



データモデリングとは何ですか?
データモデリングは、組織の情報収集および管理システムを定義する視覚的表現またはブループリントを作成するプロセスです。このブループリントまたはデータモデルは、データアナリスト、科学者、エンジニアなどのさまざまなステークホルダーが組織のデータの統一されたビューを作成するのに役立ちます。このモデルは、ビジネスが収集するデータ、さまざまなデータセット間の関係、およびデータの保存と分析に使用される方法の概要を示します。
データモデリングが重要なのはなぜですか?
今日の組織は、さまざまなソースから大量のデータを収集しています。しかし、生データだけでは不十分です。データを分析して、有益なビジネス上の意思決定を行うための実用的なインサイトを得る必要があります。正確なデータ分析には、効率的なデータ収集、保存、処理が必要です。いくつかのデータベーステクノロジーとデータ処理ツールがあり、データセットが異なれば、効率的な分析のために異なるツールが必要になります。
データモデリングにより、データを理解し、このデータを保存および管理するための適切なテクノロジーを選択する機会が得られます。建築家が家を建てる前に設計図を作成するのと同じように、ビジネスのステークホルダーは、組織のデータベースソリューションを設計する前にデータモデルを設計します。
データモデリングには次のメリットがあります。
- データベースソフトウェア開発のエラーを低減する
- データベースの設計と作成の速度と効率を高める
- 組織全体でデータドキュメントとシステム設計に一貫性を持たせる
- データエンジニアとビジネスインテリジェンスチーム間のコミュニケーションを円滑にする
データモデルにはどのような種類がありますか?
データモデリングは通常、データを概念的に表現することから始まり、選択したテクノロジーのコンテキストで再び表現します。アナリストとステークホルダーは、データの設計段階でいくつかの異なる種類のデータモデルを作成します。データモデルの 3 つの主要な種類を次に示します。
概念データモデル
概念データモデルは、データの全体像を示します。これは次のことを説明します。
- システムに含まれるデータ
- データの属性と条件またはデータの制約
- データに関連するビジネスルール
- データを最適に整理する方法
- セキュリティとデータの完全性の要件
ビジネスのステークホルダーとアナリストは通常、概念モデルを作成します。これは、正式なデータモデリングルールに従わない単純な図式表現です。重要なのは、技術的および非技術的なステークホルダーが共通のビジョンを共有し、データプロジェクトの目的、範囲、および設計について合意するのに役立つことです。
概念データモデルの例
例えば、自動車ディーラーの概念データモデルでは、次のようなデータエンティティが表示される場合があります。
- ディーラーが持つさまざまな店舗に関する情報を表す Showroom エンティティ
- ディーラーが現在在庫している複数の車を表す Car エンティティ
- ディーラーで購入したすべての顧客を表す Customer エンティティ
- 実際の販売に関する情報を表す Sales エンティティ
- ディーラーで働くすべての営業担当者に関する情報を表す Salesperson エンティティ
この概念モデルには、次のようなビジネス要件も含まれます。
- すべての車は特定のショールームに属している必要があります。
- すべての販売には、少なくとも 1 人の営業担当者と 1 人の顧客が関連付けられている必要があります。
- すべての車には、ブランド名と製品番号が必要です。
- すべての顧客は、自分の電話番号とメールアドレスを提供する必要があります。
したがって、概念モデルは、ビジネスルールと基盤となる物理データベース管理システム (DBMS) の間のブリッジとして機能します。概念データモデルは、ドメインモデルとも呼ばれます。
論理データモデル
論理データモデルは、概念データクラスを技術データ構造にマッピングします。これらは、概念データモデルで識別されたデータ概念と複雑なデータ関係について、次のような詳細を提供します。
- さまざまな属性のデータ型 (文字列や数値など)
- データエンティティ間の関係
- データの主たる属性または主要なフィールド
データアーキテクトとアナリストが協力して論理モデルを作成します。これらのデータアーキテクトとアナリストは、表現を作成するためにいくつかの正式なデータモデリングシステムの 1 つに従います。アジャイルチームは、このステップをスキップして、概念モデルから物理モデルに直接移行することを選択する場合があります。ただし、これらのモデルは、データウェアハウスと呼ばれる大規模なデータベースの設計、および自動レポートシステムの設計に役立ちます。
論理データモデルの例
自動車ディーラーの例では、論理データモデルは概念モデルを拡張し、次のようにデータクラスを詳しく確認します。
- Showroom エンティティには、テキストデータとしての名前と場所、数値データとしての電話番号などのフィールドがあります。
- Customer エンティティには、xxx@example.com または xxx@example.com.yy の形式のフィールドメールアドレスがあります。フィールド名の長さは 100 文字以内である必要があります。
- Sales エンティティには、フィールドとして顧客の名前と営業担当者の名前があり、日付データ型として販売日、小数データ型として金額があります。
したがって、論理モデルは、概念データモデルと、デベロッパーがデータベースの作成に利用する基盤となるテクノロジーおよびデータベース言語との間のブリッジとして機能します。ただし、これらはテクノロジーに依存しないため、任意のデータベース言語で実装できます。データエンジニアとステークホルダーは通常、論理データモデルを作成した後にテクノロジーに関する意思決定を行います。
物理データモデル
物理データモデルは、論理データモデルを特定の DBMS テクノロジーにマッピングし、ソフトウェアの用語を使用します。例えば、次の詳細が表示されます。
- DBMS で表現されるデータフィールドタイプ
- DBMS で表現されるデータ関係
- パフォーマンスチューニングなどの追加の詳細
データエンジニアは、最終的な設計を実装する前に物理モデルを作成します。また、正式なデータモデリング手法に従って、設計のすべての側面をカバーしていることを確認します。
物理データモデルの例
自動車ディーラーが Amazon S3 Glacier Flexible Retrieval にデータアーカイブを作成することを決定したとします。このディーラーの物理データモデルは、次の仕様を記述します。
- Sales では、販売額は float データ型であり、販売日はタイムスタンプデータ型です。
- Customers では、顧客名は文字列データ型です。
- S3 Glacier Flexible Retrieval の用語では、ボールトはデータの地理的な場所です。
物理データモデルには、ボールトを作成する AWS リージョンなどの追加の詳細も含まれています。 したがって、物理データモデルは、論理データモデルと最終的なテクノロジー実装の間のブリッジとして機能します。
データモデリング手法にはどのような種類がありますか?
データモデリング手法は、種々のデータモデルを作成するために利用できるさまざまな方法です。このアプローチは、データベースの概念とデータガバナンスのイノベーションの結果として、時間が経過する中で進化してきました。データモデリングの主要な種類を次に示します。
階層型データモデリング
階層型データモデリングでは、さまざまなデータ要素間の関係をツリーのような形式で表すことができます。階層型データモデルは 1 対多リレーションシップを表し、親またはルートデータクラスが複数の子にマッピングされます。
自動車ディーラーの例では、1 つのショールームに、複数の車と、そこで勤務している営業担当者が存在するため、親クラスの Showroom には、子として Cars と Salespeople の両方のエンティティがあります。
グラフデータモデリング
階層型データモデリングは、時間が経過するにつれてグラフデータモデリングに進化を遂げました。グラフデータモデルは、エンティティを同等に扱うデータ関係を表します。エンティティは、親または子の概念がなくても、1 対多リレーションシップまたは多対多リレーションシップで相互にリンクできます。
例えば、1 つのショールームに複数の営業担当者を配置できます。また、場所によってシフトが異なる場合は、1 名の営業担当者が複数のショールームで勤務することもできます。
リレーショナルデータモデリング
リレーショナルデータモデリングは、データクラスをテーブルとして視覚化する一般的なモデリングアプローチです。さまざまなデータテーブルが、実際のエンティティの関係を表すキーを使用して結合またはリンクします。リレーショナルデータベーステクノロジーを利用して構造化データを格納できます。リレーショナルデータモデルは、リレーショナルデータベースの構造を表すための便利な方法です。
例えば、自動車ディーラーには、次に示すように、Salespeople テーブルと Car テーブルを表すリレーショナルデータモデルがあることが考えられます。
| Salesperson ID | 名前 |
| 1 | Jane |
| 2 | John |
| Car ID | 車のブランド |
| C1 | XYZ |
| C2 | ABC |
Salesperson ID と Car ID は、個々の実際のエンティティを一意に識別するプライマリキーです。ショールームテーブルでは、これらのプライマリキーはデータセグメントをリンクする外部キーとして機能します。
| Showroom ID | Showroom 名 | Salesperson ID | Car ID |
| S1 | NY Showroom | 1 | C1 |
リレーショナルデータベースでは、プライマリキーと外部キーが連携してデータの関係を示します。前のテーブルは、ショールームが営業担当者と車を持つことができることを示しています。
実体関連データモデリング
実体関連 (ER) データモデリングでは、正式な図を利用して、データベース内のエンティティ間の関係を表します。データアーキテクトは、いくつかの ER モデリングツールを使用してデータを表します。
オブジェクト指向データモデリング
オブジェクト指向プログラミングでは、オブジェクトと呼ばれるデータ構造を利用してデータを格納します。これらのデータオブジェクトは、実際のエンティティをソフトウェアで抽象化したものです。例えば、オブジェクト指向のデータモデルでは、自動車ディーラーには、名前、住所、電話番号などの属性を持つ Customer などのデータオブジェクトがあることが考えられます。顧客データを保存して、すべての実際の顧客が顧客データオブジェクトとして表されるようにします。
オブジェクト指向データモデルは、リレーショナルデータモデルの制限の多くを克服し、マルチメディアデータベースで人気があります。
ディメンションデータモデリング
最新のエンタープライズコンピューティングは、データウェアハウステクノロジーを利用して、分析用に大量のデータを保存します。ディメンションデータモデリングプロジェクトを利用して、データウェアハウスからの高速データストレージと取得を行うことができます。ディメンションモデルは、複製または冗長データを利用し、データストレージに利用するスペースを少なくするよりもパフォーマンスを優先します。
例えば、ディメンションデータモデルでは、自動車ディーラーには Car、Showroom、Time などのディメンションがあります。Car のディメンションには名前やブランドなどの属性がありますが、Showroom のディメンションには州、都市、通りの名前、ショールームの名前などの階層があります。
データモデリングプロセスとは何ですか?
データモデリングプロセスは、包括的なデータモデルを作成するまで繰り返し実行する必要がある一連の手順に従います。どのような組織であっても、さまざまなステークホルダーが集まって完全なデータビューを作成します。手順はデータモデリングの種類によって異なりますが、一般的な概要を次に示します。
ステップ 1: エンティティとそのプロパティを特定する
データモデル内のすべてのエンティティを特定します。各エンティティは、他のすべてのエンティティと論理的に区別されている必要があり、人、場所、物、概念、またはイベントを表すことができます。各エンティティは、1 つ以上の固有のプロパティを持っているため、他と区別できます。データモデルでは、エンティティを名詞、属性を形容詞と考えることができます。
ステップ 2: エンティティ間の関係を特定する
さまざまなエンティティ間の関係は、データモデリングの中心です。ビジネスルールは、最初にこれらの関係を概念レベルで定義します。データモデルでは、関係を動詞と考えることができます。例えば、営業担当者が多くの車を販売したり、ショールームで多くの営業担当者を雇用したりします。
ステップ 3: データモデリング手法を特定する
エンティティとその関係を概念的に理解した後、ユースケースに最適なデータモデリング手法を決定できます。例えば、構造化データにはリレーショナルデータモデリングを使用し、非構造化データにはディメンションデータモデリングを使用することが考えられます。
ステップ 4: 最適化して反復する
テクノロジーとパフォーマンスの要件に合わせて、データモデルをさらに最適化できます。例えば、Amazon Aurora と構造化クエリ言語 (SQL) を利用する場合は、エンティティを直接テーブルに配置し、外部キーを利用して関係を指定します。対照的に、Amazon DynamoDB を利用する場合は、テーブルをモデル化する前にアクセスパターンについて検討する必要があります。DynamoDB は速度を優先するため、最初にデータにアクセスする方法を決定してから、アクセスされる形式でデータをモデル化します。
テクノロジーと要件が時間の経過とともに変化するにつれて、通常、これらの手順を繰り返し再検討することになります。
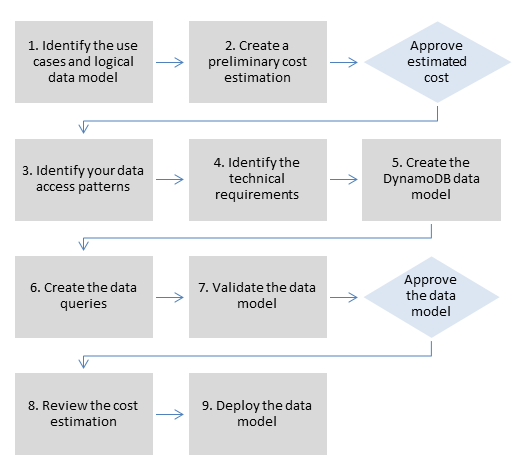
AWS はデータモデリングをどのようにサポートできますか?
より高速で簡単なデータモデリングのために AWS Amplify DataStore を利用して、モバイルおよびウェブアプリケーションを構築することもできます。関係を使用してデータモデルを定義するための視覚的なコードベースのインターフェイスがあります。これにより、アプリケーション開発が加速します。
今すぐ無料のアカウントを作成して、AWS でのデータモデリングを開始しましょう。