Créer automatiquement un modèle de machine learning
avec Amazon SageMaker Autopilot
Amazon SageMaker est un service entièrement géré permettant aux développeurs et aux scientifiques des données de créer, former et déployer rapidement et facilement des modèles de machine learning.
Grâce à ce didacticiel, vous allez créer automatiquement des modèles de machine learning sans écrire la moindre ligne de code ! Vous allez utiliser Amazon SageMaker Autopilot, un outil AutoML capable de créer automatiquement les meilleurs modèles de machine learning pour la classification et la régression, qui va aussi vous donner un contrôle et une visibilité complets.
Dans ce didacticiel, vous allez apprendre à :
- Créer un compte AWS
- Configurer Amazon SageMaker Studio de façon à avoir accès à Amazon SageMaker Autopilot
- Télécharger un ensemble de données public avec Amazon SageMaker Studio
- Créer une expérience de formation avec Amazon SageMaker Autopilot
- Explorer les différents stades de l'expérience de formation
- Identifier et déployer le meilleur modèle possible à partir de l'expérience de formation
- Effectuer des prédictions avec le modèle déployé
Pour ce tutoriel, vous allez jouer le rôle d'un développeur travaillant dans une banque. Mission vous été confiée de développer un modèle de machine learning pour prédire si un client va s'inscrire pour un certificat de dépôt (CD). Le modèle sera entraîné à partir d'un ensemble de données marketing qui contiennent des informations sur les caractéristiques sociodémographiques des clients, les réactions aux événements marketing et les facteurs externes.
| À propos de ce didacticiel | |
|---|---|
| Durée | 10 minutes |
| Coût | Moins de 10 USD |
| Cas d'utilisation | Machine learning |
| Produits | Amazon SageMaker |
| Public ciblé | Développeur |
| Niveau | Débutant |
| Dernière mise à jour | 12 mai 2020 |
Étape 1. Créer un compte AWS
Le coût de cet atelier est inférieur à 10 USD. Pour en savoir plus, consultez la page Tarification Amazon SageMaker Studio.
Vous possédez déjà un compte ? Se connecter
Étape 2. Configurer Amazon SageMaker Studio
Suivez les étapes ci-dessous pour vous inscrire à Amazon SageMaker Studio et accéder à Amazon SageMaker Autopilot.
Remarque : pour en savoir plus, consultez la page Démarrage avec Amazon SageMaker Studio de la documentation d'Amazon SageMaker.
a. Se connecter à la console Amazon SageMaker.
Remarque : dans le coin supérieur droit, assurez-vous de sélectionner une région AWS dans laquelle Amazon SageMaker Studio est disponible. Pour avoir une liste des régions, consultez la page S'inscrire à Amazon SageMaker Studio.


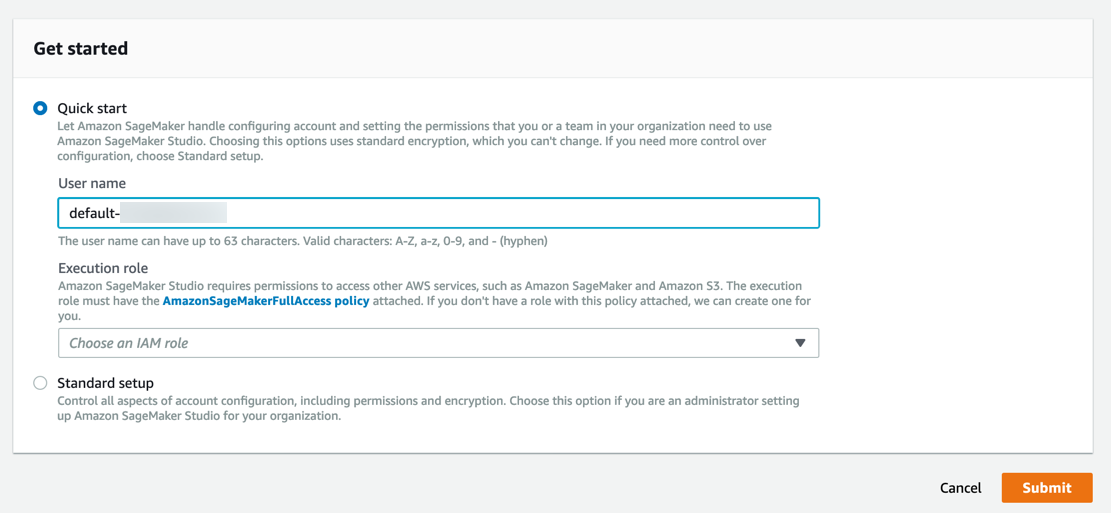
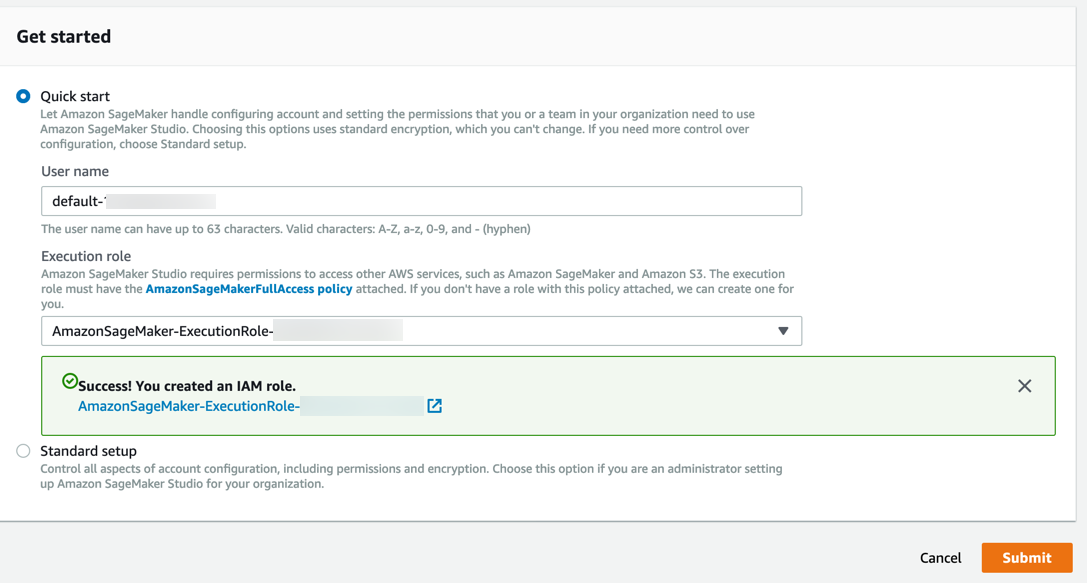
Amazon SageMaker crée un rôle avec les autorisations nécessaires et l'affecte à votre instance.
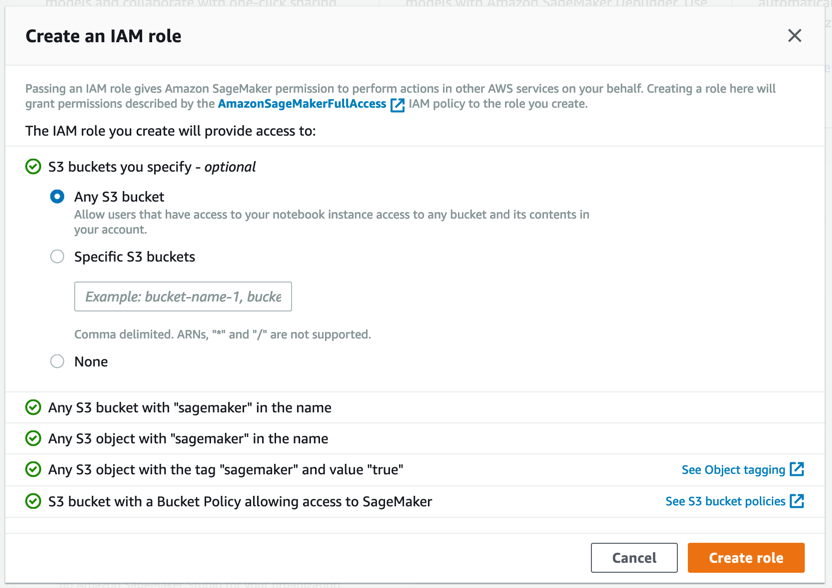
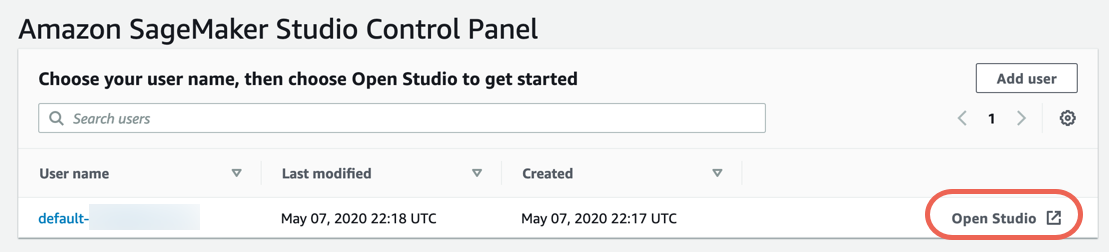
Étape 3. Télécharger l'ensemble de données
Suivez les étapes ci-dessous pour télécharger et explorer l'ensemble de données.
Remarque : pour en savoir plus, consultez la page Visite d'Amazon SageMaker Studio de la documentation d'Amazon SageMaker.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Copiez-collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
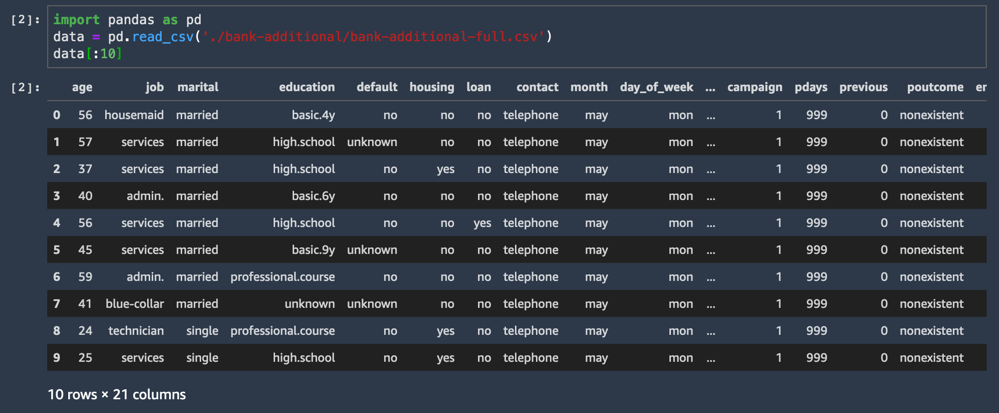
L'ensemble de données CSV se charge et affiche les dix premières lignes.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]L'une des colonnes de l'ensemble de données est intitulée y et représente l'étiquette pour chaque échantillon : ce client a-t-il accepté l'offre ou non ?
À cette étape, les scientifiques des données commencent à explorer les données, créer de nouvelles fonctionnalités et ainsi de suite. Avec Amazon SageMaker Autopilot, vous vous épargnez ces étapes supplémentaires. Il suffit de charger des données tubulaires dans un fichier dont les valeurs sont séparées par des virgules (par exemple, à partir d'un classeur ou d'une base de données) et de choisir la colonne cible pour la prédiction, puis Autopilot crée un modèle prédictif pour vous.
d. Copiez-collez le code suivant dans une nouvelle cellule de code et sélectionnez Exécuter.
Cette étape permet de charger l'ensemble de données CSV dans un compartiment Amazon S3. Vous n'avez pas à créer de compartiment Amazon S3 : Amazon SageMaker crée automatiquement un compartiment par défaut sur votre compte lorsque vous chargez les données.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
Et voilà ! Le code de sortie indique l'URI du compartiment S3 comme suit :
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvGardez une trace de l'URI S3 dans votre bloc-notes. Vous en aurez besoin à l'étape suivante.

Étape 4. Créer une expérience SageMaker Autopilot
Maintenant que vous avez téléchargé et compartimenté votre ensemble de données dans Amazon S3, vous pouvez créer une expérience Amazon SageMaker Autopilot. Une expérience est un recueil de tâches de traitement et de formation en lien avec un même projet de machine learning.
Suivez les étapes suivantes pour créer une nouvelle expérience.
Remarque : pour en savoir plus, consultez la page Créer une expérience Amazon SageMaker Autopilot dans SageMaker Studio de la documentation d'Amazon SageMaker.
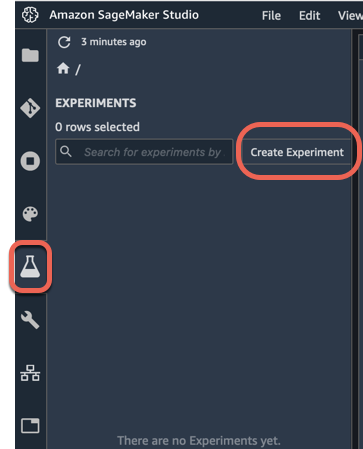
a. Sur le volet de navigation de gauche d'Amazon SageMaker Studio, sélectionnez Expériences (icône symbolisée par un flacon), puis sélectionnez Créer une expérience.
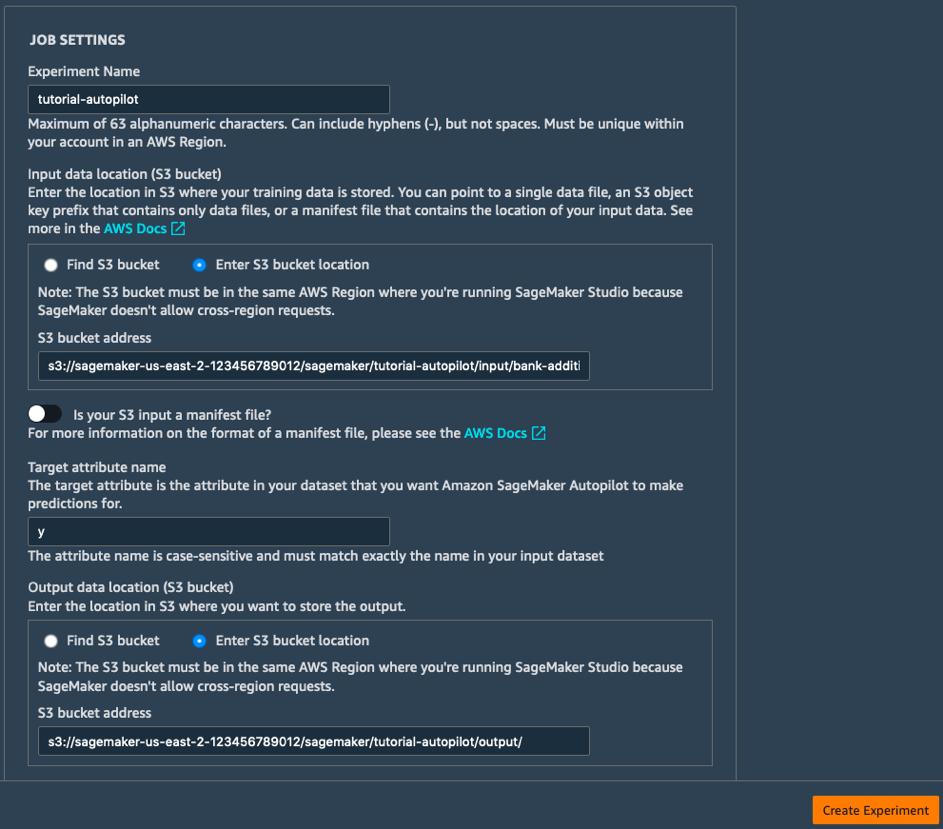
b. Remplissez les champs Paramètres de la tâche comme suit :
- Nom de l'expérience : tutorial-autopilot
- Emplacement S3 des données d'entrée : URI S3 imprimée plus tôt
(e.g. s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Nom de l'attribut cible : y
- Emplacement S3 pour les données de sortie : s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(pensez à bien remplacer [ACCOUNT-NUMBER] par votre propre numéro de compte)
c. Laissez tous les autres paramètres avec leurs valeurs par défaut, puis sélectionnez Créer une expérience.
Bravo ! Et voici comment démarrer une expérience Amazon SageMaker Autopilot ! Ce processus va générer un modèle ainsi que des statistiques que vous pouvez consulter en temps réel pendant l'exécution de l'expérience. Une fois l'expérience terminée, vous pouvez consulter les essais, trier par métrique objective et faire un clic droit pour déployer le modèle pour une utilisation dans d'autres environnements.
Étape 5. Explorer les stades d'une expérience SageMaker Autopilot
Pendant que votre expérience s'exécute, vous pouvez découvrir et explorer les différents stades de l'expérience SageMaker Autopilot.
Cette section donne davantage de détails sur les stades de l'expérience SageMaker Autopilot :
- Analyse des données
- Ingénierie de fonctionnalités
- Ajustement du modèle
Remarque : pour en savoir plus, consultez la section Sortie du bloc-notes SageMaker Autopilot.
Analyse des données
Le stade Analyse des données identifie le type de problème à résoudre (régression linéaire, classification binaire, classification multiclasse). Il donne ensuite dix pipelines candidats. Un pipeline combine une étape de pré-traitement des données (gestion des valeurs manquantes, ingénierie de nouvelles fonctionnalités, etc.) à une étape de formation de modèle avec un algorithme de ML correspondant au type de problème. Une fois cette étape terminée, la tâche passe à l'ingénierie de fonctionnalités.
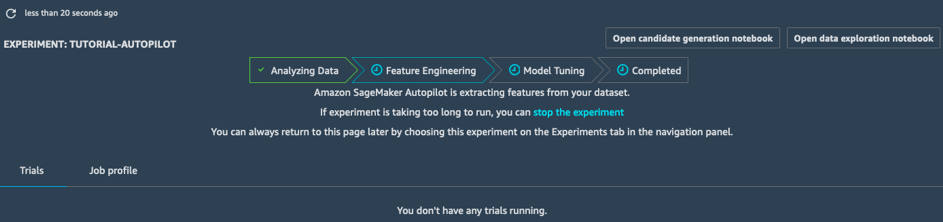
Ingénierie de fonctionnalités
Au stade Ingénierie de fonctionnalités, l'expérience crée des ensembles de données de formation et de validation pour chaque pipeline candidat, et stocke tous les artefacts dans votre compartiment S3. Pendant le stade Ingénierie de fonctionnalités, vous pouvez ouvrir et consulter deux bloc-notes générés automatiquement :
- le bloc-note d'exploration des données, qui contient des informations et des statistiques sur les ensembles de données ;
- et le bloc-note de génération de candidat, qui contient la définition de dix pipelines. En fait, il s'agit d'un bloc-note exécutable : vous pouvez reproduire exactement ce que fait la tâche d'AutoPilot, comprendre la conception des différents modèles et même les ajuster à votre convenance.
Grâce à ces deux bloc-notes, vous pouvez comprendre en détail le pré-traitement des données, ainsi que la conception et l'optimisation des modèles. Cette transparence est une fonctionnalité importante d'Amazon SageMaker Autopilot.
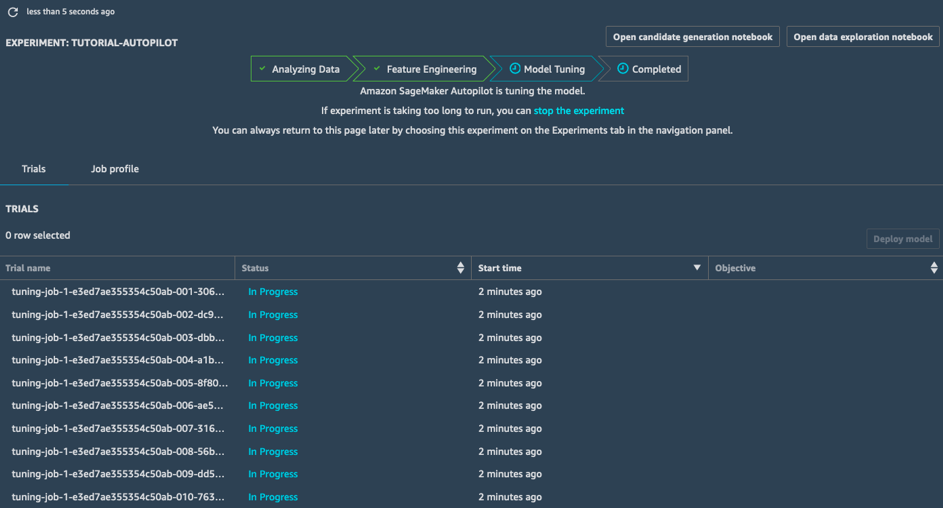
Ajustement du modèle
Au stade Ajustement du modèle, pour chaque pipeline candidat et son ensemble de données pré-traité, SageMaker Autopilot lance une tâche d'optimisation d'hyperparamètre ; les tâches de formation associées explorent un large choix de valeurs d'hyperparamètre et convergent rapidement vers des modèles aux performances accrues.
Une fois au bout de ce stade, la tâche SageMaker Autopilot est terminée. Vous pouvez voir et explorer toutes les tâches dans SageMaker Studio.
Étape 6. Déployer le meilleur modèle
Maintenant que votre expérience est terminée, vous pouvez choisir le meilleur ajustement de modèle et déployer le modèle vers un point de terminaison géré par Amazon SageMaker.
Suivez ces étapes pour choisir le meilleur ajustement et déployer le modèle.
Remarque : pour en savoir plus, consultez la section Choisir et déployer le meilleur modèle.
a. Dans la liste Essais de votre expérience, sélectionnez la flèche en regard de la section Objectif pour trier les tâches d'ajustement dans l'ordre décroissant. La meilleure tâche d'ajustement est mise en avant par une étoile.
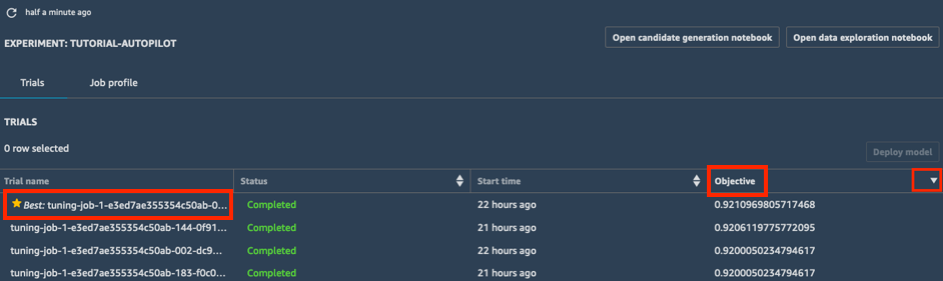
b. Sélectionnez la meilleure tâche d'ajustement (marquée par une étoile) et sélectionnez Déployer un modèle.
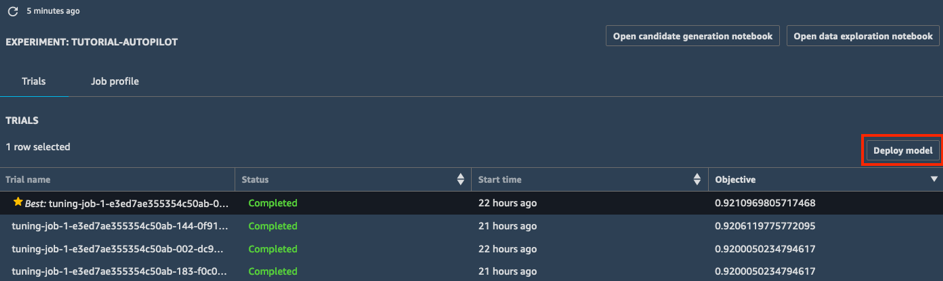
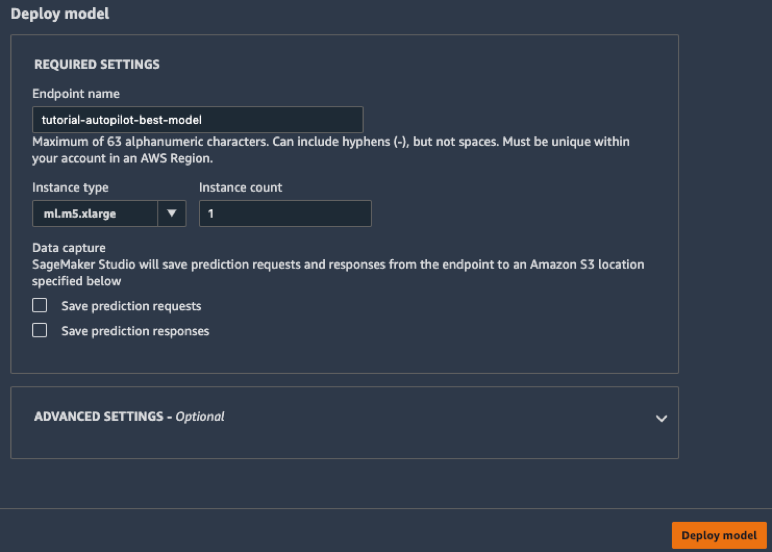
c. Dans la fenêtre Déployer un modèle, nommez votre point de terminaison (par exemple, tutorial-autopilot-best-model) et laissez tous les paramètres avec leurs valeurs par défaut. Sélectionnez Déployer le modèle.
Votre modèle est déployé vers un point de terminaison HTTPS géré par Amazon SageMaker.
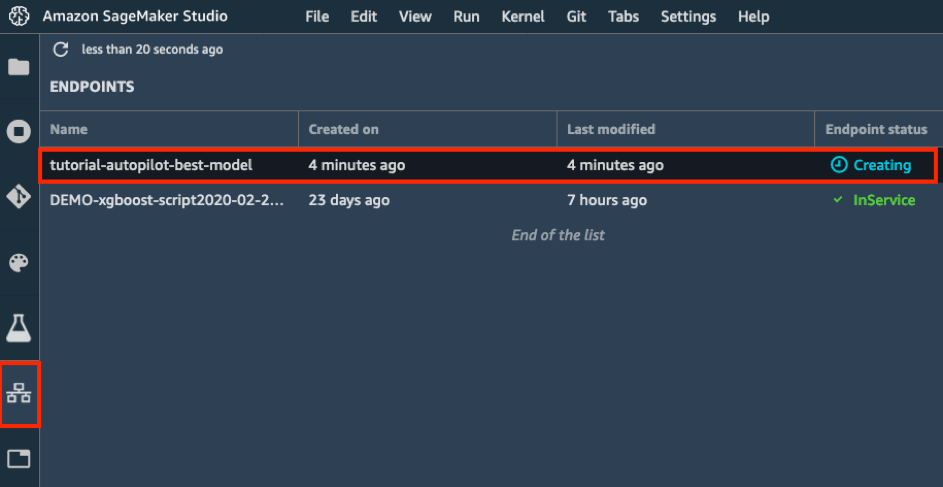
d. Dans la barre d'outils de gauche, sélectionnez l'icône Points de terminaison. Vous pouvez voir la progression de la création de votre modèle, qui peut prendre quelques minutes. Une fois le statut du point de terminaison défini sur En service, vous pouvez envoyer les données et recevoir des prédictions !
Étape 7. Effectuer des prédictions avec votre modèle
Maintenant que le modèle est déployé, vous pouvez prédire les 2 000 premiers échantillons de l'ensemble de données. Pour ce faire, vous devez utiliser invoke_endpoint API dans le kit boto3 SDK. Ce processus consiste à compiler d'importantes métriques de machine learning : pertinence, précision, rappel et score F1.
Suivez ces quelques étapes pour prédire à l'aide de votre modèle.
Remarque : pour en savoir plus, consultez la section Gérer le machine learning avec les expériences Amazon SageMaker.
Dans votre bloc-note Jupyter, copiez-collez le code suivant et sélectionnez Exécuter.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
Vous devrez obtenir le résultat suivant.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
Ce résultat est un indicateur de progression qui montre le nombre d'échantillons prédits !
Étape 8. Nettoyage
À ce stade, vous résiliez les ressources utilisées dans cet atelier.
Important : il est conseillé de résilier les ressources qui ne sont pas utilisées de façon active, afin de réduire les coûts. Des ressources non résiliées peuvent entraîner des frais sur votre compte.
Suppression de votre point de terminaison : dans votre bloc-note Jupyter, copiez-collez le code suivant et sélectionnez Exécuter.
sess.delete_endpoint(endpoint_name=ep_name)Si vous souhaitez nettoyer tous les artefacts de formation (modèles, ensembles de données pré-traités, etc.), copiez-collez le code suivant dans la cellule de code et sélectionnez Exécuter.
Remarque : pensez à bien remplacer ACCOUNT-NUMBER par votre numéro de compte.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Félicitations !
Vous avez créé automatiquement un modèle de machine learning avec la meilleure précision avec Amazon SageMaker Autopilot
Étapes suivantes recommandées
Découvrez Amazon SageMaker Studio
En savoir plus sur Amazon SageMaker Autopilot
Si vous voulez en savoir plus, lisez l’article de blog ou consultez la série de vidéos sur Autopilot.