Amazon CloudSearch, progettato per offrire throughput elevato e latenza bassa, supporta una vasta gamma di funzionalità tra cui l'elaborazione di testo specifico della lingua per 34 lingue, la ricerca a testo libero, la ricerca con facet, la ricerca geospaziale, la classificazione per pertinenza personalizzabile, le evidenziazioni, il completamento automatico, il dimensionamento configurabile dall'utente e le opzioni di disponibilità.
Per usare Amazon CloudSearch è sufficiente seguire questi semplici passi:
- Creare un dominio di ricerca
- Configurare le opzioni di indicizzazione per i dati
- Caricare i dati per l'indicizzazione
- Inviare richieste di ricerca dal sito web o dall'applicazione
La sezione che segue descrive in dettaglio il funzionamento di CloudSearch.
Prova Amazon CloudSearch gratis
Inizia la prova gratuita di CloudSearchUlteriori informazioni
Otterrai 750 ore gratuite di istanze di ricerca interamente funzionali per 30 giorni. Per iniziare:
Accedere all'account AWS e avviare la Console CloudSearch
Creare e configurare un dominio di ricerca con pochi clic
Per ogni raccolta di dati da ricercare, è possibile creare un dominio di ricerca Amazon CloudSearch. Un dominio di ricerca incapsula i dati insieme alle risorse hardware e software necessarie per usare un motore di ricerca. Ogni dominio di ricerca presenta una o più istanze di ricerca. Un'istanza di ricerca è un'istanza server che dispone di una quantità limitata di risorse di RAM e CPU per l'indicizzazione dei dati e l'elaborazione delle richieste. Il numero delle istanze di ricerca in un dominio dipende dai documenti contenuti nella raccolta e dal volume e dalla complessità delle richieste di ricerca.
Essendo un servizio di ricerca gestito, Amazon CloudSearch determina le dimensioni e il numero delle istanze di ricerca necessarie per garantire latenza bassa e prestazioni di ricerca con throughput elevato. Quando si crea un dominio di ricerca, Amazon CloudSearch usa un'istanza di ricerca di tipo Small (search.m1.small) per impostazione predefinita. Per ampliare la capacità di aggiornamento del dominio e ridurre la quantità di tempo necessario per caricare e indicizzare un'ampia raccolta di dati, è possibile selezionare un tipo di istanza di ricerca più grande. Se si necessita di maggiore capacità rispetto al tipo di istanza più grande, è possibile aumentare il numero delle istanze sulle quali viene effettuato il partizionamento dell'indice.
Parallelamente all'incremento dell'indice di ricerca dei dati, Amazon CloudSearch esegue il dimensionamento automatico del dominio di ricerca in funzione delle necessità. Quando l'indice supera la capacità del tipo di istanza corrente, il dominio viene dimensionato al tipo successivo di istanza più grande. Se l'indice di ricerca supera la capacità del tipo di istanza più grande, Amazon CloudSearch esegue il partizionamento dell'indice tra più istanze. Se invece l'indice si restringe, CloudSearch esegue il dimensionamento del dominio in un numero minore di partizioni o un tipo di istanza di ricerca più piccolo.
Amazon CloudSearch, inoltre, esegue il dimensionamento automatico per gestire gli incrementi della quantità di traffico di ricerca. Quando un'istanza di ricerca si avvicina al carico di query massimo, CloudSearch esegue la distribuzione di una replica dell'istanza di ricerca. Al contrario, a fronte di un calo del traffico di ricerca, Amazon CloudSearch rimuove le repliche non necessarie per garantire il massimo contenimento dei costi.
Ad esempio, un indice di ricerca suddiviso in tre partizioni usa tre istanze di ricerca (una per ogni partizione). Man mano che il traffico di ricerca aumenta oltre la capacità di elaborazione delle singole istanze di ricerca, le partizioni vengono replicate per fornire maggiore capacità di query. Successivamente alla replica delle istanze, il dominio presenta un totale di sei istanze di ricerca (due per ogni partizione). Se il traffico continua ad aumentare, Amazon CloudSearch aggiunge altre repliche in funzione delle necessità.
Se si prevedono grandi volumi di traffico di query o un picco di traffico significativo, è possibile aggiungere al dominio repliche di istanze di ricerca in modo esplicito.

Per visualizzare le risorse usate dai domini Amazon CloudSearch è possibile accedere alla pagina Attività dell'account nel sito web di AWS, usando la Console di gestione AWS oppure inviando richieste API CloudSearch tramite l'interfaccia della riga di comando AWS oppure gli SDK AWS.
La quantità di dati che ogni tipo di istanza di ricerca è in grado di supportare dipende per lo più dalle dimensioni dei documenti che si sta indicizzando e dalle opzioni di indicizzazione configurate per il dominio.
Per dimostrare la capacità di ciascun tipo di istanza di ricerca, prendiamo come esempio un documento e la configurazione per il set di dati Film IMDb. L'esempio che segue mostra il documento di un film IMDb delle dimensioni di circa 1 KB:
{
"campi" : {
"registi" : [
"Francis Lawrence"
],
"data di uscita" : "2013-11-11T00:00:00Z",
"generi" : [
"Azione",
"Avventura",
"Fantascienza",
"Thriller"
],
"url immagine" : "http://ia.media-imdb.com/images/M/MV5xMzNeMzAx._V1_SX400_.jpg",
"trama" : "Katniss Everdeen e Peeta Mellark diventano bersagli a Capitol City in seguito alla vittoria ottenuta nella 74° edizione degli Hunger Games nei distretti di Panem.","titolo" : "Hunger Games: La ragazza di fuoco",
"classifica" : 4,
"tempo di esecuzione in secondi" : 8760,
"attori" : [
"Jennifer Lawrence",
"Josh Hutcherson",
"Liam Hemsworth"
],
"anno" : 2013
},
"ID" : "tt1951264",
"tipo" : "aggiungi"
}
Per indicizzare e ricercare documenti di film come quello riportato nell'esempio, configuriamo il dominio di ricerca con un campo d'indice per ciascun campo del documento. Possono essere specificate più opzioni di indicizzazione per ogni campo, come ad esempio il tipo di campo e se il campo è ricercabile oppure abilitato per i facet, la restituzione, l'ordinamento o l'evidenziazione. Queste opzioni di indicizzazione influiscono direttamente sul numero di documenti appropriati per un'istanza di ricerca. La tabella che segue illustra un esempio di configurazione per i campi d'indice dei documenti di film IMDb.
| Nome |
Tipo |
Cerca |
Facet |
Restituisci |
Ordina | Evidenzia |
|---|---|---|---|---|---|---|
| attori |
array testo |
✔ | – | ✗ | – | ✗ |
| registi |
array testo |
✔ | – | ✗ | – | ✗ |
| generi |
array letterario |
✔ | ✔ | ✗ |
– | – |
| url immagine |
testo |
✗ | – | ✗ | ✗ | ✗ |
| trama |
testo |
✔ | – | ✗ | ✗ | ✔ |
| classifica | int. | ✔ | ✗ | ✗ | ✔ | – |
| valutazione |
doppio |
✔ | ✔ | ✗ | ✔ | – |
| data di uscita |
data |
✔ | ✔ | ✗ | ✔ | – |
| tempo di esecuzione in secondi |
int. |
✔ | ✔ | ✗ | ✔ | – |
| titolo |
testo |
✔ | – | ✔ | ✔ | ✔ |
| anno |
int. |
✔ | ✔ | ✔ | ✔ | – |
In base alle dimensioni del documento (1 KB) e alla configurazione d'indice corrente, ogni tipo di istanza di ricerca ha la capacità di documenti illustrata nella tabella seguente.
| Tipo di istanza di ricerca | Capacità di dati |
|---|---|
| Istanza di ricerca di tipo Small (search.m1.small) |
2 milioni di documenti |
| Istanza di ricerca di tipo Large (search.m1.large) | 8 milioni di documenti |
| Istanza di ricerca di tipo Extra Large (search.m2.xlarge) |
16 milioni di documenti |
| Istanza di ricerca di tipo Double Extra Large (search.m2.2xlarge) | 32 milioni di documenti |
Come si può immaginare, quello illustrato è solo un esempio. Documenti diversi e configurazioni diverse possono variare sensibilmente il numero di documenti contenuti in un'istanza. Se si supera la capacità di una singola istanza di ricerca di tipo Double Extra Large, Amazon CloudSearch esegue automaticamente il partizionamento dell'indice di ricerca su istanze di ricerca di tipo Double Extra Large aggiuntive. Un indice può essere partizionato su un massimo di 10 istanze di ricerca di tipo Double Extra Large in modo da supportare decine di centinaia di milioni di documenti. Per un dimensionamento aggiuntivo, ti invitiamo a contattarci.
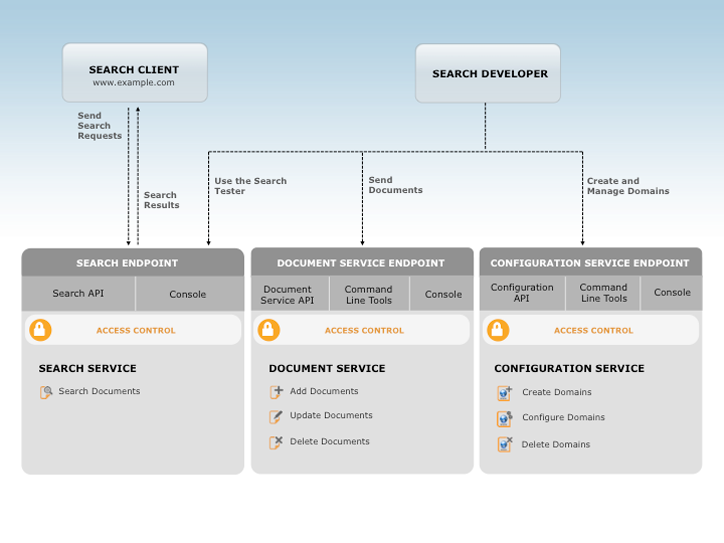
È possibile interagire con Amazon CloudSearch mediante tre servizi:
- Il servizio di configurazione, per creare e configurare domini di ricerca
- Il servizio documenti, per caricare batch di documenti
- Il servizio di ricerca, per inviare richieste di ricerca e di suggerimento
Le politiche di AWS Identity and Access Management (IAM) consentono di gestire l'accesso al servizio di configurazione di Amazon CloudSearch e al servizio documenti e di ricerca di ciascun dominio.
Il servizio di configurazione consente di creare e configurare domini di ricerca. Per configurare un dominio di ricerca, è necessario assegnare al dominio un nome univoco e configurare opzioni di configurazione, schemi di analisi di testo, opzioni di disponibilità, opzioni di dimensionamento, componenti per il suggerimento ed espressioni.
- Le opzioni di indicizzazione specificano i campi da includere nell’indice. La Console di gestione AWS o gli strumenti della riga di comando di Amazon CloudSearch possono essere usati per ricercare dati e configurare automaticamente le opzioni di indicizzazione predefinite.
- Gli schemi di analisi del testo specificano le opzioni di elaborazione testuale specifiche della lingua per i campi di testo e array di testo. Gli schemi di analisi controllano le parole non significative che devono essere ignorate durante l'indicizzazione, definiscono sinonimi comuni per i termini e specificano il modo in cui i termini sono associati alle origini comuni.
- Le opzioni di disponibilità consentono di distribuire un dominio tra due zone di disponibilità e garantire elevata disponibilità in caso di interruzione del servizio.
- Le opzioni di dimensionamento consentono di eseguire il predimensionamento del dominio, specificando il tipo di istanza desiderata, il conteggio delle repliche e il conteggio delle partizioni. Queste operazioni sono utili quando è necessario caricare grandi volumi di documenti o prevedere un aumento significativo del traffico di query.
- I componenti per il suggerimento consentono di recuperare le corrispondenze possibili per una query di ricerca incompleta, in modo da visualizzare i risultati sotto forma di tipi di utente.
- Le espressioni sono espressioni di tipo numerico e vengono valutate in fase di query. È possibile usare le espressioni per controllare il modo in cui sono classificati i risultati di ricerca. Per impostazione predefinita, i documenti sono classificati in base a un punteggio di rilevanza che tiene conto della frequenza dei termini di ricerca all'interno di un documento. Le espressioni possono essere usate per includere nell'ordinamento altri fattori. Ad esempio, se il documento contiene un campo numerico chiamato "popolarità", è possibile definire un'espressione che unisce il punteggio di popolarità a quello di rilevanza predefinita, in modo da classificare i documenti popolari rilevanti tra i primi posti dei risultati di ricerca.
Il servizio documenti consente di apportare modifiche ai dati ricercabili di un dominio. Ogni dominio ha un endpoint HTTP del servizio documenti univoco.
Per inviare i dati al dominio, è necessario formattarli con l'estensione JSON o XML. Ogni elemento che si desidera venga restituito come risultato di ricerca è rappresentato sotto forma di documento. Ogni documento ha un ID univoco e uno o più campi che contengono i dati che si desidera ricercare e restituire all'interno dei risultati. I campi documenti possono contenere dati di stringa UTF-8 qualsiasi. Le opzioni di indicizzazione del dominio specificano come si desidera indicizzare e usare i dati.
Il servizio di ricerca gestisce le richieste di ricerca o di suggerimento per un dominio. Ogni dominio ha un endpoint HTTP di ricerca univoco. Quando si invia una richiesta di ricerca o di suggerimento, il servizio di ricerca restituisce un elenco dei documenti corrispondenti. I risultati vengono restituiti in formato JSON o XML.
Amazon CloudSearch offre un ricco linguaggio di query che consente di ricercare all'interno di campi particolari, eseguire ricerche booleane complesse, recuperare informazioni sui facet e specificare i dati da includere nei risultati di ricerca. È anche possibile specificare le opzioni per controllare il modo in cui vengono elaborati i termini di query e utilizzare altri parser di query come ad esempio Lucene o DisMax.
I test di ricerca della console Amazon CloudSearch possono essere usati per testare gli esempi di query.
L'uso di questo servizio è soggetto al contratto con il cliente Amazon Web Services.