Cas d'utilisation d'AWS Step Functions
Que pouvez-vous automatiser avec AWS Step Functions ? Vous trouverez ci-dessous quelques idées parmi les cas d'utilisation les plus populaires.AWS Step Functions vous permet de mettre en œuvre un processus métier sous la forme d'une série d'étapes qui constituent un flux de travail.
Les différentes étapes du flux de travail peuvent invoquer une fonction Lambda ou un conteneur qui possède une certaine logique métier, mettre à jour une base de données telle que DynamoDB ou publier un message dans une file d'attente une fois que cette étape que l'ensemble du flux de travail a terminé son exécution.
AWS Step Functions propose deux options de flux de travail – Standard et express. Lorsque votre processus métier doit prendre plus de cinq minutes pour une seule exécution, vous devez choisir standard. Un pipeline d'orchestration ETL ou le fait qu'une étape de votre flux de travail attende la réponse d'un humain pour passer à l'étape suivante sont des exemples de flux de travail à long terme.
Les flux de travail express sont adaptés aux flux de travail qui prennent moins de cinq minutes, et sont idéaux lorsque vous avez besoin d'un volume d'exécution élevé, c'est-à-dire 100 000 invocations par seconde. Vous pouvez utiliser soit standard, soit express de manière distincte, ou les combiner de telle sorte qu'un flux de travail standard plus long déclenche plusieurs flux de travail express plus courts qui s'exécutent en parallèle.
Orchestration de microservices
Combiner des fonctions Lambda pour créer une application web
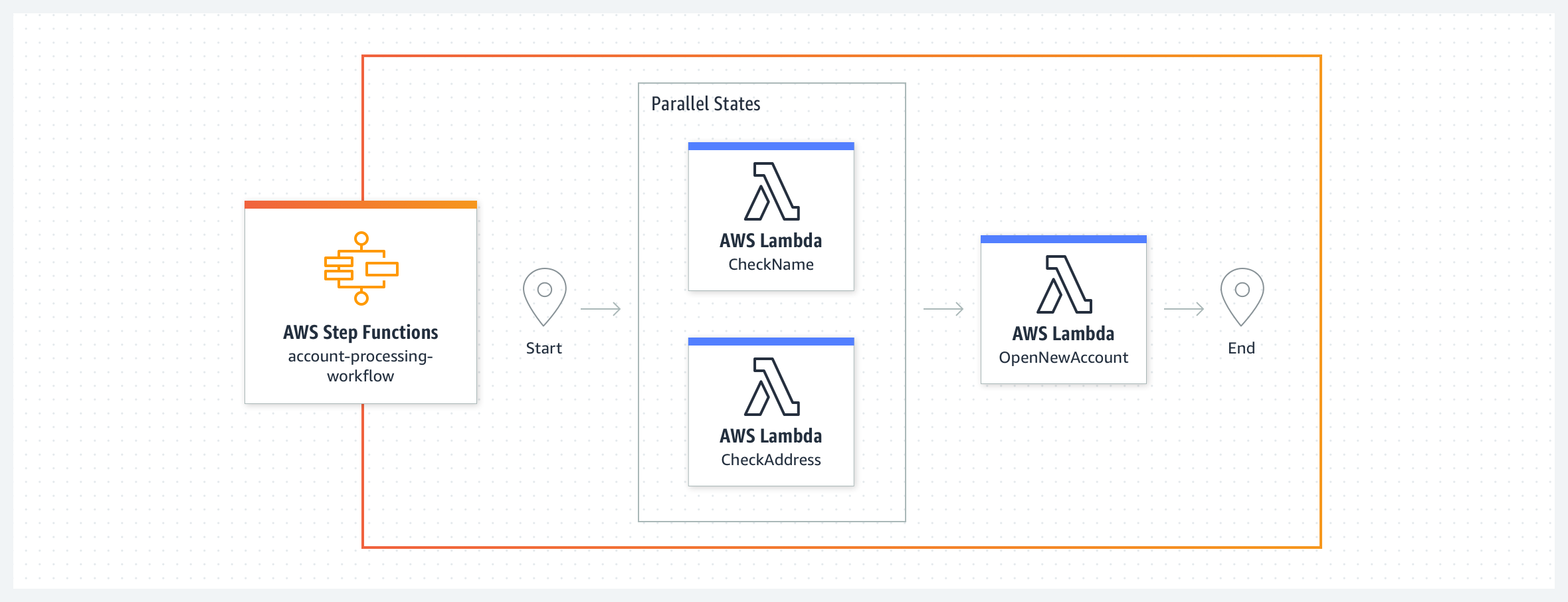
Dans cet exemple de système bancaire simple, un nouveau compte bancaire est créé après validation du nom et de l'adresse du client. Le flux de travail commence avec deux fonctions Lambda, CheckName et CheckAddress, qui s'exécute en parallèle en tant qu'états de tâche. Une fois que les deux fonctions sont terminées, le flux de travail exécute la fonction Lambda ApproveApplication. Vous pouvez définir des clauses de nouvelle tentative et de capture pour gérer les erreurs provenant des états de la tâche. Vous pouvez utiliser les erreurs systèmes prédéfinies ou gérer les erreurs personnalisées déclenchées par ces fonctions Lambda dans votre flux de travail. Puisque votre code de flux de travail prend en charge la gestion des erreurs, les fonctions Lambda peuvent se concentrer sur la logique métier et avoir moins de code. Les flux de travail express correspondent mieux à cet exemple, car les fonctions Lambda exécutent des tâches qui, ensemble, prennent moins de cinq minutes, sans aucune dépendance externe.
Combiner des fonctions Lambda pour créer une application web – avec une approbation humaine
Parfois, vous pouvez avoir besoin que quelqu'un examine et approuve ou rejette une étape du processus métier afin que le flux de travail puisse passer à l'étape suivante. Nous vous recommandons d'utiliser les flux de travail standard lorsque votre flux de travail doit attendre l'action d'une personne ou pour les processus dans lesquels un système externe pourrait prendre plus de cinq minutes pour répondre. Ici, nous étendons le processus d'ouverture d'un nouveau compte avec une étape de notification de l'approbateur entre les deux. Le flux de travail commence avec les états de tâche CheckName et CheckAddress qui s'exécutent en parallèle. L'état suivant, ReviewRequired, est un état de choix qui offre deux possibilités : soit envoyer un e-mail de notification SNS à l'approbateur dans la tâche NotifyApprover, soit passer à l'état ApproveApplication. L'état de tâche NotifyApprover envoie un e-mail à l'approbateur, et attend une réponse avant de passer à l'état de choix suivant « Approuvé ». En fonction de la décision de l'approbateur, la demande de compte est soit approuvée, soit rejetée par le biais de fonctions Lambda.

Invoquer un processus métier en réponse à un événement à l'aide d'Express Workflows
Dans cet exemple, un événement sur un bus Eventbridge personnalisé satisfait une règle et invoque un flux de travail Step Functions comme cible. Supposons que vous ayez une application de service client qui doit gérer les abonnements arrivés à expiration des clients. Une règle EventBridge surveille les événements des abonnements expirés et invoque un flux de travail cible en réponse. Le flux de travail de l'abonnement expiré désactivera toutes les ressources que l'abonnement expiré possède sans les supprimer et enverra un e-mail au client pour l'informer de l'expiration de son abonnement. Ces deux actions peuvent être effectuées en parallèle à l'aide de fonctions Lambda. À la fin du flux de travail, un nouvel événement est envoyé au bus d'événements par le biais d'une fonction Lambda, indiquant que l'expiration de l'abonnement a été traitée. Pour cet exemple, nous vous recommandons d'utiliser Express Workflows. À mesure que votre entreprise se développe et que vous commencez à placer davantage d'événements dans le bus d'événements, la capacité à invoquer 100 000 exécutions de flux de travail par seconde avec Express Workflows est puissante. Consultez l'exemple en action avec ce référentiel Github.

Sécurité et automatisation informatiques
Orchestrer une réponse aux incidents de sécurité pour la création de politiques IAM
Vous pouvez utiliser AWS Step Functions pour créer un flux de travail automatisé de réponse aux incidents de sécurité qui inclut une étape d'approbation manuelle. Dans cet exemple, un flux de travail Step Functions est déclenché lorsqu'une politique IAM est créée. Le flux de travail compare l'action de la politique à une liste personnalisable d'actions restreintes. Le flux de travail annule temporairement la politique, puis notifie un administrateur et attend que ce dernier approuve ou refuse. Vous pouvez étendre ce flux de travail pour prendre des mesures correctives automatiques, par exemple en appliquant des actions alternatives ou en limitant les actions à des ARN spécifiques. Consultez cet exemple en action ici.

Répondre aux événements opérationnels dans votre compte AWS
Vous pouvez réduire les frais opérationnels liés à la maintenance de votre infrastructure cloud AWS en automatisant la façon dont vous répondez aux événements opérationnels pour vos ressources AWS. Amazon EventBridge offre un flux d'événements de système quasiment en temps réel qui décrivent la plupart des modifications et des notifications apportées à vos ressources AWS. À partir de ce flux, vous pouvez créer des règles afin d'acheminer des événements spécifiques vers AWS Step Functions, AWS Lambda et d'autres services AWS pour un traitement ultérieur et des actions automatisées. Dans cet exemple, un flux de travail AWS Step Functions est déclenché sur la base d'un événement provenant d'AWS Health. AWS surveille de manière proactive les sites populaires de dépôt de code pour détecter les clés d'accès IAM qui ont été exposées publiquement. Supposons qu'une clé d'accès IAM ait été exposée sur GitHub. AWS Health génère un événement AWS_RISK_CREDENTIALS_EXPOSED dans le compte AWS lié à la clé exposée. Une règle Amazon Eventbridge configurée détecte cet événement et invoque un flux de travail Step Functions. À l'aide des fonctions AWS Lambda, le flux de travail supprime ensuite la clé d'accès IAM exposée, résume l'activité récente de l'API pour la clé exposée et envoie le message récapitulatif à une rubrique Amazon SNS pour informer les abonnés (dans cet ordre). Consultez cet exemple en action ici.

Synchroniser les données entre les compartiments S3 source et destination
Vous pouvez utiliser Amazon S3 pour héberger un site web statique, et Amazon CloudFront pour distribuer le contenu dans le monde entier. En tant que propriétaire d'un site web, vous pouvez avoir besoin de deux compartiments S3 pour télécharger le contenu de votre site web : un pour les tests et les simulations, et un pour la production. Vous devez mettre à jour le compartiment de production avec toutes les modifications apportées par le compartiment de simulation sans avoir à créer un nouveau compartiment chaque fois que vous mettez à jour votre site web. Dans cet exemple, le flux de travail Step Functions exécute des tâches dans deux boucles parallèles et indépendantes : une boucle copie tous les objets du compartiment source au compartiment de destination, mais écarte les objets déjà présents dans le compartiment de destination. La deuxième boucle supprime tous les objets du compartiment de destination qui ne se trouvent pas dans le compartiment source. Un ensemble de fonctions AWS Lambda réalise les étapes individuelles : valider l'entrée, obtenir les listes d'objets des compartiments source et destination, et copier ou supprimer des objets par lots. Consultez cet exemple et son code en détail ici. Pour en savoir plus sur la création de branches d'exécution parallèles dans votre machine d'état, cliquez ici.

Traitement des données et orchestration d'ETL
Créer un pipeline de traitement des données pour la diffusion de données en continu
Dans cet exemple, Freebird a créé un pipeline de traitement des données pour traiter les données des webhooks provenant de plusieurs sources en temps réel et exécuter les fonctions Lambda qui modifient les données. Dans ce cas d'utilisation, les données d'un webhook de plusieurs applications tierces sont envoyées par Amazon API Gateway à un flux de données Amazon Kinesis. Une fonction AWS Lambda extrait ces données de ce flux Kinesis et déclenche un flux de travail express. Ce flux de travail passe par une série d'étapes pour valider, traiter et normaliser ces données. Enfin, une fonction Lambda met à jour la rubrique SNS, ce qui déclenche l'envoi de messages aux fonctions Lambda en aval pour les étapes suivantes via une file d'attente SQS. Vous pouvez avoir jusqu'à 100 000 invocations de ce flux de travail par seconde pour faire évoluer le pipeline de traitement des données.

Automatiser les étapes d'un processus ETL
Vous pouvez utiliser Step Functions pour orchestrer toutes les étapes d'un processus ETL, avec différentes sources et destinations de données.
Dans cet exemple, le flux de travail Step Functions ETL rafraîchit Amazon Redshift chaque fois que de nouvelles données sont disponibles dans le compartiment S3 source. La machine d'état Step Functions lance une tâche AWS Batch et surveille son état pour voir si elle est terminée ou si elle comporte des erreurs. La tâche AWS Batch récupère le script .sql du flux de travail ETL à partir de la source, c'est-à-dire Amazon S3, et rafraîchit la destination, c'est-à-dire Amazon Redshift, via un conteneur PL/SQL. Le fichier .sql contient le code SQL pour chaque étape de la transformation des données. Vous pouvez déclencher le flux de travail ETL avec un événement EventBridge ou manuellement via AWS CLI ou en utilisant les kits SDK AWS ou même un script d'automatisation personnalisé. Vous pouvez alerter un administrateur par le biais de SNS qui déclenche un e-mail en cas d'échec à n'importe quelle étape du flux de travail ou à la fin de l'exécution du flux de travail. Ce flux de travail ETL est un exemple d'utilisation des flux de travail standard. Consultez cet exemple en détail ici. Pour en savoir plus sur la soumission d'une tâche AWS Batch à travers un exemple de projet, rendez-vous ici.

Exécuter un pipeline ETL avec plusieurs tâches en parallèle
Les opérations d'extraction, de transformation et de chargement (ETL) transforment les données brutes en jeux de données utiles, transformant les données en informations exploitables.
Vous pouvez utiliser Step Functions pour exécuter plusieurs tâches ETL en parallèle lorsque vos jeux de données sources peuvent être disponibles à différents moments, et chaque tâche ETL est déclenchée uniquement lorsque le jeu de données correspondant devient disponible. Ces tâches ETL peuvent être gérées par différents services AWS, tels que AWS Glue, Amazon EMR, Amazon Athena et d'autres services non AWS.
Dans cet exemple, vous avez deux tâches ETL distinctes exécutées sur AWS Glue qui traitent un jeu de données des ventes et un jeu de données de marketing. Une fois que les deux jeux de données sont traités, une troisième tâche ETL combine les résultats des tâches ETL précédentes pour produire un jeu de données combiné. Le flux de travail Step Functions attend que les données soient disponibles dans S3. Alors que le flux de travail est lancé selon un programme, un gestionnaire d'événements EventBridge est configuré sur un compartiment Amazon S3, de sorte que lorsque les fichiers des jeux de données des ventes ou du marketing sont téléchargés vers le compartiment, la machine d'état peut déclencher la tâche ETL « ProcessSalesData » ou « ProcessMarketingData » en fonction du jeu de données disponible.
Consultez cette architecture en détail ici pour configurer l'architecture d'orchestration ETL dans votre compte AWS. Découvrez comment gérer une tâche AWS Batch à partir de Step Functions ici.

Traitement des données à grande échelle
Vous pouvez utiliser Step Functions pour itérer sur des dizaines de millions d'éléments dans un jeu de données, comme un tableau JSON, une liste d'objets dans S3 ou un fichier CSV dans un compartiment S3. Vous pouvez ensuite traiter les données en parallèle avec une forte simultanéité.
Dans cet exemple, le flux de travail Step Functions utilise un état Map en mode distribué pour traiter une liste d'objets S3 dans un compartiment S3. Step Functions itère sur la liste d'objets, puis lance des milliers de flux de travail parallèle, s'exécutant simultanément, pour traiter les éléments. Vous pouvez utiliser des services de calcul, tels que Lambda, qui vous aident à écrire du code dans n'importe quel langage pris en charge. Vous pouvez également choisir parmi plus de 220 services AWS spécialisés à inclure dans le flux de travail de l'état Map. Une fois les exécutions des flux de travail enfants terminées, Step Functions peut exporter les résultats vers un compartiment S3, ce qui les rend disponibles pour une révision ou un traitement ultérieur.

Opérations de machine learning
Exécuter une tâche ETL et créer, entraîner et déployer un modèle de machine learning
Dans cet exemple, le flux de travail Step Functions s'exécute selon un programme déclenché par EventBridge pour s'exécuter une fois par jour. Le flux de travail commence par vérifier si de nouvelles données sont disponibles dans S3. Ensuite, il exécute une tâche ETL pour transformer les données. Ensuite, il entraîne et déploie un modèle de machine learning sur ces données à l'aide de fonctions Lambda qui déclenchent une tâche SageMaker et attendent son achèvement avant que le flux de travail ne passe à l'étape suivante. Enfin, le flux de travail déclenche une fonction Lambda pour générer des prédictions qui sont enregistrées sur S3. Suivez le processus étape par étape pour créer ce flux de travail ici.

Automatiser un flux de travail de machine learning à l'aide du kit SDK de science des données d'AWS Step Functions
Le kit SDK de science des données d'AWS Step Functions est une bibliothèque open source qui vous permet de créer des flux de travail qui traitent et publient des modèles de machine learning à l'aide d'Amazon SageMaker et d'AWS Step Functions. Le kit SDK fournit une API Python qui couvre chaque étape d'un pipeline de machine learning : entraînement, réglage, transformation, modélisation et configuration des points de terminaison. Vous pouvez gérer et exécuter ces flux de travail directement en Python, et dans les blocs-notes Jupyter. L'exemple ci-dessous illustre les étapes d'entraînement d'un flux de travail de machine learning. L'étape d'entraînement lance une tâche d'entraînement SageMaker et envoie les artefacts du modèle vers S3. L'étape d'enregistrement du modèle crée un modèle sur SageMaker en utilisant les artefacts de modèle provenant de S3. L'étape de transformation lance une tâche de transformation SageMaker. L'étape de création d'une configuration de point de terminaison définit une configuration de point de terminaison sur SageMaker. L'étape de création du point de terminaison déploie le modèle entraîné vers le point de terminaison configuré. Consultez le bloc-notes ici.

Traitement du multimédia
Extraire des données de PDF ou d'images pour les traiter
Dans cet exemple, vous apprendrez à combiner des fonctions AWS Step Functions, AWS Lambda et Amazon Textract pour numériser une facture PDF afin d'extraire son texte et ses données pour traiter un paiement. Amazon Textract analyse le texte et les données de la facture et déclenche un flux de travail Step Functions via SNS, SQS et Lambda pour chaque tâche réussie. Le flux de travail commence avec une fonction Lambda qui enregistre les résultats d'une analyse de facture réussie dans S3. Cela déclenche une autre fonction Lambda qui traite le document analysé pour voir si un paiement peut être traité pour cette facture, et met à jour les informations dans DynamoDB. Si la facture peut être traitée, le flux de travail vérifie si la facture est approuvée pour le paiement. Si ce n'est pas le cas, il notifie un réviseur via SNS pour qu'il approuve manuellement la facture. Si elle est approuvée, une fonction Lambda archive la facture traitée et met fin au flux de travail. Consultez cet exemple et son code en détail ici.

Séparer et transcoder la vidéo en utilisant une parallélisation massive
Dans cet exemple, Thomson Reuters a créé une solution de transcodage vidéo divisée sans serveur en utilisant AWS Step Functions et AWS Lambda. Ils devaient transcoder environ 350 clips vidéo d'actualité par jour en 14 formats pour chaque clip vidéo, et ce, le plus rapidement possible. L'architecture utilise FFmpeg, un encodeur audio et vidéo open source qui ne traite un fichier multimédia qu'en série. Afin d'améliorer le débit pour offrir la meilleure expérience client, la solution consistait à utiliser AWS Step Functions et Amazon S3 pour traiter les éléments en parallèle. Chaque vidéo est divisée en segments de 3 secondes, traités en parallèle puis assemblés à la fin.
La première étape est une fonction Lambda appelée Locate keyframes qui identifie les informations nécessaires au découpage de la vidéo. La fonction Lambda Split video divise ensuite la vidéo en fonction des images clés et stocke les segments dans un compartiment S3. Chaque segment est ensuite traité en parallèle par des fonctions lambda et placé dans un compartiment de destination. La machine d'état suit le traitement jusqu'à ce que tous les N segments soient traités. Elle déclenche ensuite une fonction Lambda finale qui concatène les segments traités, et stocke la vidéo dans un compartiment S3.
Créer un pipeline de transcodage vidéo sans serveur avec Amazon MediaConvert
Dans cet exemple, nous allons voir comment AWS Step Functions, AWS Lambda et AWS Elemental MediaConvert peuvent être orchestrés ensemble vers des capacités de transcodage entièrement gérées pour le contenu à la demande. Ce cas d'utilisation s'applique aux entreprises disposant d'un volume élevé ou variable de contenu vidéo source qui veulent traiter le contenu vidéo dans le cloud ou qui veulent déplacer les charges de travail vers le cloud à l'avenir.
La solution de vidéo à la demande comporte trois flux de travail secondaires déclenchés à partir d'un flux de travail principal de type Step Functions :
- Ingestion : il peut s'agir d'un flux de travail express. Un fichier source déposé dans S3 déclenche ce flux de travail pour ingérer les données.
- Traitement : ce flux de travail examine la hauteur et la largeur d'une vidéo et crée un profil d'encodage. Après le traitement, une tâche d'encodage est déclenchée via AWS Elemental MediaConvert.
- Publication : l'étape finale vérifie si les ressources sont disponibles dans les compartiments S3 de destination et notifie l'administrateur que la tâche est terminée.

Démarrer avec AWS Step Functions