Amazon CloudSearch は高スループットと低レイテンシーを実現するために構築され、34 言語の言語固有のテキスト処理、フリーテキスト検索、ファセット検索、地理空間検索、カスタマイズ可能な適切度ランク付け、ハイライト表示、自動入力、ユーザー設定可能なスケーリング、可用性のオプションなど、豊富な機能をサポートします。
Amazon CloudSearch を使用するには、次の簡単な手順を実行します。
- 検索ドメインを作成する
- データのインデックスオプションを構成する
- データをアップロードしてインデックスを作成する
- ウェブサイトまたはアプリケーションから検索リクエストを送信する
次に、CloudSearch の動作について詳しく説明します。
Amazon CloudSearch を無料でお試しください
まずは無料で始める »またはコンソールにサインイン
機能制限なしの検索インスタンスを 750 時間分、30 日間無料でご利用いただけます。開始するには次の手順に従ってください。
AWS アカウントにサインインして、CloudSearch コンソールを起動します。
数回のクリックで、検索ドメインの作成と設定を行います。
データをアップロードし、コンソール、AWS SDK、または CLI で検索 / 更新リクエストを送信します。
検索可能にするデータの各コレクションについて、Amazon CloudSearch 検索ドメインを作成します。検索ドメインによって、データと、検索エンジンの操作に必要なハードウェアおよびソフトウェアのリソースをカプセル化します。各検索ドメインには 1 つまたは複数の検索インスタンスがあります。検索インスタンスは、限定された容量の RAM および CPU リソースでデータのインデックス作成およびリクエストの処理を行うサーバーインスタンスです。ドメイン内の検索インスタンスの数は、コレクション内のドキュメントおよび検索リクエストの量と複雑さによって異なります。
マネージド型検索サービスである Amazon CloudSearch では、検索実行時のレイテンシーを低く抑えてスループットを高めるのに必要な検索インスタンスのサイズと数が決定されます。検索ドメインを作成する際、Amazon CloudSearch のデフォルトではスモール検索インスタンスタイプ(search.m1.small)を使用します。より大きな検索インスタンスタイプを選択することで、ドメインの更新容量を増やし、大きなデータのコレクションのアップロードとインデックス作成にかかる時間を短縮することができます(提供されている最も大きなインスタンスタイプよりも多くの容量が必要な場合は、インスタンス数を増やして、インデックスを複数のインスタンスに分割する方法があります)。
検索インデックスのデータ量が増えると、Amazon CloudSearch は必要に応じて検索ドメインを自動的に拡張します。インデックスが現在のインスタンスタイプの容量を超えると、ドメインは 1 つ大きなインスタンスタイプに拡張されます。検索インデックスが最も大きなインスタンスタイプの容量を超えると、Amazon CloudSearch はインデックスを複数のインスタンスに分割します。逆にインデックスのサイズが小さくなると、CloudSearch はドメインのパーティションを減らすか、小さな検索インスタンスタイプに縮小します。
また、Amazon CloudSearch は、検索トラフィック量が増えた場合にも、自動的に拡張します。検索インスタンスが最大クエリ負荷に近づくと、CloudSearch は検索インスタンスのレプリカをデプロイします。逆に検索トラフィックが低下すると、Amazon CloudSearch は不要なレプリカを削除してコストを最小化します。
例えば、3 つのパーティションに分割された検索インデックスは、3 つの検索インスタンス(1 つのパーティションにつき 1 つ)を使用します。検索トラフィックが増えて各検索インスタンスの処理能力を超えると、追加のクエリ容量を提供するためにパーティションはレプリケートされます。インスタンスがレプリケートされると、ドメインの検索インスタンス数は合計で 6 個(1 つのパーティションにつき 2 つ)になります。トラフィックが増え続けると、Amazon CloudSearch は必要に応じてレプリカを追加します。
大量のクエリトラフィックや、トラフィックの急上昇が予想される場合は、ドメインに検索インスタンスレプリカを明示的に追加できます。

Amazon CloudSearch ドメインが使用しているリソースを確認するには、AWS ウェブサイトの [アカウントアクティビティ] ページまたは AWS マネジメントコンソールを使用するか、AWS CLI または AWS SDK 経由で CloudSearch API リクエストを送信します。
各検索インスタンスタイプがサポートできるデータ量は、主に、インデックスを作成するドキュメントのサイズと、ドメインに構成されているインデックスオプションによって変わります。
各検索インスタンスタイプの容量の実例を示すために、IMDb Movies のデータセットのサンプルドキュメントと構成を見てみましょう。次の例は、サイズが約 1 KB の IMDb の映画ドキュメントです。
{
"fields" : {
"directors" : [
"Francis Lawrence"
],
"release_date" : "2013-11-11T00:00:00Z",
"genres" : [
"Action",
"Adventure",
"Sci-Fi",
"Thriller"
],
"image_url" : "http://ia.media-imdb.com/images/M/MV5xMzNeMzAx._V1_SX400_.jpg",
"plot" : "Katniss Everdeen and Peeta Mellark become targets of the Capitol after their victory in the 74th Hunger Games sparks a rebellion in the Districts of Panem.","title" : "The Hunger Games: Catching Fire",
"rank" : 4,
"running_time_secs" : 8760,
"actors" : [
"Jennifer Lawrence",
"Josh Hutcherson",
"Liam Hemsworth"
],
"year": 2013
},
"id" : "tt1951264",
"type": "add"
}
このような映画ドキュメントのインデックスを作成し、検索するために、各ドキュメントフィールドのインデックスフィールドがある検索ドメインを構成します。各フィールドには複数のインデックスオプションを指定できます。例えば、フィールドの種類、フィールドが検索可能かどうか、有効なファセット、有効な戻り値、有効な並べ替え、有効なハイライトなどです。これらのインデックスオプションは、検索インスタンスに適合させるドキュメント数に直接影響があります。次の表は、IMDb 映画ドキュメントのインデックスフィールドの構成例です。
| 名前 |
タイプ |
検索 |
ファセット |
戻り値 |
並べ替え | ハイライト |
|---|---|---|---|---|---|---|
| actors |
text-array |
✔ | – | ✗ | – | ✗ |
| directors |
text-array |
✔ | – | ✗ | – | ✗ |
| genres |
literal-array |
✔ | ✔ | ✗ |
– | – |
| image_url |
text |
✗ | – | ✗ | ✗ | ✗ |
| plot |
text |
✔ | – | ✗ | ✗ | ✔ |
| rank | int | ✔ | ✗ | ✗ | ✔ | – |
| rating |
double |
✔ | ✔ | ✗ | ✔ | – |
| release_date |
date |
✔ | ✔ | ✗ | ✔ | – |
| running_time_secs |
int |
✔ | ✔ | ✗ | ✔ | – |
| タイトル |
text |
✔ | – | ✔ | ✔ | ✔ |
| year |
int |
✔ | ✔ | ✔ | ✔ | – |
ドキュメントサイズ(1 KB)とこのインデックス構成に基づき、各検索インスタンスタイプには、次の表に示すドキュメント容量があります。
| 検索インスタンスタイプ | データ容量 |
|---|---|
| スモールの検索インスタンス(search.m1.small) |
200 万件のドキュメント |
| ラージ検索インスタンス(search.m1.large) | 800 万件のドキュメント |
| エクストララージ検索インスタンス(search.m2.xlarge) |
1,600 万件のドキュメント |
| ダブルエクストララージインスタンス(search.m2.2xlarge) | 3,200 万件のドキュメント |
これは一つの例です。ドキュメントや構成が異なれば、インスタンスに適合するドキュメント数も大幅に変わります。1 つのダブルエクストララージ検索インスタンスの容量を超える場合、Amazon CloudSearch は、検索インデックスを追加のダブルエクストララージ検索インスタンスへと自動的に分割します。インデックスは最大 10 個のダブルエクストララージ検索インスタンスに分割して、数千万件または数億件のドキュメントをサポートできます。さらに縮小・拡張が必要な場合はお問い合わせください。
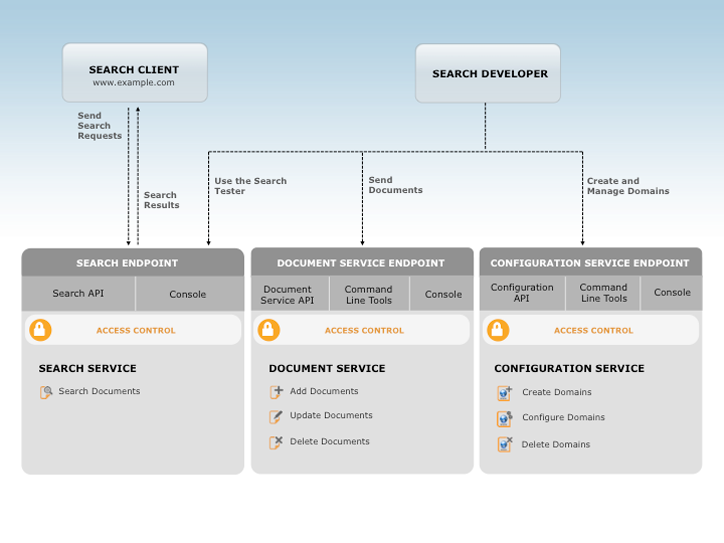
Amazon CloudSearch とは、次の 3 つのサービスを使用してやり取りします。
- 構成サービス – 検索ドメインの作成および構成を行う
- ドキュメントサービス – ドキュメントバッチをアップロードする
- 検索サービス – 検索および提案のリクエストを送信する
AWS Identity and Access Management(IAM)のポリシーを使用して、Amazon CloudSearch 構成サービスと各ドメインのドキュメントおよび検索サービスへのアクセスを管理します。
構成サービスにより、検索ドメインを作成および構成できます。検索ドメインを設定するには、一意の名前を指定し、インデックスオプション、テキスト分析、可用性オプション、スケーリングオプション、提案機能、および式を構成します。
- インデックス作成オプションは、インデックスに含まれるフィールドを指定します。AWS マネジメントコンソールまたは AWS CloudSearch コマンドラインツールを使用して、データをスキャンし、デフォルトのインデックス作成オプションを自動的に選択します。
- テキスト分析スキームは、text および text-array フィールドの言語固有のテキスト処理オプションを指定します。分析スキームは、インデックス作成中に無視するストップワードを制御し、複数の用語で共通の同義語を定義し、用語を共通の語幹にマッピングする方法を指定します。
- 可用性オプションを使用すると、2 つのアベイラビリティーゾーンにドメインのデプロイが可能になるため、サービスが中断した場合にも高い可用性を確保できます。
- スケーリングオプションを使用し、目的のインスタンスタイプ、レプリケーション数、およびパーティション数を指定することで、事前にドメインを測定できます。これは、大量のドキュメントをアップロードする必要がある場合、またはクエリトラフィックが急増することが予測される場合に便利です。
- 提案機能で、検索クエリが不完全でも一致候補を取得して、ユーザーの入力に合わせて結果を表示することができます。
- 式は、クエリ時に評価される数式です。式を使用して、検索結果のランキング方法を制御できます。デフォルトで、ドキュメント内の検索用語の出現頻度を考慮して、ドキュメントに適切度スコアでランクが付けられます。式を使用して、他の要素をランク付けに含めることもできます。例えば、ドメインに「popularity」という数値フィールドがある場合、人気度とデフォルトの適切度スコアを組み合わせて、適切で人気の高いドキュメントを検索結果の上のほうにランク付けできます。
ドキュメントサービスを使用して、ドメインの検索可能データを変更できます。各ドメインには個別のドキュメントサービス HTTP エンドポイントがあります。
データをドメインに送信するには、JSON または XML 形式で指定する必要があります。検索結果として返せるようにする各項目がドキュメントとして示されます。各ドキュメントには固有の ID、および検索し、結果を返すデータを含むフィールドが 1 つ以上あります。ドキュメントフィールドには UTF-8 の文字列なら何でも含めることができます。ドメインのインデックス作成オプションで、データのインデックス作成方法と使用方法を指定します。
検索サービスは、ドメインの検索および提案リクエストを処理します。各ドメインには個別の HTTP エンドポイントがあります。検索または提案リクエストを送信すると、検索サービスは一致するドキュメントのリストを返します。結果は JSON または XML で返されます。
Amazon CloudSearch は豊富なクエリ語を提供し、特定のフィールドを検索、複雑なブール値の検索、ファセット情報の取り出し、および結果に含めるデータの指定が可能になります。クエリ用語を処理し、Lucene や DisMax パーサーなどの他のクエリパーサーを使用する方法を制御するオプションも指定できます。
Amazon CloudSearch コンソールで検索テスターを使用して、サンプルクエリをテストすることができます。
このサービスのご利用にはアマゾン ウェブ サービスカスタマーアグリーメントが適用されます。