リソースセンターのご利用開始にあたって、 / 10 分間チュートリアル / ...
機械学習モデルを自動的に作成する
Amazon SageMaker Autopilot を使用
Amazon SageMaker は、すべての開発者やデータサイエンティストが機械学習 (ML) モデルを迅速に構築、トレーニング、デプロイできるようにするフルマネージド型サービスです。
このチュートリアルでは、コードを 1 行も記述せずに機械学習モデルを自動的に作成します。 AutoML 機能である Amazon SageMaker Autopilot を使用することで、完全に制御して可視化しながら、分類と回帰の最適な機械学習モデルを自動的に作成できます。
このチュートリアルでは、以下の方法を学びます。
- AWS アカウントを作成する
- Amazon SageMaker Studio をセットアップして Amazon SageMaker Autopilot にアクセスする
- Amazon SageMaker Studio を使用して公開データセットをダウンロードする
- Amazon SageMaker Autopilot を使用してトレーニング実験を作成する
- トレーニング実験のさまざまなステージを調べる
- トレーニング実験から最適なパフォーマンスのモデルを特定し、デプロイする
- デプロイしたモデルを使用して予測を行う
このチュートリアルでは、ユーザーは銀行で働く開発者という設定で進んでいきます。ユーザーは、顧客が預金証書 (CD) の申し込みを行うかどうかを予測するための機械学習モデルを開発するように求められました。モデルは、顧客の人口統計、マーケティングイベントへの反応、および外部の環境要因に関する情報を含むマーケティングデータセットでトレーニングされます。
| このチュートリアルの内容 | |
|---|---|
| 時間 | 10 分 |
| 料金 | 10 USD 未満 |
| ユースケース | 機械学習 |
| 製品 | Amazon SageMaker |
| 対象者 | 開発者 |
| レベル | 初心者 |
| 最終更新日 | 2020 年 5 月 12 日 |
ステップ 1:AWS アカウントを今すぐ無料で作成
このワークショップの料金は 10 USD 未満です。詳細については、Amazon SageMaker Studio 料金を参照してください。
AWS アカウントをお持ちですか? サインイン
ステップ 2.Amazon SageMaker Studio をセットアップする
Amazon SageMaker Autopilot にアクセスするために、以下の手順を実行して Amazon SageMaker Studio にオンボードします。
注意: 詳細については、Amazon SageMaker ドキュメントの Amazon SageMaker Studio の開始方法を参照してください。
a.Amazon SageMaker コンソールにサインインします。
注意: コンソールの右上隅で、Amazon SageMaker Studio が利用可能な AWS リージョンを選択してください。利用可能なリージョンの一覧については、Amazon SageMaker Studio にオンボードするを参照してください。


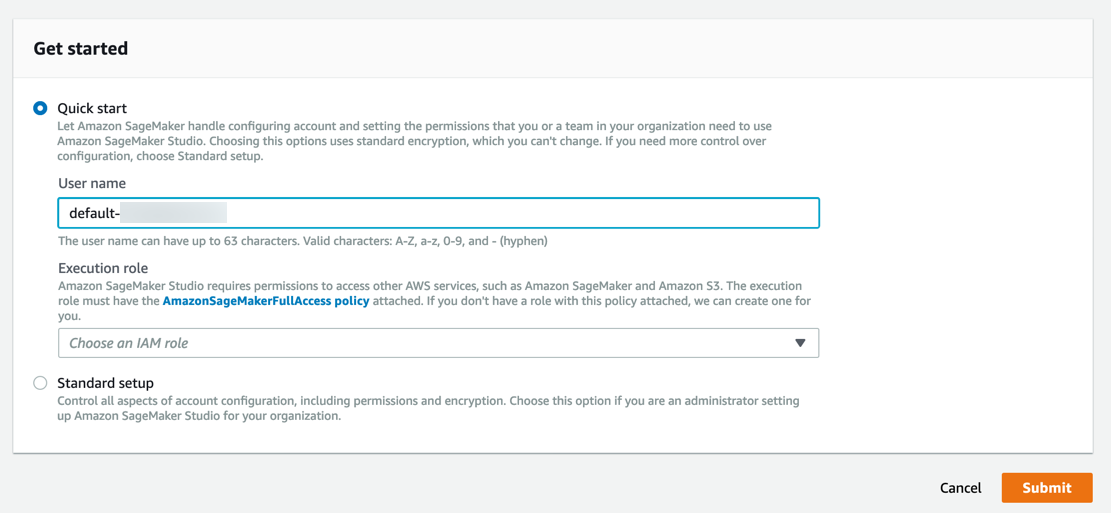
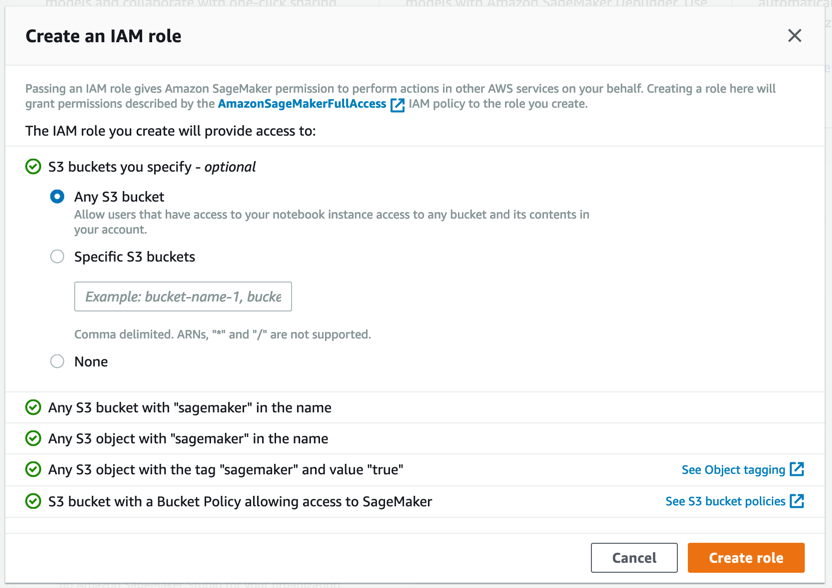
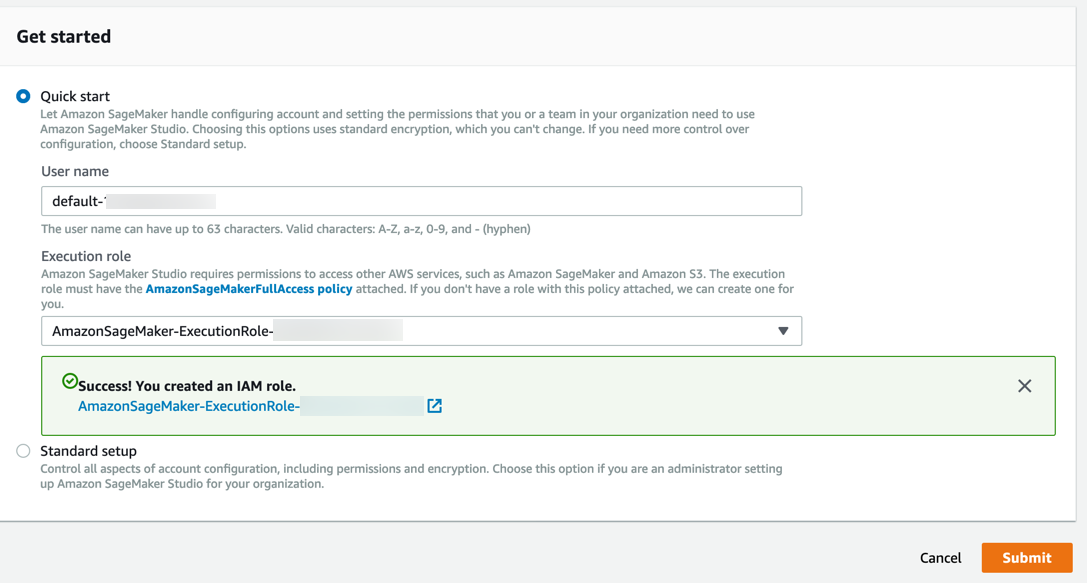
Amazon SageMaker で必要なアクセス許可を持つロールが作成され、作成されたロールがインスタンスに割り当てられます。
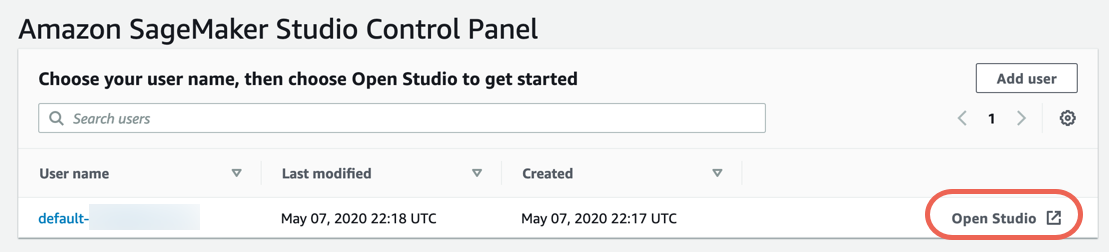
ステップ 3.データセットをダウンロードする
以下の手順を実行してデータセットをダウンロードし、探索します。
注意: 詳細については、Amazon SageMaker ドキュメントの Amazon SageMaker Studio ツアーを参照してください。
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d.以下のコードをコピーして新しいコードセルに貼り付け、[実行] を選択します。
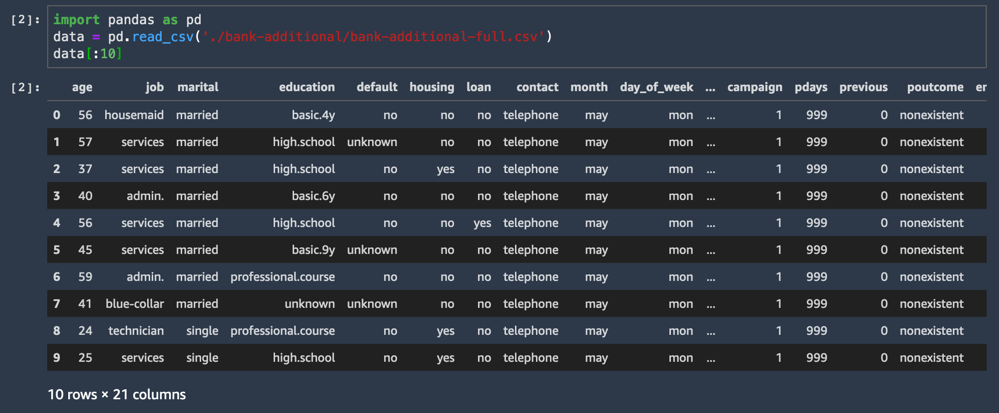
CSV データセットがロードされ、最初の 10 行が表示されます。
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]データセットの列の 1 つは y という名前で、各サンプルのラベル (この顧客がオファーを受け入れたかどうか) を示しています。
このステップで、データサイエンティストはデータの探索や新しい特徴量の作成などを開始します。Amazon SageMaker Autopilot を使用すると、これらの余分な手順を実行する必要はありません。コンマ区切り値ファイルで表形式のデータを (例えばスプレッドシートやデータベースから) アップロードして、予測するターゲット列を選択するのみで、Autopilot によって予測モデルが構築されます。
d.以下のコードをコピーして新しいコードセルに貼り付け、[実行] を選択します。
この手順を実行すると、CSV データセットが Amazon S3 バケットにアップロードされます。ユーザーが Amazon S3 バケットを作成する必要はありません。データをアップロードする際に、Amazon SageMaker によってユーザーのアカウント内に自動的にデフォルトのバケットが作成されます。
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
完了しました。 以下の例のように、コードの出力に S3 バケットの URI が表示されます。
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvユーザーのノートブックに表示された S3 URI を記録しておきます。記録した S3 URI は次のステップで必要になります。

ステップ 4.SageMaker Autopilot 実験を作成する
データセットをダウンロードし、Amazon S3 にステージングしました。次に、Amazon SageMaker Autopilot 実験を作成できます。実験は、同じ機械学習プロジェクトに関連した処理ジョブとトレーニングジョブの集合です。
新しい実験を作成するには、以下の手順を実行します。
注意: 詳細については、Amazon SageMaker ドキュメントの SageMaker Studio で Amazon SageMaker Autopilot 実験を作成するを参照してください。
a.Amazon SageMaker Studio の左側のナビゲーションペインで、[実験] (フラスコで表されているアイコン)、[実験を作成] の順に選択します。
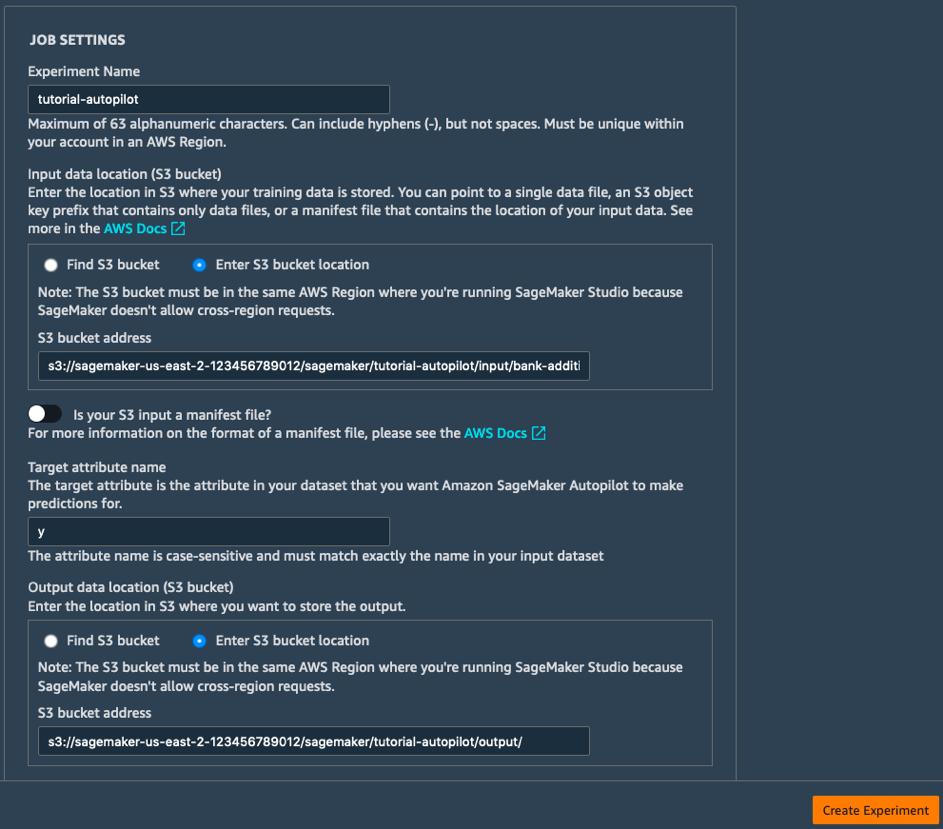
b.[ジョブ設定] フィールドに、以下のように入力します。
- 実験名: tutorial-autopilot
- 入力データのある S3 の場所: 上記の手順で表示した S3 URI
(e.g. s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - ターゲット属性の名前: y
- 出力データ用の S3 の場所: s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
([ACCOUNT-NUMBER] をユーザーのアカウント番号に置き換えてください)
c.残りの設定はデフォルトのままにして、[実験を作成] を選択します。
成功しました。 これで Amazon SageMaker Autopilot 実験が開始されます。 このプロセスによって、モデル、および実験が実行されている間リアルタイムで表示できる統計情報が生成されます。実験が完了したら、トライアルを表示して目標メトリクスでソートし、右クリックして、他の環境で使用するためにモデルをデプロイできます。
ステップ 5:SageMaker Autopilot 実験のさまざまなステージを調べる
実験を実行している間、SageMaker Autopilot 実験のさまざまなステージについて学習し、調べることができます。
このセクションでは、SageMaker Autopilot 実験のさまざまなステージの詳細について説明します。
- データの分析
- 特徴量エンジニアリング
- モデルチューニング
注意: 詳細については、SageMaker Autopilot のノートブック出力を参照してください。
データの分析
データの分析ステージでは、解決する必要のある問題のタイプが特定されます (線形回帰、二項分類、多項分類)。その後、候補となる 10 個のパイプラインが表示されます。パイプラインには、データの前処理のステップ (欠損値の処理、新しい特徴量の設計など) と、問題のタイプに適合する機械学習アルゴリズムを使用したモデルトレーニングのステップが組み合わされています。このステップが完了したら、特徴量エンジニアリングの作業に進みます。
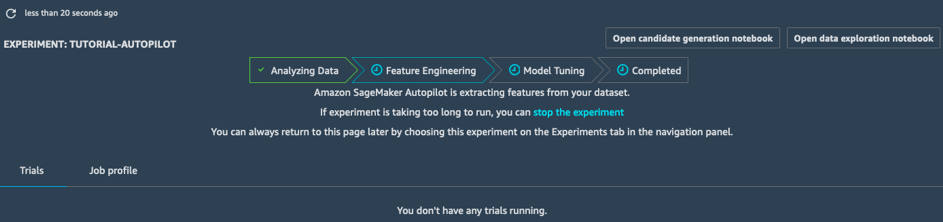
特徴量エンジニアリング
特徴量エンジニアリングステージでは、実験によって各候補パイプライン用にトレーニングデータセットと検証データセットが作成され、すべてのアーティファクトが S3 バケットに保存されます。特徴量エンジニアリングステージの間、自動生成された 2 つのノートブックを開いて表示できます。
- データ探索ノートブックには、データセットの情報と統計が含まれています。
- 候補生成ノートブックには、10 個のパイプラインの定義が含まれています。実際、これは実行可能なノートブックです。AutoPilot ジョブで行われたことを正確に再現することができ、さまざまなモデルがどのように作成されたかを理解することができます。また、必要であればそれを調整することもできます。
これらの 2 つのノートブックを使用することで、データの前処理方法やモデルの構築および最適化の方法を詳細に理解できます。この透明性は、Amazon SageMaker Autopilot の重要な特徴です。
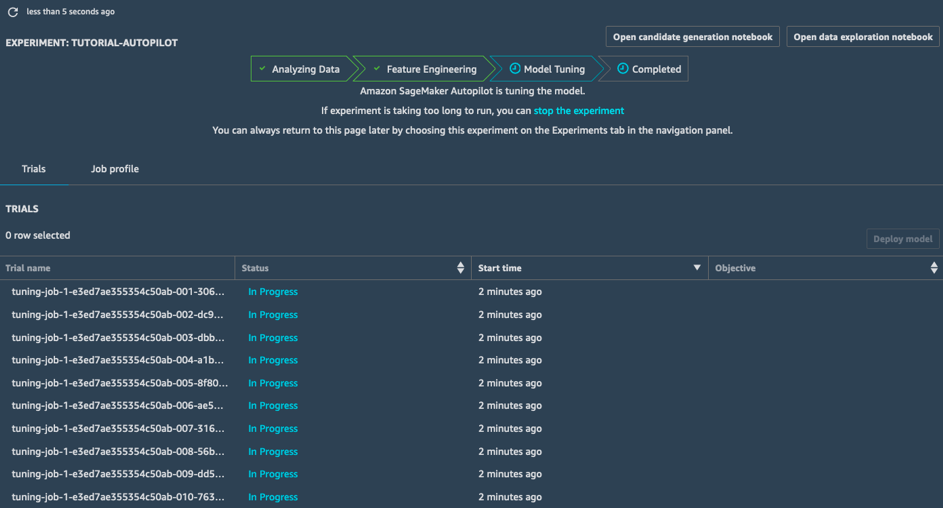
モデルチューニング
モデルチューニングステージでは、SageMaker Autopilot によって、各候補パイプラインとそれぞれの前処理済みのデータセット用にハイパーパラメータ最適化ジョブが起動されます。関連付けられたトレーニングジョブによって幅広いハイパーパラメータ値が探索され、高パフォーマンスモデルにすばやく集約されます。
このステージが完了すると、SageMaker Autopilot ジョブは完了します。SageMaker Studio ですべてのジョブを表示して、調べることができます。
ステップ 6.最適なモデルをデプロイする
実験が完了したため、チューニングされた最適なモデルを選択し、そのモデルを Amazon SageMaker によって管理されるエンドポイントにデプロイできます。
最適なチューニングジョブを選択し、モデルをデプロイするには、以下の手順に従います。
注意: 詳細については、Choose and deploy the best model を参照してください。
a.実験の [トライアル] リストで、[目標] の横にあるキャロットをクリックし、降順にチューニングジョブをソートします。最適なチューニングジョブが星印でハイライトされます。
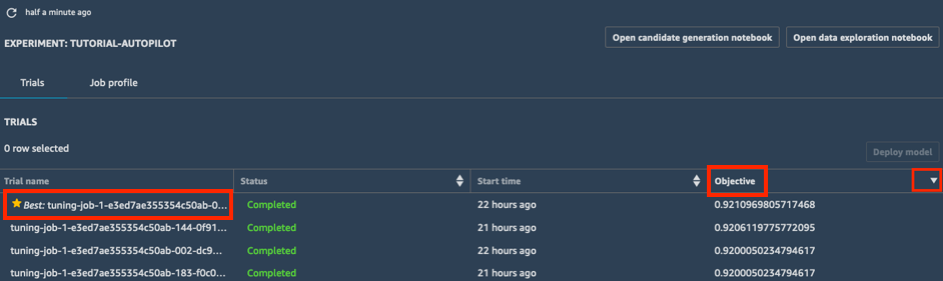
b.(星印によって示されている) 最適なチューニングジョブを選択し、[モデルのデプロイ] を選択します。
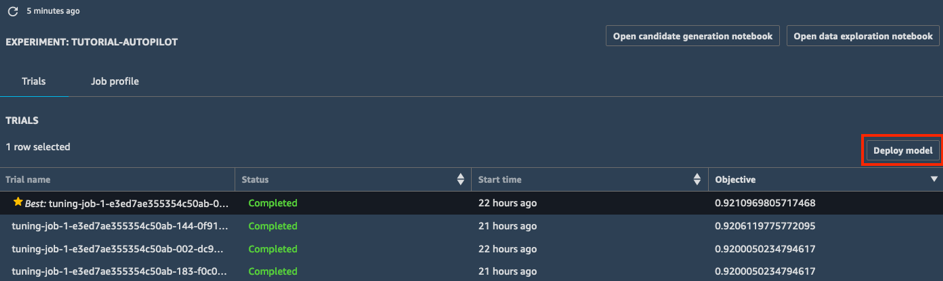
c.[モデルのデプロイ] ボックスで、エンドポイントに名前を付け (「tutorial-autopilot-best-model」など)、すべての設定をデフォルトのままにします。[モデルのデプロイ] を選択します。
モデルが、Amazon SageMaker によって管理される HTTPS エンドポイントにデプロイされます。
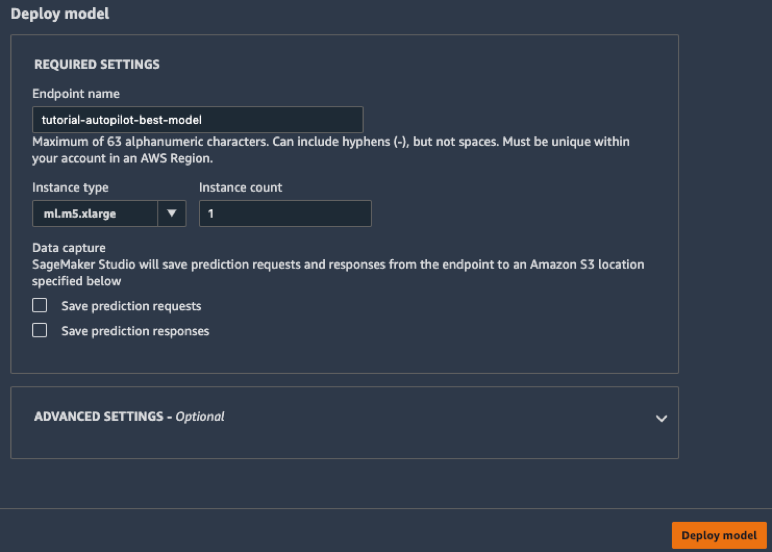
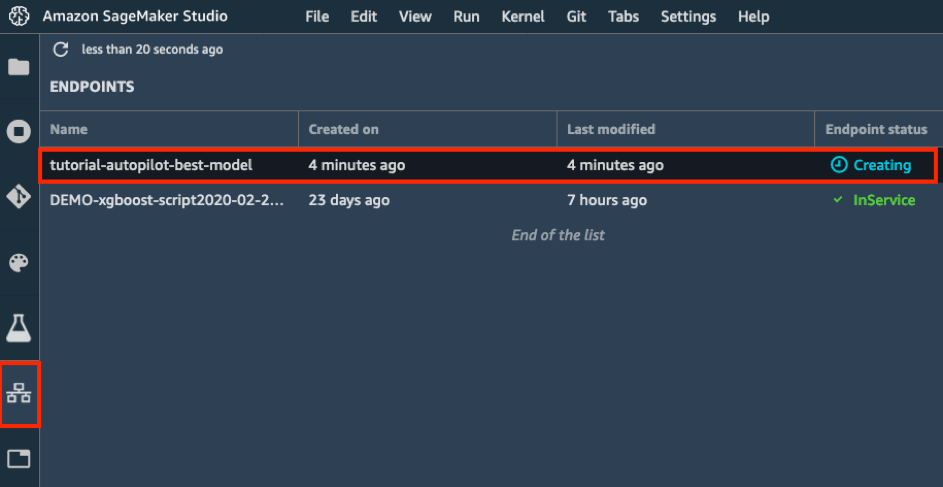
d.左側のツールバーで、[エンドポイント] アイコンを選択します。作成中のモデルを確認できます。モデルの作成には数分かかります。[エンドポイントステータス] が、[実行中] になったら、データを送信して予測を取得できます。
ステップ 7.モデルを使用して予測を行う
モデルをデプロイしたため、データセットの最初の 2,000 個のサンプルを予測できます。このために、boto3 SDK の invoke_endpoint API を使用します。このプロセスでは、機械学習の重要なメトリクスである正確性、適合率、再現率、F1 スコアを計算します。
モデルを使用して予測を行うには以下の手順に従います。
注意: 詳細については、Amazon SageMaker 実験による機械学習の管理を参照してください。
Jupyter ノートブックで、以下のコードをコピーして貼り付け、[実行] を選択します。
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
以下のような出力が表示されます。
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
この出力は、予測されたサンプル数を示す進行状況インジケーターです。
ステップ 8.クリーンアップ
このステップでは、このラボで使用したリソースを終了させます。
重要: あまり使用されていないリソースを終了することは、コストを削減するためのベストプラクティスです。リソースを終了しないと、お使いのアカウントに料金が発生します。
エンドポイントを削除する: Jupyter ノートブックで以下のコードをコピーして貼り付け、[実行] を選択します。
sess.delete_endpoint(endpoint_name=ep_name)すべてのトレーニングアーティファクト (モデル、前処理済みのデータセットなど) を削除する場合には、以下のコードをコピーしてコードセルに貼り付け、[実行] を選択します。
注意: ACCOUNT_NUMBER をユーザーのアカウントに置き換えてください。
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/お疲れ様でした。
Amazon SageMaker Autopilot を使用して、最適な精度の機械学習モデルを自動的に作成することができました。
推奨する次のステップ
機械学習のサンプルノートブックを調べる
Amazon SageMaker Studio のツアーを見る
Amazon SageMaker Autopilot の詳細を学ぶ
詳細についてはブログ記事を読むか、Autopilot の動画シリーズをご覧ください。