JPL están estructurados como nodos de trabajo automatizados para cargar datos con firewall, nodos de trabajo para procesar los datos en paralelo y nodos de trabajo para descargar los resultados. Los nodos de trabajo de carga y descarga se ejecutan en servidores locales, mientras que los nodos de trabajo de procesamiento de datos se pueden ejecutar en servidores locales y en nodos de Amazon EC2. Mediante el uso de las capacidades de direccionamiento de Amazon SWF, los desarrolladores de JPL han incorporado los nodos de trabajo de forma dinámica en el canal, a la vez que han podido beneficiarse de las características del nodo de trabajo, como la localización de los datos. Esta aplicación de procesamiento también ofrece una alta disponibilidad porque, incluso cuando los nodos de trabajo locales fallan, los nodos de trabajo basados en la cloud continúan avanzando con el procesamiento. Dado que Amazon SWF no restringe la ubicación de los nodos de trabajo, JPL ejecuta los trabajos en varias regiones y también en sus centros de datos locales, a fin de ofrecer la máxima disponibilidad para sistemas críticos. Como Amazon SWF se encuentra disponible en varias regiones, JPL pretende integrar la conmutación por error automática a SWF en todas las regiones.

JPL no solo utiliza Amazon SWF para aplicaciones de procesamiento de datos. De hecho, con la utilización de las capacidades de programación de Amazon SWF, los ingenieros de JPL crearon un sistema distribuido de trabajo Cron que realizaba de manera fiable y puntual las operaciones críticas para la misión. Además de fiabilidad, JPL adquirió una visibilidad centralizada y sin precedentes de estos trabajos distribuidos a través de las capacidades de visibilidad de Amazon SWF disponibles en la consola de administración de AWS. JPL incluso ha creado una aplicación para realizar backups en Amazon S3 de datos importantes de MER. Con los trabajos Cron distribuidos, JPL actualiza las backups y audita la integridad de los datos con la frecuencia que requiere el proyecto. Todos los pasos de esta aplicación, incluidos el cifrado, la carga en Amazon S3, la selección aleatoria de los datos de la auditoría y la auditoría real mediante la comparación de datos locales con Amazon S3, se coordinan de forma fiable mediante Amazon SWF. Además, varios equipos de JPL han migrado rápidamente las aplicaciones existentes para utilizar la orquestación en la cloud, para lo que se han beneficiado del soporte de programación que se ofrece a través de AWS Flow Framework.
JPL continúa utilizando Hadoop para canales de procesamiento de datos sencillos, y Amazon SWF ahora es una opción natural para implementar aplicaciones con dependencias complejas entre los pasos de procesamiento. Los desarrolladores también usan con frecuencia la capacidad de diagnóstico y análisis disponible a través de la consola de administración de AWS para depurar aplicaciones durante el desarrollo y el seguimiento de ejecuciones distribuidas. Con la utilización de AWS, el desarrollo, las pruebas y la implementación de las aplicaciones críticas para la misión que anteriormente suponían meses, ahora se hacen en cuestión de días.