Casos de uso do AWS Step Functions
O que você pode automatizar com o AWS Step Functions? Obtenha algumas ideias de alguns dos casos de uso mais populares abaixo.
O AWS Step Functions permite implementar um processo de negócios como uma série de etapas que compõem um fluxo de trabalho.
As etapas individuais no fluxo de trabalho poderão invocar uma função do Lambda ou um contêiner que tenha alguma lógica de negócios, atualizar um banco de dados como o DynamoDB ou publicar uma mensagem em uma fila assim que essa etapa ou a execução de todo o fluxo de trabalho for concluída.
O AWS Step Functions tem duas opções de fluxo de trabalho: Standard e Express. Quando se espera que seu processo de negócios leve mais de cinco minutos para uma única execução, você deve escolher Standard. Alguns exemplos de fluxo de trabalho em execução longa são um pipeline de orquestração de ETL ou quando qualquer etapa do fluxo de trabalho aguarda a resposta de uma pessoa para passar para a próxima etapa.
A opção Express é adequada para fluxos de trabalho que levam menos de cinco minutos e são ideais quando você precisa de alto volume de execução, ou seja, 100 mil invocações por segundo. Você pode usar as opções Standard ou Express distintamente ou combiná-las de forma que um fluxo de trabalho Standard mais longo acione vários fluxos de trabalho Express mais curtos que são executados em paralelo.
Orquestração de microsserviços
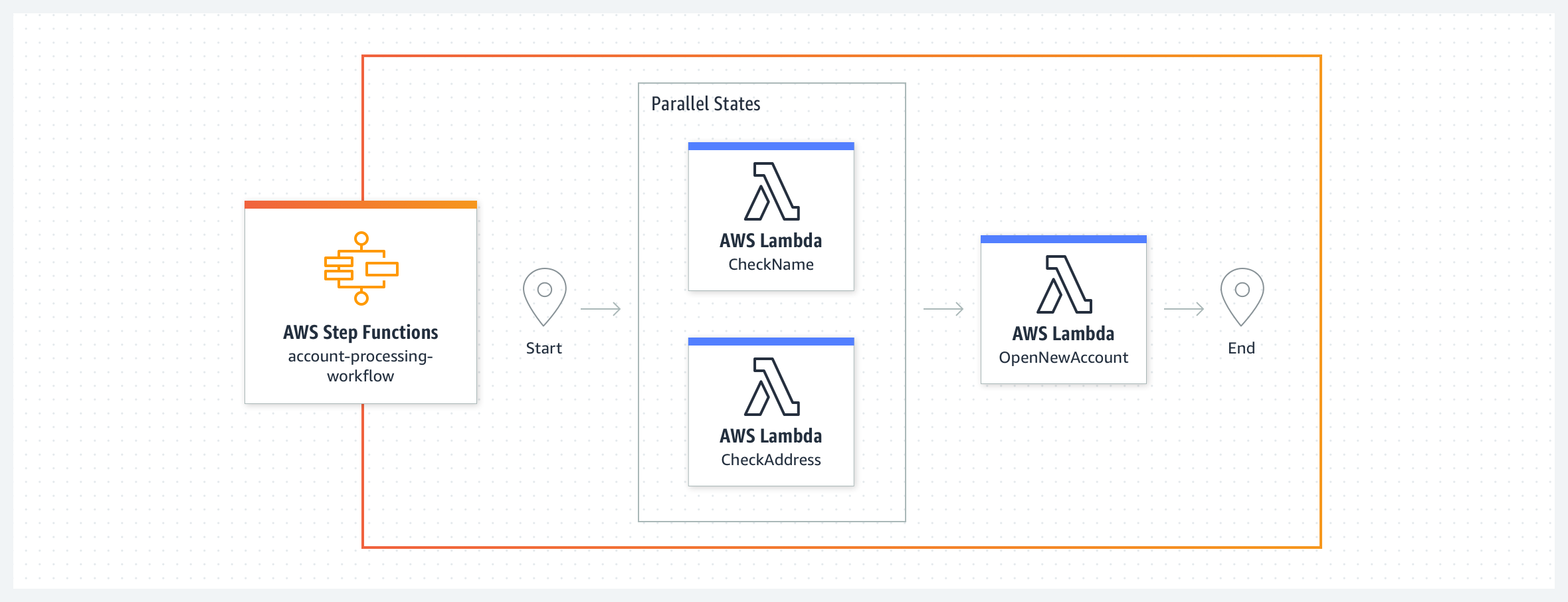
Combine funções do Lambda para criar uma aplicação baseada na Web
Neste exemplo de sistema bancário simples, uma nova conta bancária é criada após a validação do nome e endereço do cliente. O fluxo de trabalho começa com duas funções do Lambda, CheckName e CheckAddress, sendo executadas em paralelo como estados de tarefa. Quando ambas estiverem concluídas, o fluxo de trabalho executará a função do Lambda ApproveApplication. Você pode definir cláusulas de repetição e captura para tratar erros de estados de tarefas. Você pode usar erros de sistema predefinidos ou tratar erros personalizados gerados por essas funções do Lambda em seu fluxo de trabalho. Como o código do fluxo de trabalho assume o tratamento de erros, as funções do Lambda podem se concentrar na lógica de negócios e ter menos código. Fluxos de trabalho Express seriam mais adequados para este exemplo, pois as funções do Lambda executam tarefas que juntas levam menos de cinco minutos, sem dependências externas.
Combine as funções do Lambda para criar uma aplicação baseado na Web, com aprovação de uma pessoa
Às vezes, você pode precisar de uma pessoa para revisar e aprovar ou rejeitar uma etapa do processo de negócios para que o fluxo de trabalho possa passar para a próxima etapa. Recomendamos o uso de fluxos de trabalho Standard quando seu fluxo de trabalho precisar aguardar uma pessoa ou processos nos quais um sistema externo poderá levar mais de cinco minutos para responder. Aqui, estendemos o novo processo de abertura de conta com uma etapa de aprovação de notificação intermediária. O fluxo de trabalho começa com os estados de tarefa CheckName e CheckAddress sendo executados em paralelo. O próximo estado ReviewRequired é um estado de escolha que tem dois caminhos possíveis, enviar um e-mail de notificação do SNS ao aprovador na tarefa NotifyApprover ou passar para o estado ApproveApplication. O estado da tarefa NotifyApprover envia um e-mail ao aprovador e aguarda uma resposta antes de passar para o próximo estado de escolha “Aprovado”. Com base na decisão do aprovador, a aplicação de conta é Aprovada ou Rejeitada por meio das funções do Lambda.

Invoque um processo de negócios em resposta a um evento usando fluxo de trabalho do tipo Express
Neste exemplo, um evento em um barramento do Eventbridge personalizado atende a uma regra e invoca um fluxo de trabalho do Step Functions como destino. Suponha que você tenha uma aplicação de atendimento ao cliente que precise tratar de assinaturas expiradas de clientes. Uma regra do EventBridge atende a eventos expirados de assinatura e invoca um fluxo de trabalho de destino em resposta. O fluxo de trabalho de assinatura expirada desabilitará todos os recursos que a assinatura expirada possui sem excluí-los e enviará um e-mail ao cliente para notificá-lo sobre a assinatura expirada. Essas duas ações podem ser executadas em paralelo usando as funções do Lambda. Ao final do fluxo de trabalho, um novo evento é enviado ao barramento de eventos por meio de uma função do Lambda indicando que a expiração da assinatura foi processada. Para este exemplo, recomendamos o uso de fluxos de trabalho Express. À medida que sua empresa cresce e você começa a colocar mais eventos no barramento de eventos, a capacidade de invocar 100 mil execuções de fluxo de trabalho por segundo com fluxos de trabalho Express é muito grande. Veja o exemplo em ação com este repositório do Github.

Segurança e automação de TI
Orquestre uma resposta a incidentes de segurança para a criação de políticas do IAM
Você pode usar o AWS Step Functions para criar um fluxo de trabalho automatizado de resposta a incidentes de segurança que inclua uma etapa de aprovação manual. Neste exemplo, um fluxo de trabalho do Step Functions é acionado quando uma política do IAM é criada. O fluxo de trabalho compara a ação de política com uma lista personalizável de ações restritas. O fluxo de trabalho reverte a política temporariamente, notifica um administrador e espera que ele aprove ou negue. Você pode estender esse fluxo de trabalho para corrigir automaticamente, como aplicar ações alternativas ou restringir ações a ARNs específicos. Veja este exemplo em ação aqui.

Responda a eventos operacionais em sua conta da AWS
Você pode reduzir a sobrecarga operacional de manter sua infraestrutura de Nuvem AWS automatizando como você responde a eventos operacionais para seus recursos da AWS. O Amazon EventBridge fornece um fluxo quase em tempo real de eventos do sistema que descrevem a maioria das alterações e notificações para seus recursos da AWS. Com base nesse fluxo, você pode criar regras para rotear eventos específicos para o AWS Step Functions, o AWS Lambda e outros serviços da AWS para processamento posterior e ações automatizadas. Neste exemplo, um fluxo de trabalho do AWS Step Functions é acionado com base em um evento proveniente do AWS Health. A AWS monitora proativamente sites populares de repositório de código para chaves de acesso do IAM que foram expostas publicamente. Vamos supor que uma chave de acesso do IAM tenha sido exposta no GitHub. O AWS Health gera um evento AWS_RISK_CREDENTIALS_EXPOSED na conta da AWS relacionada à chave exposta. Uma regra configurada do Amazon Eventbridge detecta esse evento e invoca um fluxo de trabalho do Step Functions. Com a ajuda das funções do AWS Lambda, o fluxo de trabalho exclui a chave de acesso do IAM exposta, resume a atividade recente da API para a chave exposta e envia a mensagem de resumo a um tópico do Amazon SNS para notificar os assinantes, nessa ordem. Veja este exemplo em ação aqui.

Sincronize dados entre os buckets do S3 de origem e destino
Você pode usar o Amazon S3 para hospedar um site estático e o Amazon CloudFront para distribuir o conteúdo em todo o mundo. Como proprietário de um site, você pode precisar de dois buckets do S3 para fazer upload do conteúdo do site: um para preparação e teste e outro para produção. Você deseja atualizar o bucket de produção com todas as alterações do bucket de preparação, sem precisar criar um novo bucket do zero toda vez que atualizar seu site. Neste exemplo, o fluxo de trabalho do Step Functions executa tarefas em dois loops paralelos e independentes: um loop copia todos os objetos do bucket de origem para o bucket de destino, mas deixa de fora os objetos já presentes no bucket de destino. O segundo loop exclui todos os objetos no bucket de destino não encontrados no bucket de origem. Um conjunto de funções do AWS Lambda executa as etapas individuais: validar a entrada, obter as listas de objetos dos buckets de origem e destino e copiar ou excluir objetos em lotes. Veja este exemplo junto com seu respectivo código em detalhes aqui. Saiba mais sobre como criar ramificações paralelas de execução em sua máquina de estado aqui.

Processamento de dados e orquestração de ETL
Crie um pipeline de processamento para dados de streaming
Neste exemplo, a Freebird criou um pipeline de processamento de dados para processar dados de webhook de várias origens em tempo real e executar funções do Lambda que modificam os dados. Nesse caso de uso, os dados de webhook de várias aplicações de terceiros são enviados por meio do Amazon API Gateway para um fluxo de dados do Amazon Kinesis. Uma função do AWS Lambda extrai dados desse fluxo do Kinesis e aciona um fluxo de trabalho Express. Esse fluxo de trabalho passa por uma série de etapas para validar, processar e normalizar esses dados. No final, uma função do Lambda atualiza o tópico do SNS que aciona mensagens para funções de downstream do Lambda para as próximas etapas por meio de uma fila do SQS. Você pode ter até 100 mil invocações desse fluxo de trabalho por segundo para dimensionar o pipeline de processamento de dados.

Automatize as etapas de um processo de ETL
Você pode usar o Step Functions para orquestrar todas as etapas de um processo de ETL, com diferentes fontes e destinos de dados.
Neste exemplo, o fluxo de trabalho de ETL do Step Functions atualiza o Amazon Redshift sempre que novos dados estão disponíveis no bucket do S3 de origem. A máquina de estado do Step Functions inicia um trabalho do AWS Batch e monitora seu status quanto à conclusão ou aos erros. O trabalho do AWS Batch busca o script .sql do fluxo de trabalho de ETL na origem, ou seja, o Amazon S3, e atualiza o destino, ou seja, o Amazon Redshift por meio de um contêiner PL/SQL. O arquivo .sql contém o código SQL para cada etapa da transformação de dados. Você pode acionar o fluxo de trabalho de ETL com um evento do EventBridge ou manualmente por meio da AWS CLI ou usando AWS SDKs ou até mesmo um script de automação personalizado. Você pode alertar um administrador por meio do SNS que aciona um e-mail sobre falhas em qualquer etapa do fluxo de trabalho ou no final da execução do fluxo de trabalho. Este fluxo de trabalho de ETL é um exemplo em que você pode usar fluxos de trabalho Standard. Veja este exemplo em detalhes aqui. Você pode aprender mais sobre como enviar um trabalho do AWS Batch por meio de um exemplo de projeto aqui.

Execute um pipeline de ETL com vários trabalhos em paralelo
As operações Extrair, Carregar e Transformar (ETL) transformam dados brutos em conjuntos de dados úteis, transformando dados em insights acionáveis.
Você pode usar o Step Functions para executar vários trabalhos de ETL em paralelo, em que seus conjuntos de dados de origem podem estar disponíveis em momentos diferentes, e cada trabalho de ETL é acionado somente quando seu conjunto de dados correspondente fica disponível. Esses trabalhos de ETL podem ser gerenciados por diferentes serviços da AWS, como o AWS Glue, Amazon EMR, Amazon Athena ou outros serviços que não sejam da AWS.
Neste exemplo, você tem dois trabalhos de ETL separados em execução no AWS Glue que processam um conjunto de dados de vendas e um conjunto de dados de marketing. Depois que ambos os conjuntos de dados são processados, um terceiro trabalho de ETL combina a saída dos trabalhos de ETL anteriores para produzir um conjunto de dados combinado. O fluxo de trabalho do Step Functions aguarda até que os dados estejam disponíveis no S3. Enquanto o fluxo de trabalho principal é iniciado em uma programação, um manipulador de eventos do EventBridge é configurado em um bucket do Amazon S3, de modo que, quando os arquivos do conjunto de dados de vendas ou marketing forem transferidos por upload para o bucket, a máquina de estado possa acionar o trabalho de ETL “ProcessSales Data” ou “ProcessMarketingData”, dependendo de qual conjunto de dados ficou disponível.
Veja esta arquitetura em detalhes aqui para configurar a arquitetura de orquestração de ETL em sua conta da AWS. Saiba como gerenciar um trabalho do AWS Batch no Step Functions aqui.

Processamento de dados em grande escala
Você pode usar o Step Functions para iterar dezenas de milhões de itens em um conjunto de dados, como uma matriz JSON, uma lista de objetos no S3 ou um arquivo CSV em um bucket do S3. Você pode então processar os dados em paralelo com alta simultaneidade.
Neste exemplo, o fluxo de trabalho do Step Functions usa um estado de mapa no modo Distribuído para processar uma lista de objetos do S3 em um bucket do S3. O Step Functions itera na lista de objetos e, em seguida, inicia milhares de fluxos de trabalho paralelos, executados simultaneamente, para processar os itens. Você pode usar serviços de computação, como o Lambda, para obter ajuda com a escrita de código em qualquer idioma compatível. Você também pode escolher entre mais de 220 serviços da AWS criados com o propósito específico de incluir no fluxo de trabalho do estado de mapa. Após a conclusão das execuções dos fluxos de trabalho filhos, o Step Functions pode exportar os resultados para um bucket do S3, disponibilizando-os para revisão ou processamento posterior.

Operações de machine learning
Execute um trabalho de ETL e crie, treine e implante um modelo de machine learning
Neste exemplo, um fluxo de trabalho do Step Functions é executado em uma programação acionada pelo EventBridge para ser executada uma vez por dia. O fluxo de trabalho começa verificando se novos dados estão disponíveis no S3. Em seguida, ele executa um trabalho de ETL para transformar os dados. Depois disso, ele treina e implanta um modelo de machine learning nesses dados com o uso de funções do Lambda que acionam um trabalho do SageMaker e aguardam a conclusão antes que o fluxo de trabalho passe para a próxima etapa. Por fim, o fluxo de trabalho aciona uma função do Lambda para gerar previsões que são salvas no S3. Siga o processo passo a passo para criar este fluxo de trabalho aqui.

Automatize um fluxo de trabalho de machine learning usando o AWS Step Functions Data Science SDK
O AWS Step Functions Data Science SDK é uma biblioteca de código aberto que permite criar fluxos de trabalho que processam e publicam modelos de machine learning usando o Amazon SageMaker e o AWS Step Functions. O SDK fornece uma API Python que abrange todas as etapas de um pipeline de machine learning: treinar, ajustar, transformar, modelar e configurar endpoints. Você pode gerenciar e executar esses fluxos de trabalho diretamente em Python e em cadernos Jupyter. O exemplo abaixo ilustra as etapas de treinamento e transformação de um fluxo de trabalho de machine learning. A etapa de treinamento inicia um trabalho de treinamento do Sagemaker e envia os artefatos do modelo para o S3. A etapa de salvar modelo cria um modelo no SageMaker usando os artefatos de modelo do S3. A etapa de transformação inicia um trabalho de transformação do SageMaker. A etapa de configuração de criação de endpoint define uma configuração de endpoint no SageMaker. A etapa de criação de endpoint implanta o modelo treinado no endpoint configurado. Veja o caderno aqui.

Processamento de mídia
Extraia dados de PDF ou imagens para processamento
Neste exemplo, você aprenderá a combinar o AWS Step Functions, o AWS Lambda e o Amazon Textract para digitalizar uma fatura em PDF para extrair seu texto e dados para processar um pagamento. O Amazon Textract analisa o texto e os dados da fatura e aciona um fluxo de trabalho do Step Functions por meio do SNS, do SQS e do Lambda para cada conclusão de trabalho bem-sucedida. O fluxo de trabalho começa com uma função do Lambda salvando os resultados de uma análise de fatura bem-sucedida no S3. Isso aciona outra função do Lambda que processa o documento analisado para ver se um pagamento pode ser processado para essa fatura e atualiza as informações no DynamoDB. Se a fatura puder ser processada, o fluxo de trabalho verificará se a fatura foi aprovada para pagamento. Caso contrário, ele notificará um revisor por meio do SNS para aprovar manualmente a fatura. Se for aprovada, uma função do Lambda arquivará a fatura processada e encerrará o fluxo de trabalho. Veja este exemplo junto com seu respectivo código em detalhes aqui.

Divida e transcodifique vídeos usando paralelização em massa
Neste exemplo, a Thomson Reuters criou uma solução de transcodificação de vídeo dividida e com tecnologia sem servidor usando o AWS Step Functions e o AWS Lambda. Eles precisavam transcodificar cerca de 350 videoclipes de notícias por dia em 14 formatos para cada videoclipe, o mais rápido possível. A arquitetura usa o FFmpeg, um codificador de áudio e vídeo de código aberto que processa apenas um arquivo de mídia em série. A fim de melhorar o throughput para fornecer a melhor experiência ao cliente, a solução foi usar o AWS Step Functions e o Amazon S3 para processar elementos em paralelo. Cada vídeo é dividido em segmentos de três segundos, processados em paralelo e reunidos no final.
A primeira etapa é uma função do Lambda chamada Locate keyframes que identifica as informações necessárias para fragmentar o vídeo. A função Split video do Lambda divide o vídeo com base nos quadros-chave e armazena os segmentos em um bucket do S3. Cada segmento é então processado em paralelo pelas funções do Lambda e colocado em um bucket de destino. A máquina de estado segue o processamento até que todos os N segmentos sejam processados. Em seguida, ela aciona uma função do Lambda final que concatena os segmentos processados e armazena o vídeo resultante em um bucket do S3.
Crie um pipeline de transcodificação de vídeo com tecnologia sem servidor usando o Amazon MediaConvert
Neste exemplo, aprenderemos como o AWS Step Functions, AWS Lambda e AWS Elemental MediaConvert podem ser orquestrados em conjunto para capacidades de transcodificação totalmente gerenciadas para conteúdo sob demanda. Esse caso de uso se aplica a empresas com alto volume ou volumes variados de conteúdo de vídeo de origem que desejam processar conteúdo de vídeo na nuvem ou mover workloads para a nuvem no futuro.
A solução de vídeo sob demanda tem três subfluxos de trabalho acionados de um fluxo de trabalho principal do Step Functions:
- Ingestão: pode ser um fluxo de trabalho Express. Um arquivo de origem descartado no S3 aciona esse fluxo de trabalho para ingerir dados.
- Processamento: esse fluxo de trabalho analisa a altura e a largura do vídeo e cria um perfil de codificação. Após o processamento, um trabalho de codificação é acionado por meio do AWS Elemental MediaConvert.
- Publicação: a etapa final verifica se os ativos estão disponíveis nos buckets do S3 de destino e notifica o administrador de que o trabalho foi concluído.

Comece a usar o AWS Step Functions