概要
実行する内容
このガイドでは、以下のことを行います。
- データを可視化して分析し、重要な関係を理解する
- データをクリーンアップし、新しい特微量を生成するために変換を適用する
- データ準備ワークフローを繰り返し行うためのノートブックを自動的に生成する
前提条件
このチュートリアルを開始する前に、以下のものが必要です。
- AWS アカウント: まだお持ちでない場合は、AWS 環境の設定入門ガイドに従って簡単な概要を確認してください。
AWS の使用経験
初心者
所要時間
30 分
完了までのコスト
このチュートリアルにかかるコストの見積もりは、Amazon SageMaker の料金を参照してください。
次のことが求められます
AWS アカウントにログインしている必要があります。
使用するサービス
Amazon SageMaker Data Wrangler
最終更新日
2022 年 7 月 1 日
実装
ステップ 1: Amazon SageMaker Studio ドメインを設定する
Amazon SageMaker では、コンソールを使用して視覚的にモデルをデプロイするか、SageMaker Studio または SageMaker ノートブックのいずれかを使用してプログラムでモデルをデプロイすることができます。このチュートリアルでは、SageMaker Studio ノートブックを使用してプログラムでモデルをデプロイしますが、これには SageMaker Studio ドメインが必要です。
AWS アカウントは、1 つのリージョンにつき 1 つの SageMaker Studio ドメインのみを持つことができます。米国東部 (バージニア北部) リージョンに SageMaker Studio ドメインを既にお持ちの場合は、SageMaker Studio 設定ガイドに従って必要な AWS IAM ポリシーを SageMaker Studio アカウントにアタッチし、ステップ 1 をスキップして直接ステップ 2 に進みます。
既存の SageMaker Studio ドメインがない場合は、ステップ 1 に進み、SageMaker Studio ドメインを作成し、このチュートリアルの残りの部分に必要なアクセス許可を追加する AWS CloudFormation テンプレートを実行します。
AWS CloudFormation スタックリンクを選択します。このリンクから AWS CloudFormation コンソールが開き、SageMaker Studio ドメインと studio-user というユーザーが作成されます。また、SageMaker Studio アカウントに必要なアクセス許可を追加します。CloudFormation コンソールで、右上に表示される [リージョン] が [米国東部 (バージニア北部)] であることを確認します。 [スタック名] は [CFN-SM-IM-Lambda-catalog] とし、変更しないようにします。 このスタックは、すべてのリソースを作成するのに 10 分ほどかかります。
このスタックは、アカウントに既にパブリック VPC が設定されていることを想定しています。パブリック VPC がない場合、パブリック VPC の作成方法については、単一のパブリックサブネットを持つ VPC を参照してください。

[I acknowledge that AWS CloudFormation might create IAM resources] (私は、AWS CloudFormation が IAM リソースを作成する可能性があることを認めます) を選択し、[Create stack] (スタックの作成) を選択します。

[CloudFormation] ペインで、[スタック] を選択します。スタックが作成されるまで 10 分程度かかります。スタックが作成されると、スタックのステータスが [CREATE_IN_PROGRESS] から [CREATE_COMPLETE] に変更されます。

ステップ 2: 新しい SageMaker Data Wrangler フローを作成する
SageMaker Data Wrangler は、Amazon S3、Amazon Athena、Amazon Redshift、Snowflake、Databricks など、さまざまなソースからデータを受け取ります。このステップでは、Amazon S3 に保存されている UCI German の信用リスクデータセットを使用して、新しい SageMaker Data Wrangler フローを作成します。このデータセットには、個人に関する人口統計および財務情報と、個人の信用リスクレベルを示すラベルが含まれています。
コンソールの検索バーに [SageMaker Studio] と入力し、[SageMaker Studio] を選択します。

SageMaker コンソール右上にあるリージョンのドロップダウンリストから、[米国東部 (バージニア北部)] を選択します。[Launch app] (アプリケーションの起動) で [Studio] を選択し、studio-user プロファイルを使用して SageMaker Studio を開きます。

SageMaker Studio インターフェイスを開きます。ナビゲーションバーで、[ファイル]、[新規作成]、[Data Wrangler Flow] を選択します。

[インポート] タブで、[データのインポート] の下にある [Amazon S3] を選択します。
[S3 URI パス] フィールドに [s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv] を入力し、[進む] を選択します。[オブジェクト名] で [german_credit_data.csv] をクリックし、[インポート] を選択します。

ステップ 3: データのプロファイリング
このステップでは、SageMaker Data Wrangler を使用して、トレーニングデータセットの品質を評価します。 クイックモデル機能を使用すると、データセットに含まれる特徴量の期待予測品質と予測力をおおまかに推定することができます。
[データフロー] タブのデータフロー図において、+ アイコン、[分析の追加] を選択します。
[分析の作成] パネルで、[分析タイプ] に、[ヒストグラム] を選択します。
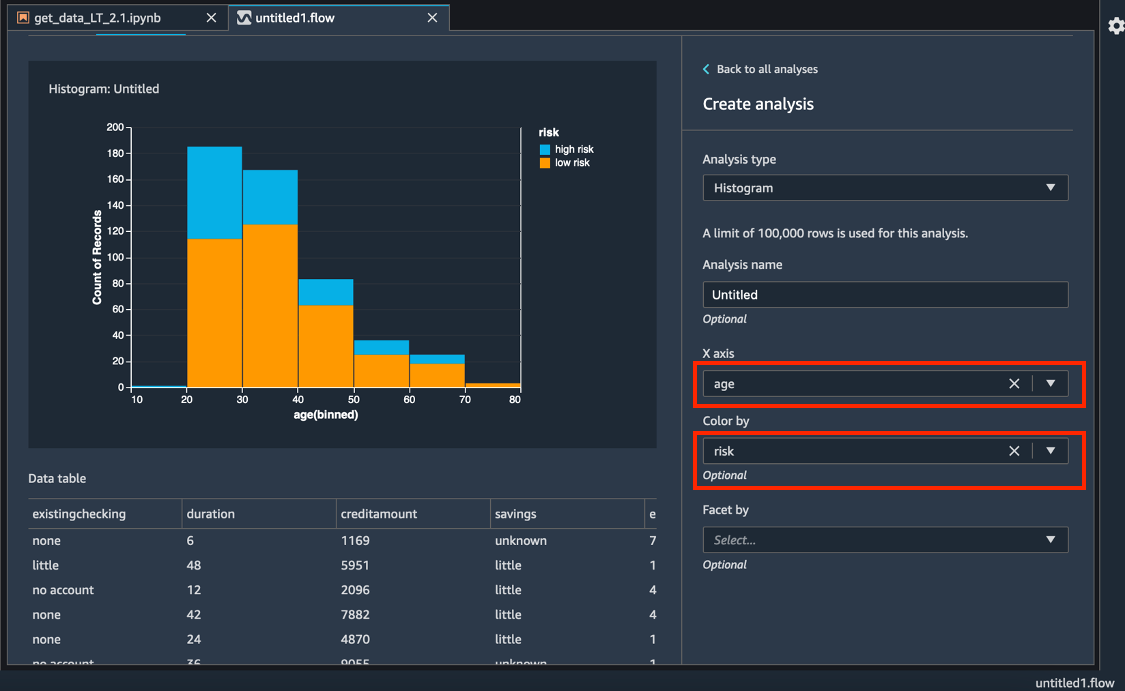
[X 軸] に、[年齢] を選択します。
[Color by] (色) で、[リスク] を選択します。
[プレビュー] を選択して、[年齢] ブラケットで色分けされた [信用リスク] フィールドのヒストグラムを生成します。
[保存] を選択して、この分析をフローに保存します。
データセットが、リスクターゲット変数を予測するモデルのトレーニングにどの程度適しているかを理解するために、クイックモデル分析を実行します。[分析] タブで、[Create new analysis] (新規分析の作成) を選択します。
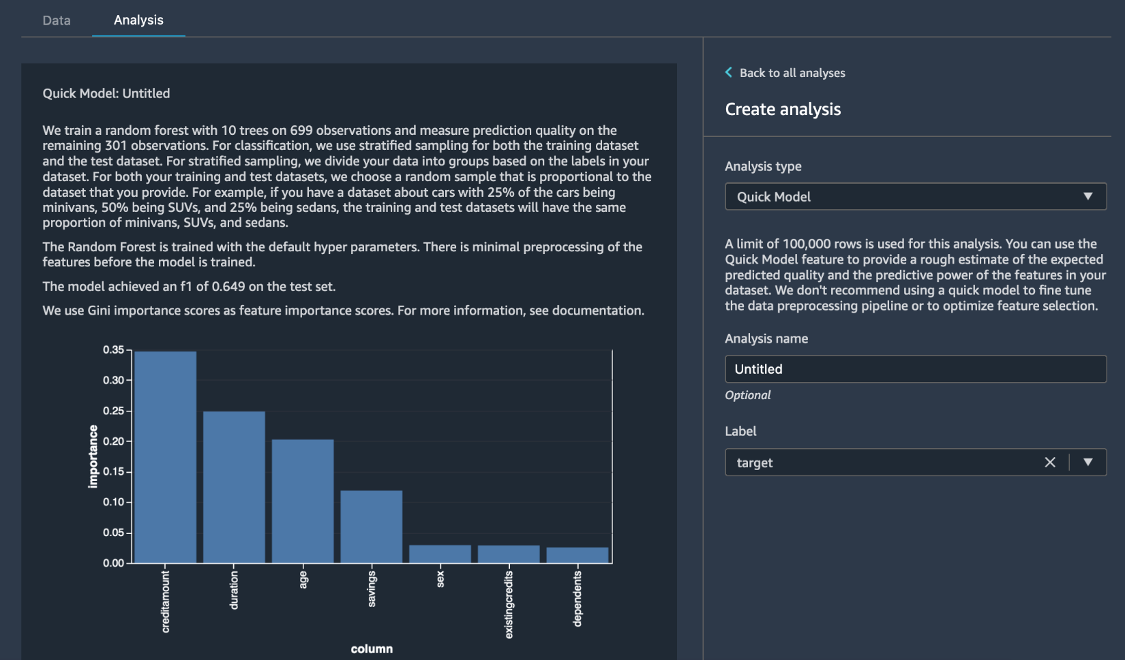
[分析の作成] ペインで、[分析タイプ] に [クイックモデル] を選択します。[ラベル] で、[リスク] を選択し、[プレビュー] を選択します。 [クイックモデル] ペインには、使用したモデルの簡単な概要と、F1 スコアや特徴量の重要度などの基本統計が表示され、データセットの品質を評価するのに役立ちます。[保存] を選択します。
ステップ 4: データフローに変換を追加する
SageMaker Data Wrangler は、ビジュアルインターフェイスを提供し、事前に構築されたさまざまな変換を追加できるため、データ処理が簡素化されます。また、SageMaker Data Wrangler を使用してカスタム変換を書くこともできます。 このステップでは、ビジュアルエディタを使用して、複雑な文字列データの平坦化、カテゴリのエンコード、列の名前の変更、および不要な列の削除を行います。 次に、[status_sex] 列を [marital_status] (婚姻状態) と [sex] (性別) という 2 つの新しい列に分割します。
データフロー図に移動するには、[データフロー] を選択します。

データフロー図上で、+ アイコン、[Add transform] (変換の追加) を選択します。

[すべてのステップ] ペインで、[ステップの追加] を選択します。

[ADD TRANSFORM] (変換の追加) リストから、[検索と編集] を選択します。これは、文字列データの操作に使用される変換です。

[検索と編集] ペインの [Transform] (変換) で、[Split string by delimiter] (文字列をデリミタで分割) を選択します。 [Input columns] (入力列) で、[status_sex] を選択します。 [デリミタ] ボックスには、: 記号を入力します。 [Output column] (出力列) には、[vec] と入力します。[プレビュー] を選択し、[追加] を選択します。
この変換では、[status_sex] 列を分割して、データフレームの末尾に [vec] という新しい列が作成されます。status_sex 列には、コロンで区切られた文字列が含まれ、新しい [vec] 列には、カンマで区切られたベクトルが含まれます。

[vec] 列を分割し、2 つの新しい列、[sex_split_0] と [sex_split_1] を作成します。
[すべてのステップ] で、[+ ステップの追加] を選択します。
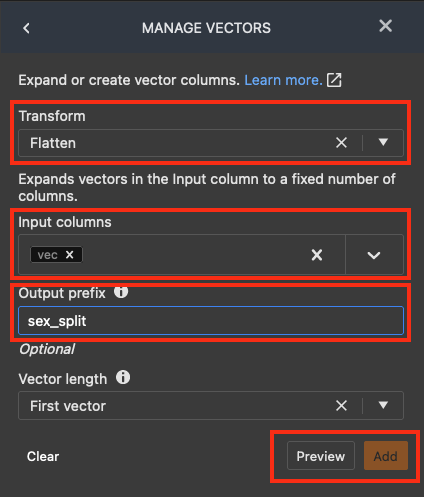
[ADD TRANSFORM] (変換の追加) リストから、[ベクトルの管理] を選択します。
[ベクトルの管理] ペインで、[Transform] (変換) に、[Flatten] (平坦) を選択します。 [Input columns] (入力列) で、[vec] を選択します。[output_prefix] に、[sex_split] を入力します。
[プレビュー] を選択し、[追加] を選択します。
分割変換で作成された列の名前を変更します。
[すべてのステップ] ペインで、[+ ステップの追加] を選択します。
[ADD TRANSFORM] (変換の追加) リストから、[Manage columns] (列の管理) を選択します。
[MANAGE COLUMNS] (列の管理) ペインの [Transform] (変換) で、[Rename column] (列名の変更) を選択します。[Input columns] (入力列) で、[sex_split_0] を選択します。 [新しい名前] ボックスに、[sex] (性別) と入力します。
[プレビュー] を選択し、[追加] を選択します。
この手順を繰り返して、[sex_split_1] を [marital_status] (婚姻状態) に名称変更します。

ステップ 5: カテゴリカルエンコーディングの追加
このステップでは、モデリングターゲットを作成し、カテゴリカル変数をエンコードします。カテゴリカルエンコーディングは、文字列データタイプのカテゴリを数値ラベルに変換します。数値ラベルはさまざまなモデルタイプで使用できるため、一般的な前処理タスクです。
このデータセットでは、信用リスクの分類は、[high risk] (高リスク) と [low risk] (低リスク) という文字列で表されています。このステップでは、この分類を 0 か 1 かのバイナリ表現に変換します。
[すべてのステップ] ペインで、[+ ステップの追加] を選択します。[ADD TRANSFORM] (変換の追加) リストから、[Encode categorical] (カテゴリカルエンコード) を選択します。SageMaker Data Wrangler には、3 つの変換タイプがあります。順序エンコード、ワンホットエンコード、類似性エンコードです。[ENCODE CATEGORICAL] (カテゴリカルエンコード) ペインの [Transform] (変換) では、デフォルトの [Ordinal encode] (順次エンコード) のままにしておきます。 [Input columns] (入力列) で、[リスク] を選択します。 [Output column] (出力列) には、[ターゲット] と入力します。 このチュートリアルでは、[Invalid handling strategy] (無効な処理戦略) ボックスは無視します。 [プレビュー] を選択し、[追加] を選択します。

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

[Encode categorical] (カテゴリカルエンコード) 変換を使用して、残りの列、[住居]、[仕事]、[sex] (性別)、および [marital_status] (婚姻状態) を以下のようにエンコードします。[すべてのステップ] で、[+ ステップの追加] を選択します。 [ADD TRANSFORM] (変換の追加) リストから、[Encode categorical] (カテゴリカルエンコード) を選択します。[ENCODE CATEGORICAL] (カテゴリカルエンコード) ペインの [Transform] (変換) では、デフォルトの [Ordinal encode] (順次エンコード) のままにしておきます。 [Input columns] (入力列) には、[住居]、[仕事]、[sex] (性別)、および [marital_status] (婚姻状態) を選択します。[Output column] (出力列) は空白のままにして、エンコードされた値がカテゴリ値に置き換わるようにします。[プレビュー] を選択し、[追加] を選択します。

数値列 [creditamount] をスケールするために、信用量にスケーラーを適用して、この列のデータの分布を正規化します。[すべてのステップ] ペインで、[+ ステップの追加] を選択します。 変換の追加リストから、[Process numeric] (数値処理) を選択します。[Scaler] (スケーラー) では、デフォルトオプションの [Standard scaler] (標準スケーラー) を選択します。[Input columns] (入力列) で、[creditamount] を選択します。[プレビュー] を選択し、[追加] を選択します。


変換した元の列を削除するため、[すべてのステップ] ペインで、[+ ステップの追加] を選択します。[ADD TRANSFORM] (変換の追加) リストから、[Manage columns] (列の管理) を選択します。[MANAGE COLUMNS] (列の管理) ペインの [Transform] (変換) で、[Drop Column] (列の削除) を選択します。 [Columns to drop] (削除する列) で、[status_sex]、[existingchecking]、[employmentsince]、[リスク]、および [vec] を選択します。[プレビュー] を選択し、[追加] を選択します。

ステップ 6: データのバイアスチェックを行う
このステップでは、Amazon SageMaker Clarify を使用してデータのバイアスをチェックします。トレーニングデータとモデルの可視性を高めることで、バイアスの特定と制限、予測の説明を可能にします。
左上の [データフロー] を選択し、データフロー図に戻ります。[+] アイコンを選択し、[分析の追加] を選択します。[分析の作成] ペインで、[分析タイプ] に [バイアスレポート] を選択します。[分析名] に、任意の名前を入力します。[Select the column your model predicts (target)] (モデルが予測する列を選択する (ターゲット)) で、[ターゲット] を選択します。[値] チェックボックスは選択したままにします。[予測値] ボックスに、[1] を入力します。[Select the column to analyze for bias] (バイアスを分析する列を選択する) には、 [sex] (性別) を選択します。[Choose bias metrics] (バイアスメトリクスの選択) では、デフォルトの選択のままにしておきます。[Check for bias] (バイアスをチェックする) を選択します。
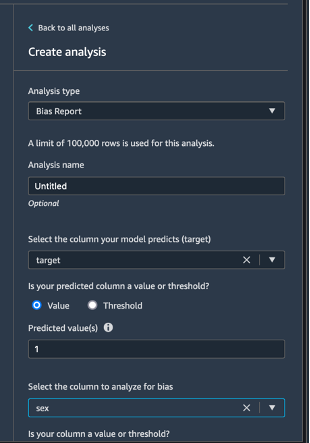
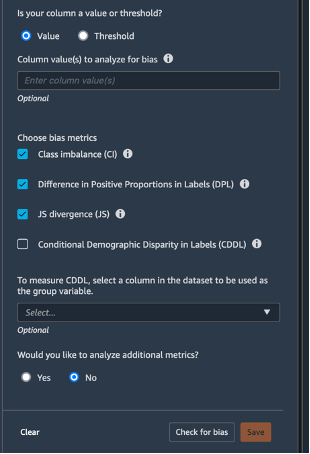
数秒後、SageMaker Clarify はレポートを生成し、クラス不均衡 (CI) やラベルの正比例の差 (DPL) など、バイアスに関する多くのメトリクスでターゲットとテストの列がどのようなスコアを獲得したかが示されます。この場合、データは、[sex] (性別) の点ではわずかにバイアスがかかり (-0.38)、[labels] (ラベル) の点ではあまりバイアスがかかっていません (0.075)。このレポートに基づいて、SageMaker Data Wrangler の組み込み SMOTE 変換を使用するなど、バイアスの是正方法を検討することができます。このチュートリアルの目的では、修正ステップをスキップします。[保存] を選択して、バイアスレポートをデータフローに保存します。

ステップ 7: データフローをエクスポートする
データフローを Jupyter Notebook にエクスポートして、ステップを SageMaker Processing ジョブとして実行します。これらのステップは、定義したデータフローに従ってデータを処理し、出力を Amazon S3 または Amazon SageMaker Feature Store に保存します。
データフローダイアグラムから、+ アイコン、[Export to] (エクスポート先)、[Amazon S3 (via Jupyter Notebook)] (Amazon S3 (Jupyter Notebook を介して)) を選択します。これにより、SageMaker Studio にノートブックが作成され、生成された SageMaker Processing ジョブを実行して変換後のデータセットを作成することができます。 このノートブックを実行すると、デフォルトの S3 バケットに結果が保存されます。



ステップ 8: リソースのクリーンアップ
意図しない料金が発生しないように、使用しなくなったリソースは削除することがベストプラクティスです。
S3 バケットを削除するには、以下を実行します。
- Amazon S3 コンソールを開きます。ナビゲーションバーで、[バケット]、sagemaker-<your-Region>-<your-account-id> を選択し、[data_wrangler_flows] の横のチェックボックスを選択します。その後、[Delete] (削除) を選択します。
- [Delete objects] (オブジェクトの削除) ダイアログボックスで、削除するオブジェクトが正しく選択されていることを確認し、[Permanently delete objects] (オブジェクトの完全削除) 確認ボックスに [permanently delete] (完全に削除する) と入力します。
- これが完了し、バケットが空になったら、再度同じ手順で sagemaker-<your-Region>-<your-account-id>バケットを削除することができます。

このチュートリアルでノートブック画像を実行するために使用されているデータサイエンスカーネルは、カーネルを停止するか、次のステップを実行してアプリケーションを削除するまで、料金が蓄積されます。 詳細については、Amazon SageMaker Developer Guide のリソースのシャットダウンを参照してください。
SageMaker Studio のアプリケーションを削除するには、次の手順を実行します。SageMaker Studio コンソールで、[studio-user] を選択し、[Delete app] (アプリケーションの削除) を選択して [Apps] (アプリケーション) の下に表示されているアプリケーションをすべて削除します。[ステータス] が [削除] に変わるまで待ちます。

ステップ 1 で既存の SageMaker Studio ドメインを使用した場合は、ステップ 8 の残りをスキップして、結論のセクションに直接進んでください。
ステップ 1 で CloudFormation テンプレートを実行して新しい SageMaker Studio ドメインを作成した場合は、次のステップに進み、CloudFormation テンプレートで作成したドメイン、ユーザー、リソースを削除してください。
CloudFormation コンソールを開くには、AWS コンソールの検索バーに [CloudFormation] と入力し、検索結果から [CloudFormation] を選択します。

[CloudFormation] ペインで、[スタック] を選択します。ステータスドロップダウンリストから、[アクティブ] を選択します。スタック名で、[CFN-SM-IM-Lambda-catalog] を選択し、スタックの詳細ページを開きます。

CFN-SM-IM-Lambda-catalog スタックの詳細ページで、[削除] を選択して、ステップ 1 で作成したリソースと一緒にスタックを削除します。

まとめ
Amazon SageMaker Data Wrangler を使用して、機械学習モデルをトレーニングするためのデータを準備することに成功しました。SageMaker Data Wrangler は、列タイプの変換、1 つのホットエンコーディング、平均または中央値を用いた欠落データの補完、列の再スケール、日付/時間の埋め込みなど、300 以上の事前設定済みデータ変換を提供しているため、コードを 1 行も記述せずにモデルに効果的に使用できる形式にデータを変換できます。