Mise en route / Ateliers / …
Préparation des données d'entraînement pour le machine learning avec un code minimal
DIDACTICIEL
Présentation
Qu'allez-vous accomplir ?
Avec ce guide, vous allez :
- Visualiser et analyser les données pour comprendre les relations clés
- Appliquer des transformations pour nettoyer les données et générer de nouvelles caractéristiques
- Générer automatiquement des blocs-notes pour des flux de préparation des données reproductibles
Prérequis
Pour pouvoir démarrer ce didacticiel, vous avez besoin de ce qui suit :
- Un compte AWS : si vous n'en avez pas encore, suivez les instructions du guide de mise en route Configuration de votre environnement AWS pour une présentation rapide.
Expérience AWS
Débutant
Durée
30 minutes
Coût de réalisation
Consultez la tarification de Amazon SageMaker pour estimer le coût de ce didacticiel.
Éléments requis
Vous devez être connecté à un compte AWS.
Services utilisés
Amazon SageMaker Data Wrangler
Date de la dernière mise à jour
1 juillet 2022
Implémentation
Étape 1 : configuration de votre domaine Amazon SageMaker Studio
Avec Amazon SageMaker, vous pouvez déployer un modèle visuellement à l'aide de la console ou par programmation à l'aide de SageMaker Studio ou des blocs-notes SageMaker. Dans ce didacticiel, vous déployez le modèle de manière programmatique à l'aide d'un bloc-notes SageMaker Studio, ce qui nécessite un domaine SageMaker Studio.
Un compte AWS ne peut avoir qu'un seul domaine SageMaker Studio par région. Si vous possédez déjà un domaine SageMaker Studio dans la région USA Est (Virginie du Nord), suivez le Guide de configuration de SageMaker Studio pour joindre les politiques AWS IAM requises à votre compte SageMaker Studio, puis sautez l'étape 1 et passez directement à l'étape 2.
Si vous ne disposez pas d'un domaine SageMaker Studio existant, poursuivez avec l'étape 1 pour exécuter un modèle AWS CloudFormation qui crée un domaine SageMaker Studio et ajoute les autorisations requises pour la suite de ce didacticiel.
Choisissez le lien de la pile AWS CloudFormation. Ce lien ouvre la console AWS CloudFormation et crée votre domaine SageMaker Studio ainsi qu'un utilisateur nommé studio-user. Il ajoute également les autorisations requises à votre compte SageMaker Studio. Dans la console CloudFormation, confirmez que USA Est (Virginie du Nord) est la région affichée dans le coin supérieur droit. Le nom de la pile doit être CFN-SM-IM-Lambda-Catalog, et ne doit pas être modifié. Cette pile prend environ 10 minutes pour créer toutes les ressources.
Cette pile repose sur l'hypothèse que vous avez déjà configuré un VPC public dans votre compte. Si vous ne disposez pas d'un VPC public, veuillez consulter la rubrique VPC with a single public subnet (VPC avec un seul sous-réseau public) pour savoir comment créer un VPC public.

Sélectionnez I acknowledge that AWS CloudFormation might create IAM resources (J'accepte qu'AWS CloudFormation puisse créer des ressources IAM), puis choisissez Create stack (Créer la pile).

Dans le volet CloudFormation, choisissez Stacks (Piles). Il faut environ 10 minutes pour que la pile soit créée. Lorsque la pile est créée, son statut passe de CREATE_IN_PROGRESS (Création en cours) à CREATE_COMPLETE (Création terminée).

Étape 2 : création d'un flux SageMaker Data Wrangler
SageMaker Data Wrangler accepte les données provenant d'une grande variété de sources, notamment Amazon S3, Amazon Athena, Amazon Redshift, Snowflake et Databricks. Au cours de cette étape, vous créez un nouveau flux SageMaker Data Wrangler en utilisant le jeu de données sur le risque de crédit allemand UCI stocké dans Amazon S3. Ce jeu de données contient des informations démographiques et financières sur les individus ainsi qu'une étiquette indiquant le niveau de risque de crédit de l'individu.
Saisissez SageMaker Studio dans la barre de recherche de la console, puis choisissez SageMaker Studio.

Choisissez USA Est (Virginie du Nord) dans la liste déroulante Region (Région) située dans le coin supérieur droit de la console SageMaker. Pour Launch app (Lancer l'application), sélectionnez Studio pour ouvrir SageMaker Studio à l'aide du profil studio-user.

Ouvrez l'interface SageMaker Studio. Dans la barre de navigation, choisissez File (Fichier), New (Nouveau), Data Wrangler Flow (Flux Data Wrangler).

Dans l'onglet Import (Import), sous Import data (Importer des données), choisissez Amazon S3.
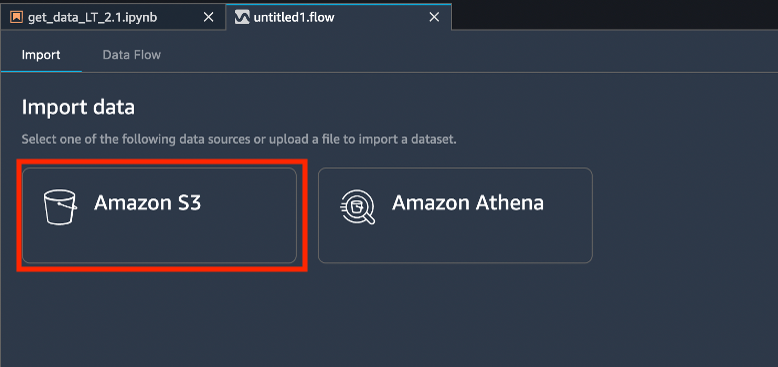
Dans le champ du chemin de l'URI S3, saisissez s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv, puis sélectionnez Go (Aller). Sous Object name (Nom de l'objet), cliquez sur german_credit_data.csv, puis choisissez Import (Importer) .

Étape 3 : établissement du profil des données
Au cours de cette étape, vous utilisez SageMaker Data Wrangler pour évaluer la qualité du jeu de données entraîné. Vous pouvez utiliser la fonctionnalité Quick Model (Modèle rapide) pour estimer approximativement la qualité de prédiction attendue et le pouvoir prédictif des caractéristiques de votre jeu de données.
Dans l'onglet Data Flow (Flux de données), dans le diagramme de flux de données, choisissez l'icône +, Add analysis (Ajouter une analyse).
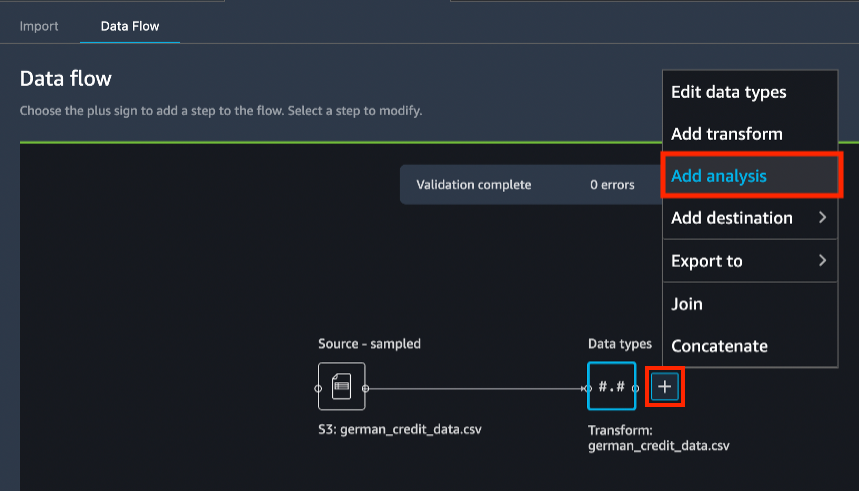
Dans le panneau Create analysis (Créer une analyse), pour Analysis type (Type d'analyse), sélectionnez Histogram (Histogramme).
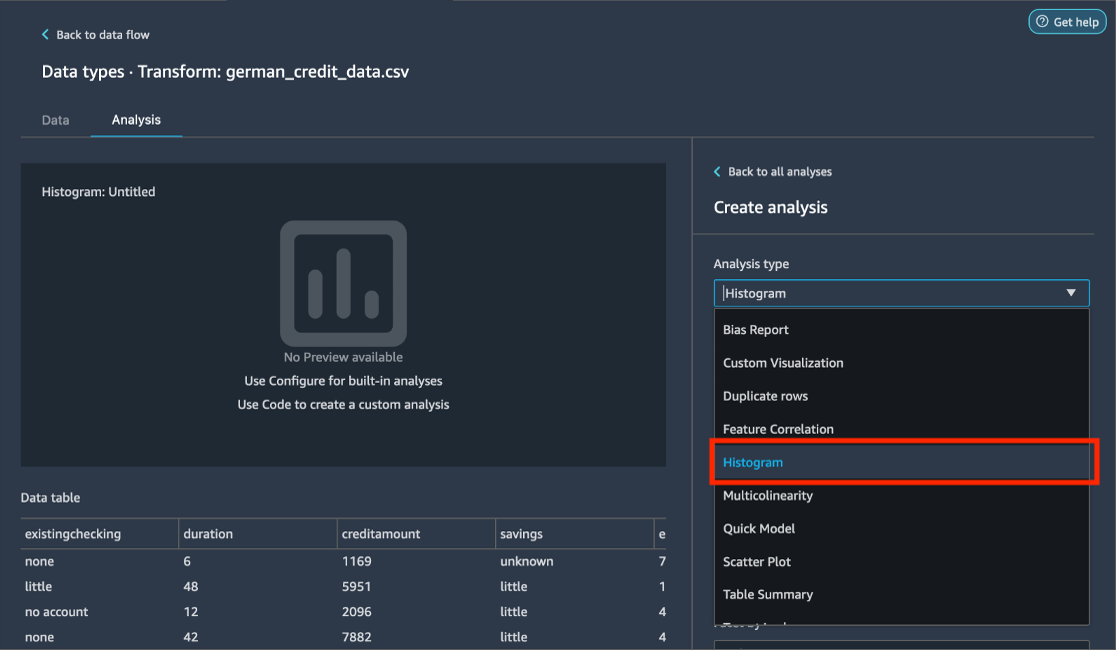
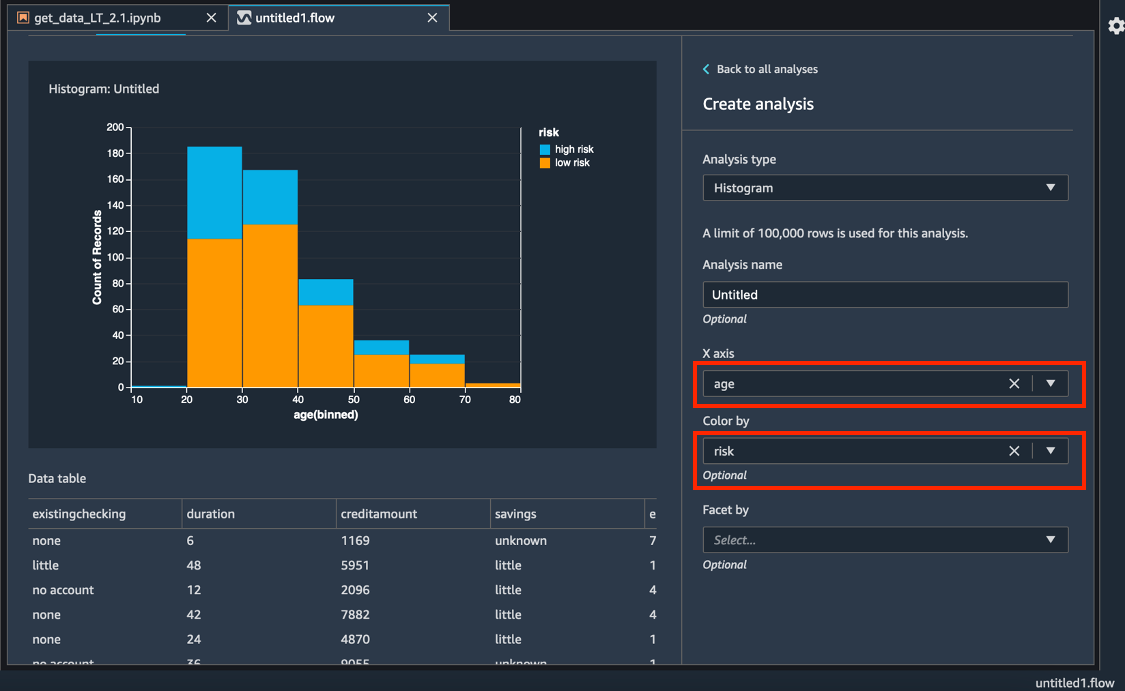
Pour X axis (Axe des X), sélectionnez age (âge).
Pour Color by (Couleur par), sélectionnez risk (risque).
Choisissez Preview (Aperçu) pour générer un histogramme du champ de credit risk (risque de crédit), avec un code couleur par tranche d'âge.
Choisissez Save (Enregistrer) pour sauvegarder cette analyse dans le flux.
Pour comprendre dans quelle mesure le jeu de données est adapté pour entraîner un modèle qui prédit la variable cible risk (risque), exécutez l'analyse Quick Model (Modèle rapide). Dans l'onglet Analysis (Analyse), choisissez Create new analysis (Créer une analyse).
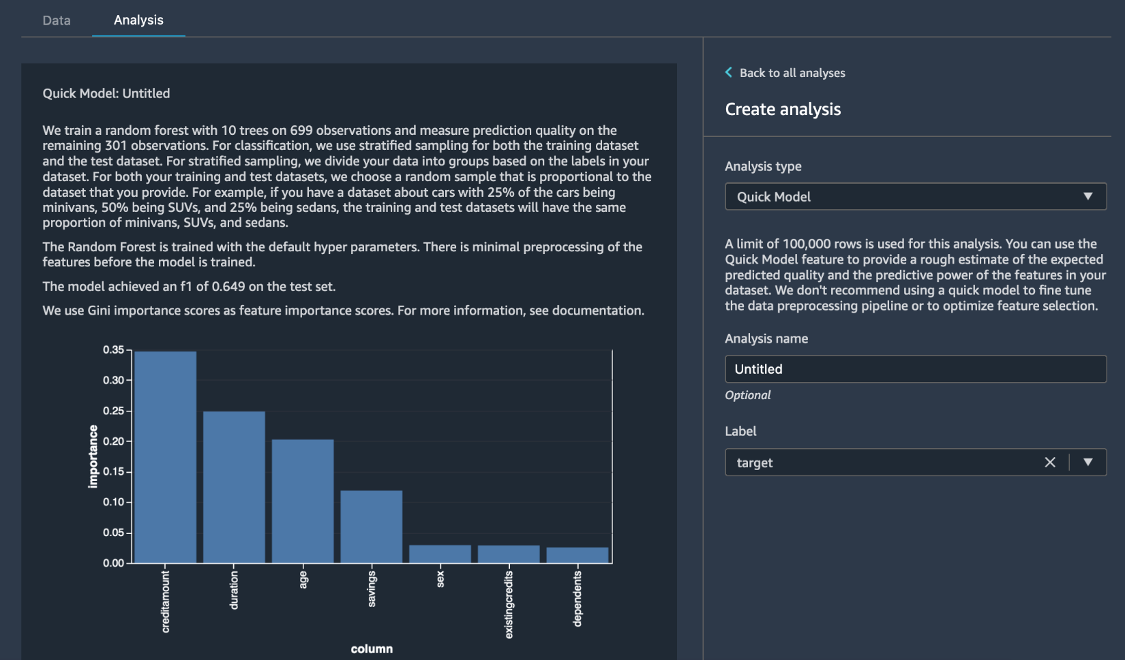
Dans le panneau Create analysis (Créer une analyse), pour Analysis type (Type d'analyse), sélectionnez Quick Model (Modèle rapide). Pour Label (Étiquette), sélectionnez risk (risque), puis choisissez Preview (Aperçu). Le volet Quick Model (Modèle rapide) présente un bref aperçu du modèle utilisé et quelques statistiques de base, notamment le score F1 et l'importance des caractéristiques, pour vous aider à évaluer la qualité du jeu de données. ChoisissezSave (Enregistrer).
Étape 4 : ajout de transformations au flux de données
SageMaker Data Wrangler simplifie le traitement des données en fournissant une interface visuelle avec laquelle vous pouvez ajouter une grande variété de transformations pré-créées. Vous pouvez également écrire vos transformations personnalisées à l'aide de SageMaker Data Wrangler. Au cours de cette étape, vous aplatissez les données de chaînes complexes, vous encodez les catégories, vous renommez les colonnes et vous supprimez les colonnes inutiles à l'aide de l'éditeur visuel. Vous divisez ensuite la colonne status_sex (statut sexe) en deux nouvelles colonnes, marital_status (état civil) et sex (sexe).
Pour naviguer vers le diagramme de flux de données, choisissez Data flow (Flux de données).

Sur le diagramme de flux de données, choisissez l'icône +, Add transform (Ajouter une transformation).

Dans le volet ALL STEPS (TOUTES LES ÉTAPES), sélectionnez Add step (Ajouter une étape).

Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Search and edit (Rechercher et modifier), qui est une transformation utilisée pour manipuler des données de type chaîne.

Dans le volet SEARCH AND EDIT (RECHERCHER ET MODIFIER), pour Transform (Transformer), sélectionnez Split string by delimiter (Diviser la chaîne par le délimiteur). Pour Input columns (Colonnes d'entrée), sélectionnez status_sex. Dans la case Delimiter (Délimiteur), entrez le symbole :. Dans la Output column (Colonne de sortie), saisissez vec. Choisissez Preview (Aperçu), puis Add (Ajouter).
Cette transformation crée une colonne appelée vec à la fin de la trame de données en divisant la colonne status_sex. La colonne status_sex contient des chaînes de caractères délimitées par des deux-points, et la nouvelle colonne vec contient des vecteurs délimités par des virgules.

Pour diviser la colonne vec et créer deux nouvelles colonnes, sex_split_0 et sex_split_1 :
Sous ALL STEPS (TOUTES LES ÉTAPES), choisissez + Add step (Ajouter une étape).
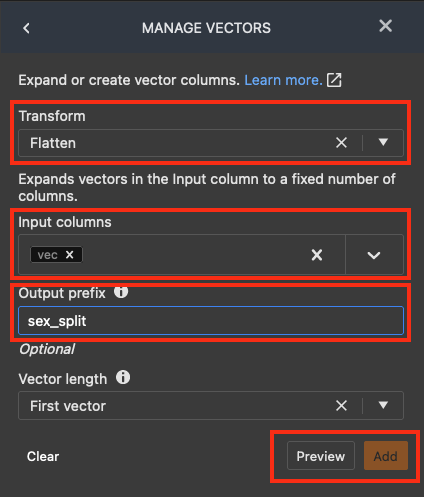
Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Manage vectors (Gérer les vecteurs).
Dans le volet MANAGE VECTORS (GÉRER LES VECTORS), pour Transform (Transformer), sélectionnez Flatten (Aplatir). Pour Input columns (Colonnes d'entrée), sélectionnez vec. Pour output_prefix, saisissez sex_split.
Choisissez Preview (Aperçu), puis Add (Ajouter).
Pour renommer les colonnes créées par la transformation de division :
Dans le volet ALL STEPS (TOUTES LES ÉTAPES), sélectionnez + Add step (Ajouter une étape).
Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Manage columns (Gérer les colonnes).
Dans le volet MANAGE COLUMNS (GÉRER LES COLONNES), pour Transform (Transformer), sélectionnez Rename column (Renommer la colonne). Pour Input column, sélectionnez sex_split_0. Dans la case New name (Nouveau nom), enter sex (sexe).
Choisissez Preview (Aperçu), puis Add (Ajouter).
Répétez cette procédure pour renommer sex_split_1 en marital_status (état civil).

Étape 5 : ajout de l'encodage catégoriel
Au cours de cette étape, vous créez une cible de modélisation et encodez les variables catégorielles. L'encodage catégoriel transforme les catégories de types de données de type chaîne en étiquettes numériques. Il s'agit d'une tâche de prétraitement courante, car les étiquettes numériques peuvent être utilisées dans une grande variété de types de modèles.
Dans le jeu de données, la classification du risque de crédit est représentée par les chaînes high risk (risque élevé) et low risk (risque faible). Au cours de cette étape, vous convertissez cette classification en une représentation binaire, 0 ou 1.
Dans le volet ALL STEPS (TOUTES LES ÉTAPES), sélectionnez + Add step (Ajouter une étape). Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Encode categorical (Encoder de manière catégorielle). SageMaker Data Wrangler propose trois types de transformation : encodage ordinal, encodage One hot et encodage par similarité. Dans le volet ENCODE CATEGORICAL (ENCODER DE MANIÈRE CATÉGORIELLE), pour Transform (Transformer), laissez Ordinal encode (Encodage ordinal) par défaut. Pour Input columns (Colonnes d'entrée), sélectionnez risk (risque). Dans la Output column (Colonne de sortie), saisissez target (cible). Ignorez la case Invalid handling strategy (Stratégie de traitement non valide) pour ce didacticiel. Choisissez Preview (Aperçu), puis Add (Ajouter).

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

Utilisez la transformation Encode categorical (Encoder de manière catégorielle) pour encoder les colonnes restantes, housing (logement), job (tâche), sex (sexe) et marital_status (état civil) comme suit : sous ALL STEPS (TOUTES LES ÉTAPES), choisissez + Add Step (Ajouter une étape). Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Encode categorical (Encoder de manière catégorielle). Dans le volet ENCODE CATEGORICAL (ENCODER DE MANIÈRE CATÉGORIELLE), pour Transform (Transformer), laissez Ordinal encode (Encodage ordinal) par défaut. Pour Input columns (Colonnes d'entrée), sélectionnez housing (logement), job (tâche), sex (sexe) et marital_status (état civil). Laissez la Output column (Colonne de sortie) vide afin que les valeurs codées remplacent les valeurs catégorielles. Choisissez Preview (Aperçu), puis Add (Ajouter).

Pour mettre à l'échelle la colonne numérique creditamount (montant du crédit), appliquez un échelonneur au montant du crédit pour normaliser la distribution des données dans cette colonne : dans le volet ALL STEPS (TOUTES LES ÉTAPES), choisissez + Add Step (Ajouter une étape). Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Process numeric (Traiter les données numériques). Pour Scaler (Échelonneur), sélectionnez l'option par défaut Standard scaler (Échelonneur standard). Pour Input columns (Colonnes d'entrée), sélectionnez creditamount (montant du crédit). Choisissez Preview (Aperçu), puis Add (Ajouter).


Pour déposer les colonnes originales que vous avez transformées : sous le volet ALL STEPS (TOUTES LES ÉTAPES), choisissez + Add step (Ajouter une étape). Dans la liste ADD TRANSFORM (AJOUTER UNE TRANSFORMATION), choisissez Manage columns (Gérer les colonnes). Dans le volet MANAGE COLUMNS (GÉRER LES COLONNES), pour Transform (Transformer), sélectionnez Drop column (Supprimer la colonne). Pour Columns to drop (Colonnes à supprimer), sélectionnez status_sex, existingchecking, employmentsince, risk, et vec. Choisissez Preview (Aperçu), puis Add (Ajouter).

Étape 6 : exécution d'une vérification du biais des données
Au cours de cette étape, vérifiez l'absence de biais dans vos données à l'aide d'Amazon SageMaker Clarify, qui vous offre une meilleure visibilité sur vos données d'entraînement et vos modèles afin que vous puissiez identifier et limiter les biais et expliquer les prédictions.
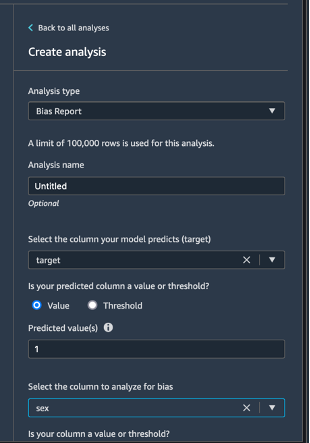
Choisissez Data flow (Flux de données) dans le coin supérieur gauche pour revenir au diagramme de flux de données. Choisissez l'icône +, Add analysis (Ajouter une analyse). Dans le panneau Create analysis (Créer une analyse), pour Analysis type (Type d'analyse), sélectionnez Bias Report (Rapport des biais). Pour Analysis name (Nom de l'analyse), saisissez n'importe quel nom. Pour Select the column your model predicts (target) (Sélectionnez la colonne que votre modèle prédit [cible]), sélectionnez target (cible). Laissez la case à cocher Value (Valeur) sélectionnée. Dans la case Predicted value(s) (Valeur(s) prédite(s)), saisissez 1. Pour Select the column to analyze for bias (Sélectionner la colonne à analyser pour le biais), sélectionnez sex (sexe). Pour Choose bias metrics (Choisir les métriques de biais), conservez les sélections par défaut. Choisissez Check for bias (Vérifier les biais).
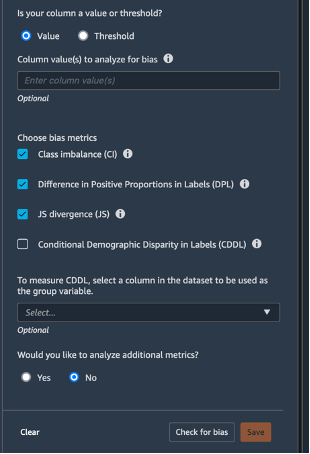
Après quelques secondes, SageMaker Clarify génère un rapport qui indique les résultats obtenus par les colonnes cibles et les colonnes de test pour un certain nombre de métriques liées aux biais, notamment Class Imbalance (CI) (Déséquilibre de classe) et Difference in Positive Proportions in Labels (DPL) (Différence de proportions positives dans les étiquettes). Dans ce cas, les données sont légèrement biaisées en termes de sexe (-0,38), et peu biaisées en termes d'étiquettes (0,075). Sur la base de ce rapport, vous pourriez envisager une méthode de correction des biais, comme l'utilisation de la transformation SMOTE intégrée de SageMaker Data Wrangler. Pour les besoins de ce didacticiel, ignorez l'étape de remédiation. Choisissez Save (Enregistrer) pour sauvegarder le rapport de biais dans le flux de données.

Étape 7 : export de votre flux de données
Exportez votre flux de données vers un bloc-notes Jupyter pour exécuter les étapes en tant que tâches de traitement SageMaker. Ces étapes traitent les données selon le flux de données que vous avez défini et stockent les résultats dans Amazon S3 ou Amazon SageMaker Feature Store.
Dans le diagramme de flux de données, cliquez sur l'icône +, Export to (Exporter vers), Amazon S3 (via Jupyter Notebook) (Amazon S3 [via bloc-notes Jupyter]). Cela crée un bloc-notes dans SageMaker Studio où vous pouvez exécuter les tâches de traitement SageMaker générées afin de créer le jeu de données transformé. Exécutez ce bloc-notes pour stocker les résultats dans le compartiment S3 par défaut.



Étape 8 : nettoyage des ressources
Une bonne pratique consiste à supprimer les ressources que vous n'utilisez plus afin de ne pas encourir de frais imprévus.
Pour supprimer le compartiment S3, procédez comme suit :
- Ouvrez la console Amazon S3. Sur la barre de navigation, choisissez Buckets (Compartiments), sagemaker-<votre-région>-<votre-identifiant-de-compte>, puis cochez la case à côté de data_wrangler_flows. Puis choisissez Delete (Supprimer).
- Dans la boîte de dialogue Delete objects (Supprimer des objets), vérifiez que vous avez sélectionné le bon objet à supprimer et saisissez permanently delete (supprimer définitivement) dans la case de confirmation des Permanently delete objects (Supprimer définitivement des objets).
- Une fois que cette opération est terminée et que le compartiment est vide, vous pouvez supprimer le compartiment sagemaker-<votre-région>-<votre-identifiant-de-compte> en suivant à nouveau la même procédure.

Le noyau de Science des données utilisé pour exécuter l'image du bloc-notes dans ce didacticiel accumule les charges jusqu'à ce que vous arrêtiez le noyau ou que vous effectuiez les étapes suivantes pour supprimer les applications. Pour en savoir plus, veuillez consulter la rubrique Shut Down Resources (Arrêt des ressources) dans le Guide du développeur Amazon SageMaker.
Pour supprimer les applications SageMaker Studio, procédez comme suit : dans la console SageMaker Studio, choisissez studio-user, puis supprimez toutes les applications répertoriées sous Apps (Applications) en choisissant Delete app (Supprimer l'application). Attendez que le Status (Statut) de l'état passe à Deleted (Supprimé).

Si vous avez utilisé un domaine SageMaker Studio existant à l'étape 1, ignorez le reste de l'étape 8 et passez directement à la section de conclusion.
Si vous avez exécuté le modèle CloudFormation à l'étape 1 pour créer un domaine SageMaker Studio, poursuivez les étapes suivantes pour supprimer le domaine, l'utilisateur et les ressources créés par le modèle CloudFormation.
Pour ouvrir la console CloudFormation, saisissez CloudFormation dans la barre de recherche de la console AWS, puis choisissez CloudFormation dans les résultats de la recherche.

Dans le volet CloudFormation, choisissez Stacks (Piles). Dans la liste déroulante Status (Statut), sélectionnez Active (Actif). Sous Stack name (Nom de la pile), choisissez CFN-SM-IM-Lambda-Catalog pour ouvrir la page des détails de la pile.

Sur la page de détails de la pile CFN-SM-IM-Lambda-catalog, choisissez Delete (Supprimer) pour supprimer la pile ainsi que les ressources qu'elle a créées à l'étape 1.

Conclusion
Vous avez utilisé avec succès Amazon SageMaker Data Wrangler pour préparer des données en vue d'entraîner un modèle de machine learning. SageMaker Data Wrangler propose plus de 300 transformations de données préconfigurées, telles que la conversion du type de colonne, l'encodage one-hot, l'imputation des données manquantes avec la moyenne ou la médiane, la remise à l'échelle des colonnes et l'intégration de la date et de l'heure, afin que vous puissiez transformer vos données dans des formats qui peuvent être utilisés efficacement pour les modèles sans écrire une seule ligne de code.
Entraîner un modèle de deep learning
Créer un modèle ML automatiquement
Trouver d'autres didacticiels pratiques