Bases de conhecimento do Amazon Bedrock
Com as Bases de Conhecimento para Amazon Bedrock, você pode oferecer aos modelos de base e aos atendentes informações contextualizadas retiradas das fontes de dados privadas da empresa, para fornecer respostas mais relevantes, precisas e personalizadas
Suporte totalmente gerenciado para fluxo de trabalho RAG de ponta a ponta
Para equipar os modelos de base (FMs) com informações atualizadas e exclusivas, as organizações usam a geração aumentada de recuperação (RAG), uma técnica que busca dados de fontes de dados da empresa e enriquece a solicitação para fornecer respostas mais relevantes e precisas. As Bases de Conhecimento para Amazon Bedrock são uma funcionalidade totalmente gerenciada, com gerenciamento de contexto de sessão integrado e atribuição de fonte, que auxilia na implementação de todo o fluxo de trabalho de RAG, desde a ingestão até a recuperação e o aumento de prompts, sem a necessidade de desenvolver integrações personalizadas com fontes de dados e gerenciar fluxos de dados. Além disso, é possível fazer perguntas e resumir informações de um único documento, sem a necessidade de configurar um banco de dados de vetores. Se seus dados contiverem fontes estruturadas, as Bases de conhecimento do Amazon Bedrock fornecem uma linguagem natural gerenciada integrada à solução de linguagem de consulta estruturada para gerar um comando de consulta para recuperar os dados, sem precisar movê-los para outra loja.

Conecte FMs e atendentes às fontes de dados com segurança
Caso tenha fontes de dados não estruturadas, as Bases de Conhecimento para Amazon Bedrock buscam automaticamente dados de fontes como Amazon Simple Storage Service (Amazon S3), Confluence (versão prévia), Salesforce (versão prévia), SharePoint (versão prévia) ou Web Crawler (versão prévia). Além disso, receba ingestão programática de documentos para permitir que os clientes ingiram dados de streaming ou dados de fontes incompatíveis. Depois que o conteúdo é ingerido, as Bases de Conhecimento para Amazon Bedrock o dividem em blocos de texto, converte o texto em incorporações e as armazena no seu banco de dados de vetores. Você pode escolher entre vários armazenamentos vetoriais compatíveis, incluindo Amazon Aurora, Amazon Opensearch Sem Servidor, Amazon Neptune Analytics, MongoDB, Pinecone e Redis Enterprise Cloud. Você também pode optar por se conectar a um índice de pesquisa híbrido Amazon Kendra para recuperação gerenciada
Usando as Bases de Conhecimento da Amazon Bedrock, você também pode se conectar aos seus armazenamentos de dados estruturados para gerar respostas fundamentadas. Isso pode ser especialmente útil quando você tem material de origem, como detalhes transacionais, que são armazenados em data warehouses e datalakes. As Bases de Conhecimento da Amazon Bedrock usam linguagem natural para SQL para converter consultas em comandos SQL e executar os comandos para recuperar os dados, sem precisar movê-los da fonte de dados de origem.

Personalize o Amazon Bedrock Knowledge Bases para fornecer respostas precisas em runtime
Com as Bases de Conhecimento Amazon Bedrock como sua solução RAG totalmente gerenciada, você tem a flexibilidade de personalizar e melhorar a precisão da recuperação. Para fontes de dados não estruturadas contendo dados multimodais, como imagens e documentos visualmente ricos com layouts complexos (por exemplo, documentos contendo tabelas, figuras, gráficos e diagramas), você pode configurar as Bases de Conhecimento Bedrock para parear, analisar e extrair insights significativos. Você pode escolher a Automação de Dados Bedrock ou modelos básicos como o pareador. Isso permite o processamento contínuo de dados multimodais complexos, permitindo que você crie aplicativos GenAI altamente precisos.
As Bases de Conhecimento Amazon Bedrock oferecem uma variedade de opções avançadas de divisão de dados, incluindo fragmentação semântica, hierárquica e de tamanho fixo. Para obter controle total, você também pode gravar seu próprio código de fragmentação como uma função do Lambda e até mesmo utilizar componentes prontos para uso de estruturas como LangChain e LlamaIndex. Se você escolher o Amazon Neptune Analytics como um armazenamento vetorial, as Bases de Conhecimento Amazon Bedrock criarão automaticamente incorporações e gráficos que vinculam conteúdo relacionado às suas fontes de dados. As Bases de Conhecimento Bedrock aproveitam essas relações de conteúdo com o GraphRag para melhorar a precisão da recuperação, permitindo respostas mais abrangentes, relevantes e explicáveis aos usuários finais.

Recuperar dados e aumentar prompts
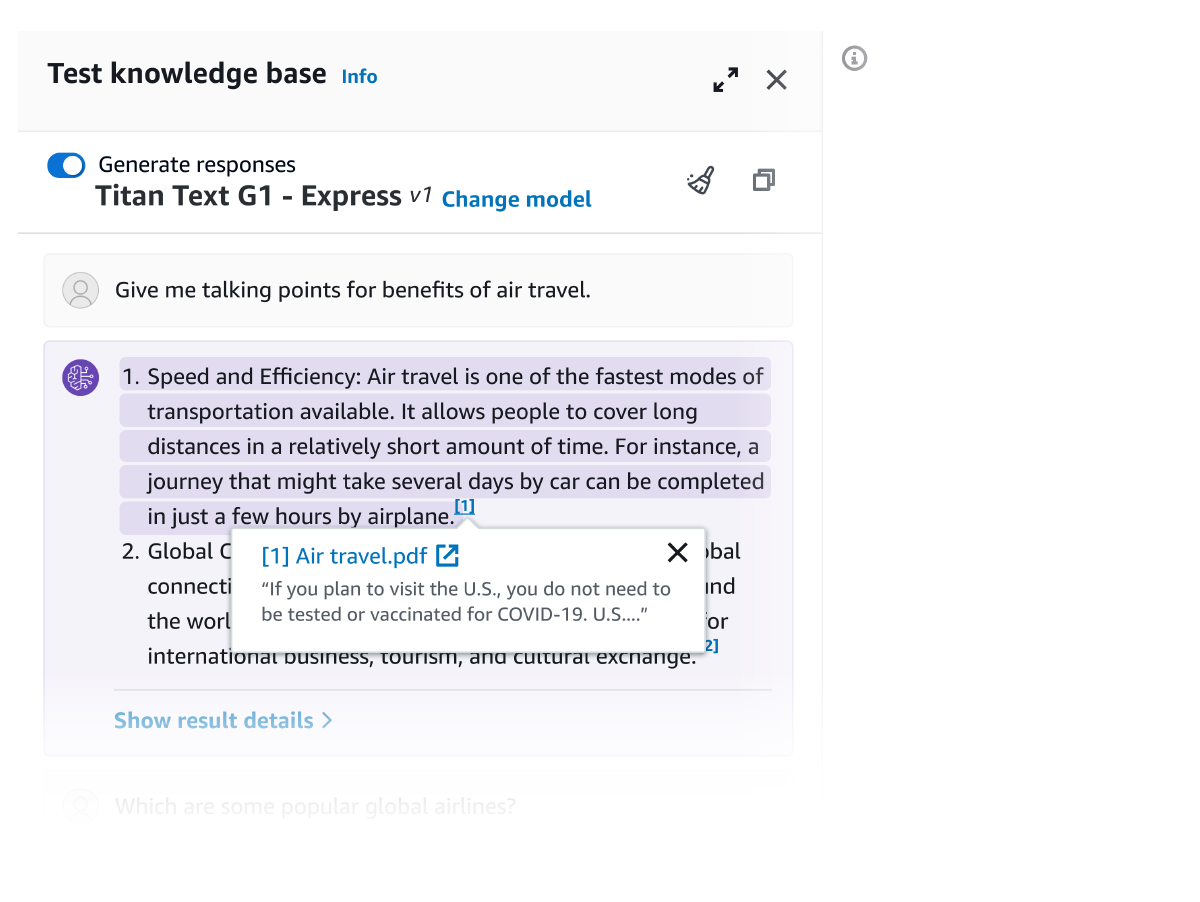
Usando a API Retrieve, você pode buscar resultados relevantes para uma consulta de usuário nas bases de conhecimento, incluindo elementos visuais, como imagens, diagramas, gráficos e tabelas, ou dados estruturados de bancos de dados, quando aplicável. A API RetrieveAndGenerate vai um passo além ao usar diretamente os resultados recuperados para aumentar o prompt do FM e retornar a resposta. Você também pode adicionar Bases de Conhecimento para Amazon Bedrock a Agentes para Amazon Bedrock e fornecer informações contextuais a atendentes. É também possível optar por fornecer filtros ou usar FM para gerar filtros implícitos para restringir os resultados retornados somente ao conteúdo relevante. As Bases de Conhecimento para Amazon Bedrock oferecem modelos de reclassificação para melhorar a relevância dos blocos de documentos recuperados.

Forneça atribuição de fonte
Todas as informações recuperadas das Bases de Conhecimento do Amazon Bedrock são fornecidas com citações (que também incluem informações visuais) para melhorar a transparência e minimizar as alucinações.
Você encontrou o que estava procurando hoje?
Informe-nos para que possamos melhorar a qualidade do conteúdo em nossas páginas.