Nozioni di base / Esperienza pratica / ...
Preparazione dei dati di addestramento per il machine learning con un codice minimo
TUTORIAL
Panoramica
Obiettivi
Con questa guida, imparerai a:
- Visualizzare e analizzare i dati per comprendere le relazioni chiave
- Applicare le trasformazioni per eliminare i dati e generare nuove funzionalità
- Generare automaticamente i notebook per i flussi di lavoro ripetibili per la preparazione dei dati
Prerequisiti
Prima di iniziare questo tutorial, avrai bisogno di:
- Un account AWS: se non hai già un account, segui la guida introduttiva Configurazione del tuo ambiente AWS per una panoramica rapida.
Esperienza AWS
Principiante
Tempo per il completamento
30 minuti
Costo richiesto per il completamento
Per una stima dei costi di questo tutorial, consulta Prezzi di Amazon SageMaker.
Requisiti
Devi aver effettuato l'accesso con un account AWS.
Servizi utilizzati
Amazon SageMaker Data Wrangler
Ultimo aggiornamento
1 luglio 2022
Implementazione
Fase 1: Configurazione del dominio di Amazon SageMaker Studio
Con Amazon SageMaker puoi implementare un modello visivamente utilizzando la console o in maniera programmatica utilizzando SageMaker Studio o i notebook SageMaker. In questo tutorial, il modello viene implementato in maniera programmatica tramite un notebook SageMaker Studio, che richiede un dominio di SageMaker Studio.
Un account AWS può avere solo un dominio SageMaker Studio per regione. Se hai già un dominio SageMaker Studio nella regione Stati Uniti orientali (Virginia settentrionale), consulta la Guida alla configurazione di SageMaker Studio per collegare le policy AWS IAM richieste all'account SageMaker Studio, quindi salta la fase 1 e passa direttamente alla fase 2.
Se invece non disponi di un dominio SageMaker Studio, continua con la fase 1 per eseguire un modello AWS CloudFormation che crea un dominio SageMaker Studio e aggiunge le autorizzazioni necessarie per il resto di questo tutorial.
Scegli il link dello stack AWS CloudFormation. Questo link apre la console AWS CloudFormation e crea il dominio SageMaker e un utente denominato studio-user. Inoltre aggiunge le autorizzazioni richieste al tuo account SageMaker Studio. Nella console CloudFormation, conferma che Stati Uniti orientali (Virginia settentrionale) sia la regione visualizzata nell'angolo in alto a destra. Il nome dello stack deve essere CFN-SM-IM-Lambda-catalog e non può essere modificato. Questo stack richiede circa 10 minuti per creare tutte le risorse.
Assume inoltre che sia presente un VPC pubblico configurato nell'account. Se non hai un VPC pubblico, consulta VPC con una singola sottorete pubblica per scoprire come creare un VPC pubblico.

Seleziona I acknowledge that AWS CloudFormation might create IAM resources (Sono consapevole che AWS CloudFormation può creare le risorse IAM), quindi scegli Create stack (Crea stack).

Nel riquadro CloudFormation, scegli Stacks (Stack). La creazione dello stack richiede circa 10 minuti. Una volta creato lo stack, il suo stato passerà da CREATE_IN_PROGRESS a CREATE_COMPLETE.

Fase 2: Creazione di un nuovo flusso di SageMaker Data Wrangler
SageMaker Data Wrangler accetta dati da un'ampia varietà di origini, tra cui Amazon S3, Amazon Athena, Amazon Redshift, Snowflake e Databricks. In questa fase, creerai un nuovo flusso di SageMaker Data Wrangler utilizzando il set di dati sul rischio di credito tedesco UCI archiviato in Amazon S3. Questo set di dati contiene informazioni demografiche e finanziarie sugli individui insieme a un'etichetta che indica il livello di rischio di credito dell'individuo.
Digita SageMaker Studio nella barra di ricerca della console, quindi scegli SageMaker Studio.

Scegli US East (N. Virginia) (Stati Uniti orientali [Virginia settentrionale]) dall'elenco a discesa Region (Regione) nell'angolo in alto a destra della console SageMaker. In Launch app (Avvia app), seleziona Studio per aprire SageMaker Studio utilizzando il profilo studio-user.

Apri l'interfaccia di SageMaker Studio. Sulla barra di navigazione, scegli File, New (Nuovo), Data Wrangler Flow (Flusso di Data Wrangler).

Nella scheda Import (Importa), in Import data (Importa dati), scegli Amazon S3.
Nel campo S3 URI path (Percorso URI S3), immetti s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv, quindi seleziona Go (Vai). In Object name (Nome oggetto), fai clic su german_credit_data.csv, quindi scegli Import (Importa).

Fase 3: Profilazione dei dati
In questa fase utilizzerai SageMaker Data Wrangler per valutare la qualità del set di dati di addestramento. Puoi utilizzare la funzionalità Modello rapido per stimare approssimativamente la qualità di previsione prevista e il potere predittivo delle funzionalità nel set di dati.
Nella scheda Data Flow (Flusso di dati), nel diagramma del flusso di dati, scegli l'icona +, quindi Add analysis (Aggiungi analisi).
Nel pannello Create analysis (Crea analisi), per Analysis type (Tipo di analisi) seleziona Histogram (Istogramma).
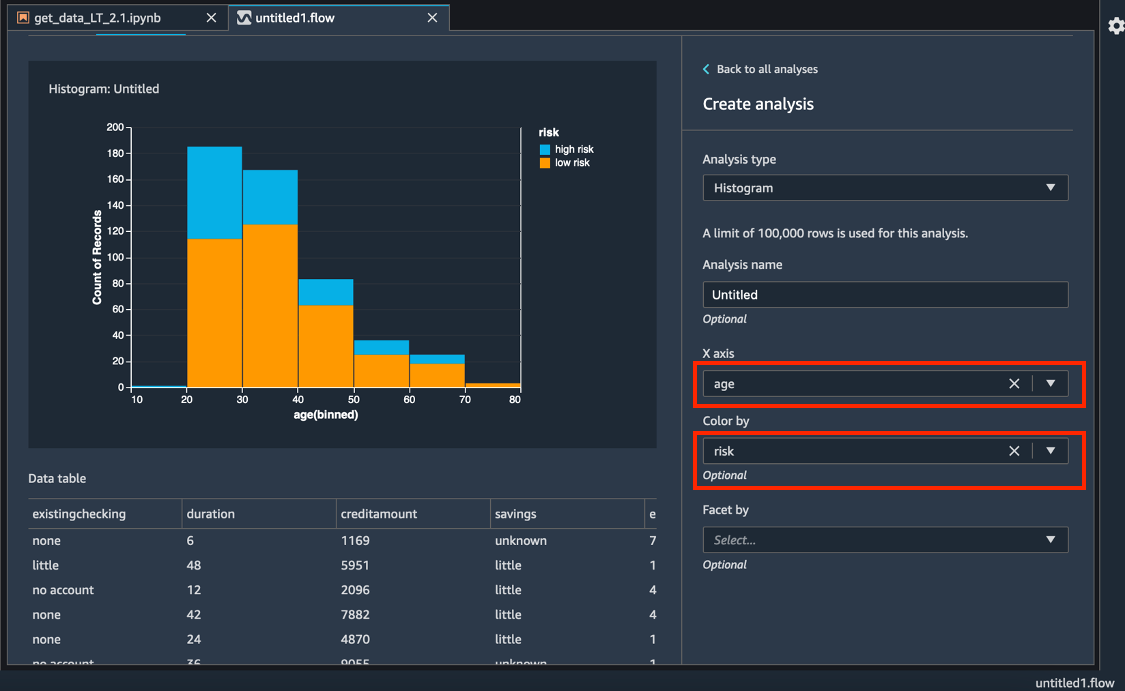
Per l'asse X, seleziona age (età).
Per Color by (Colora di), seleziona risk (rischio).
Scegli Preview (Anteprima) per generare un istogramma del campo credit risk (rischio di credito), codificato a colori con la fascia age (età).
Scegli Save (Salva) per salvare questa analisi nel flusso.
Per capire quanto bene il set di dati sia adatto per addestrare un modello che predice la variabile di destinazione risk (rischio), esegui l'analisi Modello rapido. Dalla scheda Analysis (Analisi), scegli Create new analysis (Crea nuova analisi).
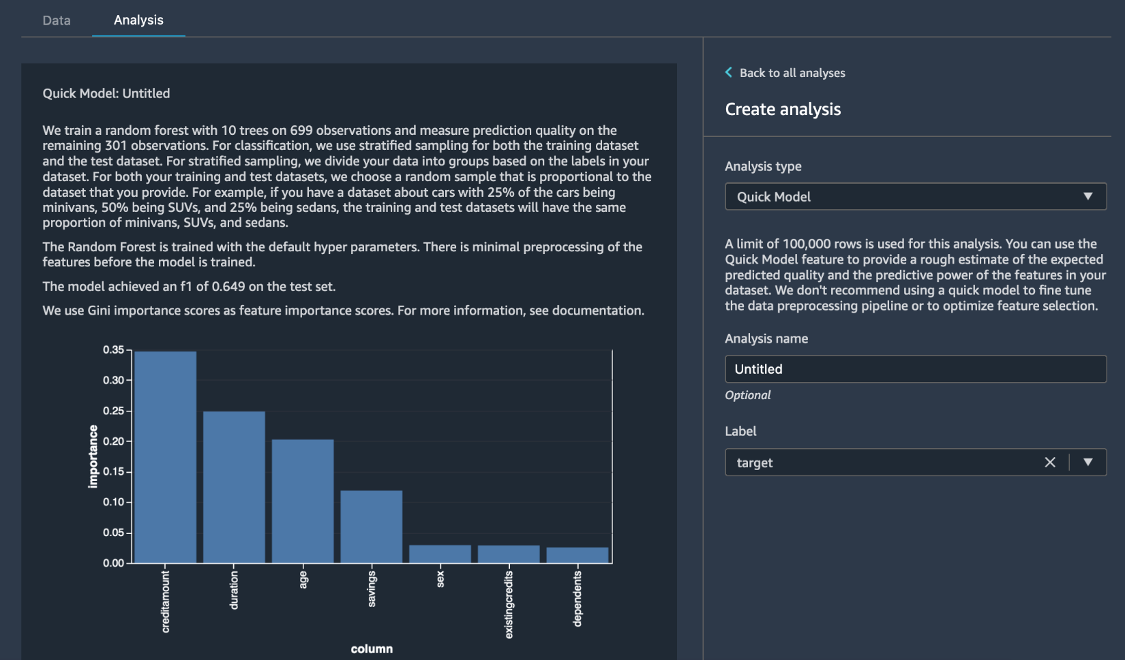
Nel riquadro Create analysis (Crea analisi), per Analysis type (Tipo di analisi), scegli Quick Model (Modello rapido). Per Label (Etichetta), seleziona risk (rischio), quindi scegli Preview (Anteprima). Il riquadro Quick Model (Modello rapido) mostrerà una breve panoramica del modello utilizzato e alcune statistiche di base, tra cui il punteggio F1 e l'importanza delle funzionalità, per aiutarti a valutare la qualità del set di dati. Scegli Save (Salva).
Fase 4: Aggiunta di trasformazioni al flusso di dati
SageMaker Data Wrangler semplifica l'elaborazione dei dati fornendo un'interfaccia visiva con la quale è possibile aggiungere un'ampia varietà di trasformazioni predefinite. Puoi anche scrivere le tue trasformazioni personalizzate utilizzando SageMaker Data Wrangler. In questa fase, uniformerai i dati di stringhe complesse, codificherai le categorie, rinominerai le colonne ed eliminerai le colonne non necessarie utilizzando l'editor visivo. Dividerai quindi la colonna status_sex in due nuove colonne, marital_status e sex.
Per passare al diagramma del flusso di dati, scegli Flusso di dati.

Nel diagramma del flusso di dati scegli l'icona +, quindi Add transform (Aggiungi trasformazione).

Nel riquadro ALL STEPS (TUTTE LE FASI), scegli Add step (Aggiungi fase).

Dall'elenco ADD TRANSFORM (AGGIUNGI TRASFORMAZIONE), scegli Search and edit (Cerca e modifica), che è una trasformazione utilizzata per manipolare i dati di stringa.

Nel riquadro SEARCH AND EDIT (CERCA E MODIFICA), per Transform (Trasformazione), seleziona Split string by delimiter (Dividi la stringa per delimitatore). Per Input columns (Colonne di input), seleziona status_sex. Nella casella Delimiter (Delimitatore), immetti il simbolo :. In Output column (Colonna di output), immetti vec. Scegli Preview (Anteprima), quindi Add (Aggiungi).
Questa trasformazione crea una nuova colonna denominata vec alla fine del dataframe dividendo la colonna status_sex. La colonna status_sex contiene stringhe delimitate da due punti (:) e la nuova colonna vec contiene i vettori delimitati da virgole (,).

Per dividere la colonna vec e creare due nuove colonne, sex_split_0 e sex_split_1:
In ALL STEPS (TUTTE LE FASI), scegli + Add step (Aggiungi fase).
Dall'elenco ADD TRANSFORM (AGGIUNGI TRASFORMAZIONE), scegli Manage vectors (Gestisci vettori).
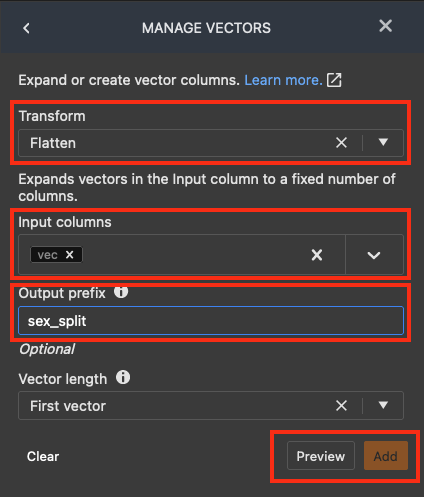
Nel riquadro MANAGE VECTORS (GESTISCI VETTORI), per Transform (Trasformazione), seleziona Flatten (Uniforma). Per Input columns (Colonne di input), seleziona status_sex. In output_prefix, immetti sex_split.
Scegli Preview (Anteprima), quindi Add (Aggiungi).
Per rinominare le colonne create dalla trasformazione divisa:
Nel riquadro ALL STEPS (TUTTE LE FASI), scegli + Add step (Aggiungi fase).
Dall'elenco ADD TRANSFORM, scegli Manage columns (Gestisci vettori).
Nel riquadro MANAGE COLUMNS (GESTISCI COLONNA), per Transform (Trasformazione), seleziona Rename column (Rinomina colonna). Per Input column (Colonna di input), seleziona sex_split_0. Nella casella New name (Nuovo nome), immetti sex.
Scegli Preview (Anteprima), quindi Add (Aggiungi).
Ripeti questa procedura per ridenominare sex_split_1 in marital_status.

Fase 5: Aggiunta di una codifica categorica
In questa fase, creerai una destinazione di modellazione e codificherai le variabili di categoria. La codifica di categoria trasforma le categorie dei tipi di dati stringa in etichette numeriche. È un'attività di preelaborazione comune perché le etichette numeriche possono essere utilizzate in un'ampia varietà di tipi di modello.
Nel set di dati, la classificazione del rischio di credito è rappresentata dalle stringhe high risk e low risk. In questa fase, convertirai questa classificazione in una rappresentazione binaria, 0 o 1.
Nel riquadro ALL STEPS (TUTTE LE FASI), scegli + Add step (Aggiungi fase). Dall'elenco ADD TRANSFORM (AGGIUNGI TRASFORMAZIONE), scegli Encode categorical (Codifica di categoria). SageMaker Data Wrangler fornisce tre tipi di trasformazione: codifica ordinale, codifica one-hot e codifica di somiglianza. Nel riquadro ENCODE CATEGORICAL (CODIFICA DI CATEGORIA), per Transform (Trasformazione), lascia il valore predefinito Ordinal encode (Codifica ordinale). Per Input columns (Colonne di input), seleziona risk. In Output column (Colonna di output), immetti target. Per questo tutorial la casella Invalid handling strategy (Strategia di gestione non valida) verrà ignorata. Scegli Preview (Anteprima), quindi Add (Aggiungi).

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

Utilizza la trasformazione Codifica di categoria per codificare le colonne rimanenti, housing, job, sex e marital_status come riportato di seguito: in ALL STEPS (TUTTE LE FASI), scegli + Add Step (Aggiungi fase). Dall'elenco ADD TRANSFORM (AGGIUNGI TRASFORMAZIONE), scegli Encode categorical (Codifica di categoria). Nel riquadro ENCODE CATEGORICAL (CODIFICA DI CATEGORIA), per Transform (Trasformazione), lascia il valore predefinito Ordinal encode (Codifica ordinale). Per Input columns (Colonne di input), seleziona housing, job, sex e marital_status. Lascia vuoto il campo Output column (Colonna di output) in modo che i valori codificati sostituiscano i valori di categoria. Scegli Preview (Anteprima), quindi Add (Aggiungi).

Per dimensionare la colonna numerica creditamount, applica un ridimensionatore all'importo del credito per normalizzare la distribuzione dei dati in questa colonna: nel riquadro ALL STEPS (TUTTE LE FASI), scegli + Add Step (Aggiungi fase). Dall'elenco ADD TRANSFORM (AGGIUNGI TRASFORMAZIONE), scegli Process numeric (Processo numerico) Per Scaler (Ridimensionatore), seleziona l'opzione predefinita Standard scaler (Ridimensionatore standard). Per Input columns (Colonne di input), seleziona creditamount. Scegli Preview (Anteprima), quindi Add (Aggiungi).


Per eliminare le colonne originali che sono state trasformate, nel riquadro ALL STEPS (TUTTE LE FASI), scegli + Add step (Aggiungi fase). Dall'elenco ADD TRANSFORM (AGGIUNGI TRASFORMAZIONE), scegli Manage columns (Gestisci colonne). Nel riquadro MANAGE COLUMNS (GESTISCI COLONNE), per Transform (Trasformazione), seleziona Drop Column (Elimina colonna). Per Columns to drop (Colonne da eliminare), seleziona status_sex, existingchecking, employmentsince, risk e vec. Scegli Preview (Anteprima), quindi Add (Aggiungi).

Fase 6: Esecuzione di un controllo degli errori dei dati
In questa fase, controllerai i dati alla ricerca di eventuali errori tramite Amazon SageMaker Clarify, che fornisce una maggiore visibilità sui dati e i modelli di addestramento in modo da poter identificare e limitare gli errori e spiegare le previsioni.
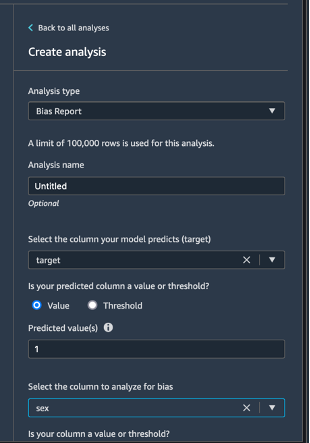
Scegli Data flow (Flusso di dati) in alto a sinistra per tornare al diagramma del flusso di dati. Scegli l'icona +, quindi Add analysis (Aggiungi analisi). Nel pannello Create analysis (Crea analisi), per Analysis type (Tipo di analisi) seleziona Bias Report (Rapporto di distorsione). Per Analysis name (Nome analisi), immetti un nome. Per Select the column your model predicts (target) (Seleziona la colonna prevista dal tuo modello [destinazione]), seleziona target. Lascia selezionata la casella di controllo Value (Valore). Nella casella Predicted value(s) (Valori previsti), immetti 1. Per Select the column to analyze for bias (Seleziona la colonna da analizzare per la distorsione), seleziona sex. Per Choose bias metrics (Scegli parametri distorsione), mantieni le selezioni predefinite. Scegli Check for bias (Controlla distorsioni).
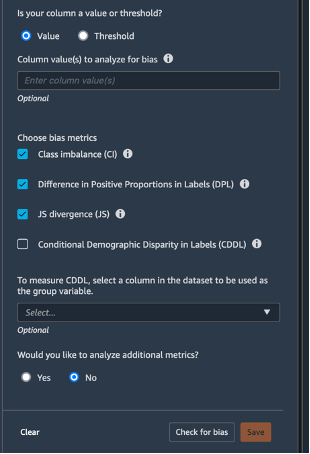
Dopo qualche secondo, SageMaker Clarify genererà un report che mostra il punteggio delle colonne target e test su una serie di parametri correlati alla distorsione, tra cui Class Imbalance (CI) e Difference in Positive Proportions in Labels (DPL). In questo casi, i dati sono leggermente distorti per i termini sex (-0,38) e poco distorti in termini di labels (0,075). Sulla base di questo report, potresti prendere in considerazione un metodo di correzione della distorsione, come l'utilizzo della trasformazione SMOTE incorporata di SageMaker Data Wrangler. Ai fini di questo tutorial, puoi saltare la fase di correzione. Scegli Save (Salva) per salvare il report di distorsione nel flusso di dati.

Fase 7: Esportazione del flusso di dati
Esporta il flusso di dati su un notebook Jupyter per eseguire le fasi come processi di elaborazione SageMaker. Queste fasi elaborano i dati in base al flusso di dati definito e archiviano gli output in Amazon S3 o Amazon SageMaker Feature Store.
Dal diagramma del flusso di dati, scegli l'icona +, quindi Export to (Esporta su), Amazon S3 (via Jupyter Notebook) (Amazon S3 [tramite notebook Jupyter]). Questo crea un notebook in SageMaker Studio in cui è possibile eseguire i processi di elaborazione SageMaker generati per creare il set di dati trasformato. Esegui questo notebook per archiviare i risultati nel bucket S3 predefinito.



Fase 8: Eliminazione delle risorse
Per evitare di ricevere addebiti non desiderati, una best practice consigliata consiste nell'eliminare le risorse non più utilizzate.
Per eliminare il bucket S3, completa le seguenti operazioni:
- Apri la console Amazon S3. Sulla barra di navigazione, scegli Buckets (Bucket), sagemaker-<regione>-<id-account>, quindi seleziona la casella di controllo accanto a data_wrangler_flows. Quindi, seleziona Delete (Elimina).
- Nella finestra di dialogo Delete objects (Elimina oggetti), verifica di aver selezionato l'oggetto corretto da eliminare, quindi digita permanently delete nella casella di conferma Permanently delete objects (Elimina definitivamente gli oggetti).
- Una volta completato e il bucket è vuoto, potrai eliminare il bucket sagemaker-<regione>-<id-account> eseguendo di nuovo la stessa procedura.

Il kernel Data science utilizzato per eseguire l'immagine del notebook in questo tutorial accumulerà costi fino a quando non lo interromperai o eseguirai i passaggi riportati di seguito per eliminare le app. Per ulteriori informazioni, consulta Risorse di arresto nella Guida per gli sviluppatori di Amazon SageMaker.
Per eliminare le app SageMaker Studio, completa la seguente procedura: nella console SageMaker Studio, scegli studio-user, quindi elimina tutte le app riportate in Apps (App) selezionando Delete app (Elimina app). Attendi fino a che Status (Stato) diventa Deleted (Eliminato).

Se nella fase 1 hai utilizzato un dominio SageMaker Studio esistente, salta il resto della fase 8 e procedi direttamente alla sezione conclusiva.
Se hai eseguito il modello CloudFormation nella fase 1 per creare un nuovo dominio SageMaker Studio, continua con le fasi seguenti per eliminare il dominio, l'utente e le risorse create dal modello CloudFormation.
Per aprire la console CloudFormation, immetti CloudFormation nella barra di ricerca della console AWS, quindi scegli CloudFormation dai risultati della ricerca.

Nel riquadro CloudFormation, scegli Stacks (Stack). Dall'elenco a discesa degli stati, seleziona Active (Attivo). In Stack name (Nome stack), scegli CFN-SM-IM-Lambda-catalog per aprire la pagina dei dettagli dello stack.

Nella pagina dei dettagli dello stack CFN-SM-IM-Lambda-catalog, scegli Delete (Elimina) per eliminare lo stack insieme alle risorse create nella fase 1.

Conclusioni
Hai utilizzato con successo Amazon SageMaker Data Wrangler per preparare i dati per l'addestramento di un modello di machine learning. SageMaker offre oltre 300 trasformazioni dei dati preconfigurate, come conversione del tipo di colonna, codifica one-hot, attribuzione di dati mancanti con media o mediana, colonne di ridimensionamento ed integrazioni di data/ora, così puoi trasformare i tuoi dati in formati che possono efficacemente essere usati per i modelli senza scrivere una sola riga di codice.
Addestramento di un modello di deep learning
Creazione automatica di un modello di ML
Trova altri tutorial pratici