Amazon SageMaker Çıkarımı nedir?
Amazon SageMaker AI, her türlü kullanım örneği için en iyi fiyat performansıyla çıkarım taleplerinde bulunmak üzere, altyapı modelleri (FM'ler) de dahil makine öğrenimi modellerini dağıtmayı kolaylaştırır. Düşük gecikme süresi ve yüksek aktarım hızından uzun süreli çıkarımlara kadar tüm çıkarım ihtiyaçlarınız için SageMaker AI'ı kullanabilirsiniz. SageMaker AI tam olarak yönetilen bir hizmettir ve MLOps araçlarıyla entegre olur. Böylece model dağıtımınızı ölçeklendirebilir, çıkarım maliyetini azaltabilir, modelleri üretimde daha etkili bir şekilde yönetebilir ve operasyonel yükü azaltabilirsiniz.
SageMaker Inference’ın Avantajları
Geniş çıkarım seçenekleri yelpazesi
Gerçek Zamanlı Çıkarım
Sunucusuz Çıkarım
Eşzamansız Çıkarım
Toplu Dönüşüm
Ölçeklenebilir ve uygun maliyetli çıkarım seçenekleri
Tek modelli uç noktalar
Düşük gecikme süresi ve yüksek aktarım hızı için tahsis edilmiş bulut sunucularında veya sunucusuz olarak barındırılan bir container üzerinde çalışan model.
Tek bir uç noktada birden fazla model
Temeldeki hızlandırıcıları daha iyi kullanmak için aynı bulut sunucusunda birden fazla model barındırın ve dağıtım maliyetlerini %50'ye kadar azaltın. Her FM için ölçeklendirme politikalarını ayrı ayrı kontrol edebilir, böylece altyapı maliyetlerini optimize ederken model kullanım şekillerine uyum sağlamayı kolaylaştırabilirsiniz.
Seri çıkarım işlem hatları
Tahsis edilmiş bulut sunucularını paylaşan ve belirli bir sırayla yürüten birden fazla container. Ön işleme, tahminler ve işleme sonrası veri bilimi görevlerini birleştirmek için bir çıkarım işlem hattı kullanabilirsiniz.
Çoğu makine öğrenimi çerçevesi ve model sunucusu için destek
Amazon SageMaker çıkarımı; TensorFlow, PyTorch, ONNX ve XGBoost gibi en yaygın makine öğrenimi çerçevelerinden bazıları için yerleşik algoritmaları ve önceden oluşturulmuş Docker görüntülerini destekler. Önceden oluşturulmuş Docker görüntülerinden hiçbiri ihtiyaçlarınızı karşılamıyorsa CPU destekli çoklu model uç noktalarıyla kullanmak üzere kendi container'ınızı oluşturabilirsiniz. SageMaker çıkarımı; TensorFlow Serving, TorchServe, NVIDIA Triton, AWS çoklu model sunucusu gibi en popüler model sunucularını destekler.
Amazon SageMaker Yapay Zeka, altyapı modellerinin performansını artırmanıza yardımcı olmak üzere model paralelliği ve büyük model çıkarımı (LMI) için özel derin öğrenme container'ları (DLC'ler), kitaplıklar ve araçlar sunar. Bu seçeneklerle, altyapı modelleri (FM) dahil modelleri hemen hemen her kullanım örneği için hızlı bir şekilde dağıtabilirsiniz.



Düşük maliyetle yüksek çıkarım performansı elde edin
Düşük maliyetle yüksek çıkarım performansı elde edin
Amazon SageMaker AI'ın yeni çıkarım optimizasyonu araç seti; Llama 3, Mistral ve Mixtral modelleri gibi üretken yapay zeka modellerinde maliyetleri ~%50'ye kadar düşürürken ~2 kata kadar daha yüksek aktarım hızı sağlar. Örneğin bir Llama 3-70B modeliyle, herhangi bir optimizasyon yapmadan xml.p5.48xlarge bulut sunucusunda önceki ~1200 belirteç/saniye yerine ~2400 belirteç/saniye elde edebilirsiniz. Sadece birkaç tıklamayla Kurgusal Kod Çözme, Niceleme ve Derleme gibi bir model optimizasyonu tekniği seçebilir veya birkaç tekniği birleştirebilir, modellerinize uygulayabilir, bu tekniklerin çıktı kalitesi ve çıkarım performansı üzerindeki etkisini değerlendirmek için karşılaştırma çalıştırabilir ve modelleri dağıtabilirsiniz.
Modelleri en yüksek performanslı altyapıda dağıtın veya sunucusuz hale getirin
Amazon SageMaker AI; AWS Inferentia tabanlı Amazon EC2 Inf1 bulut sunucuları, AWS tarafından tasarlanıp üretilen yüksek performanslı ML çıkarım çipleri ve Amazon EC2 G4dn gibi GPU bulut sunucuları da dahil olmak üzere çeşitli düzeylerde işlem veya belleğe sahip 70'ten fazla bulut sunucusu türü sunar. Dilerseniz uç nokta başına binlerce modele, saniyede milyonlarca işlem (TPS) aktarım hızına ve 10 milisaniyenin altındaki ek yük gecikmelerine kolayca ölçeklendirmek için Amazon SageMaker Sunucusuz Çıkarım'ı seçin.

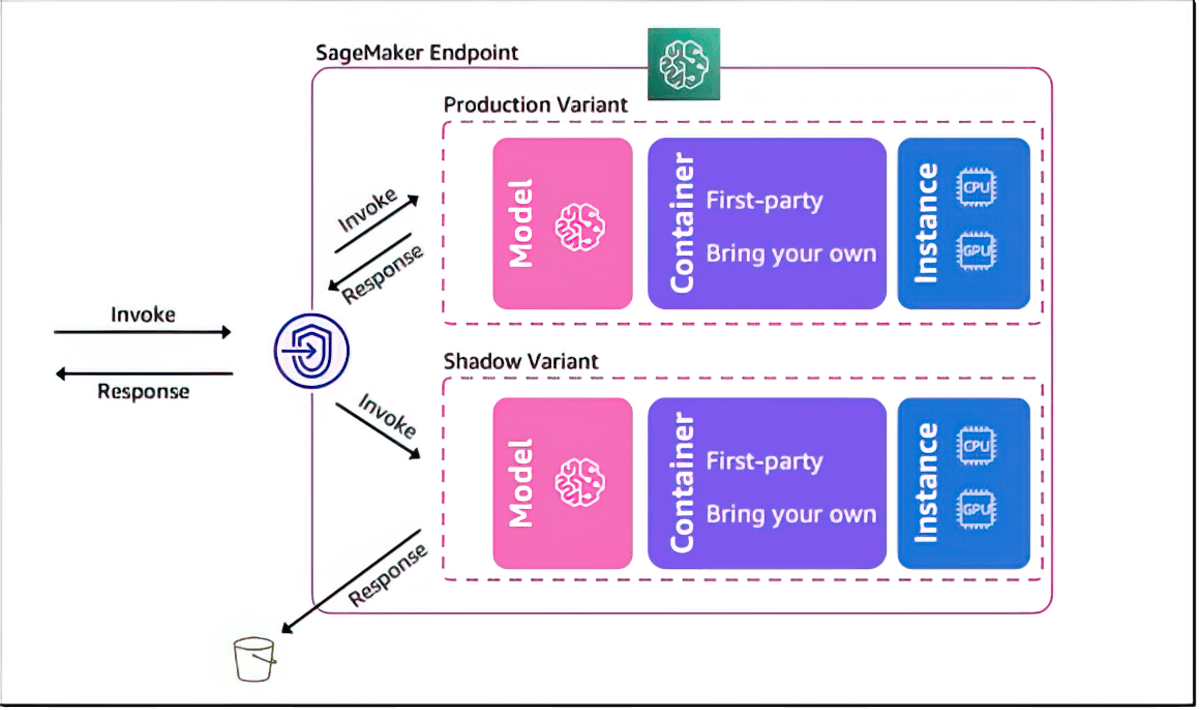
ML modellerinin performansını doğrulamak için gölge testi
Amazon SageMaker AI, canlı çıkarım talepleri kullanarak yeni bir modelin performansını mevcut durumda SageMaker dağıtımı yapılan modele karşı gölge testiyle değerlendirmenize yardımcı olur. Gölge testi, potansiyel yapılandırma hatalarını ve performans sorunlarını son kullanıcıları etkilemeden önce yakalamanıza yardımcı olabilir. SageMaker AI sayesinde kendi gölge testi altyapınızı oluşturmak için haftalarca zaman harcamanıza gerek kalmaz. Sadece test etmek istediğiniz üretim modelini seçersiniz ve SageMaker AI gölge modunda otomatik olarak yeni modelin dağıtımını yaparak üretim modeli tarafından alınan çıkarım isteklerinin bir kopyasını yeni modele gerçek zamanlı bir şekilde yönlendirir.
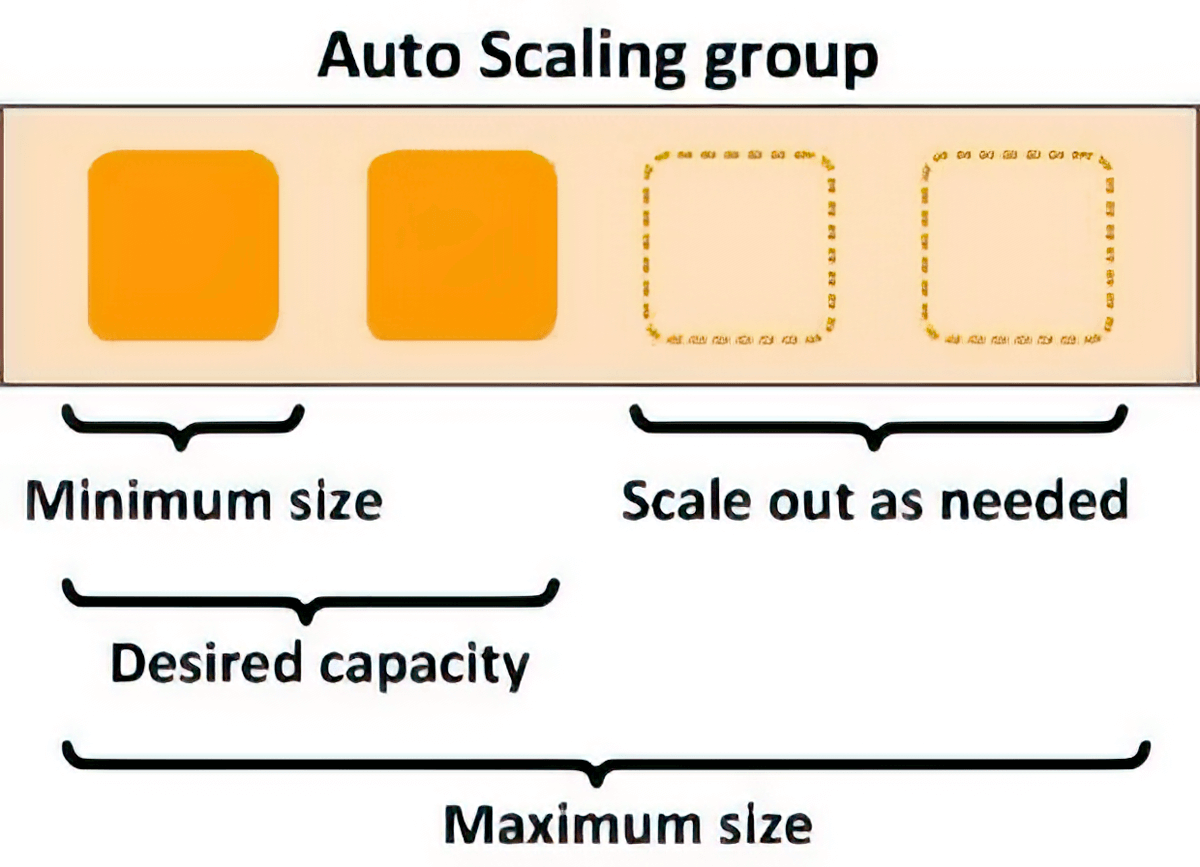
Esneklik için otomatik ölçekleme
Çıkarım taleplerindeki dalgalanmaları karşılamak üzere temel işlem kaynaklarını otomatik olarak ölçeklendirmek için ölçeklendirme politikalarını kullanabilirsiniz. Model kullanımındaki değişiklikleri kolayca ele almak ve aynı zamanda altyapı maliyetlerini optimize etmek üzere her ML modeli için ölçeklendirme politikalarını ayrı ayrı kontrol edebilirsiniz.
Gecikme iyileştirme ve Akıllı yönlendirme
Yeni çıkarım taleplerini halihazırda çıkarım talebi sunmakla meşgul olan bulut sunucularına rastgele yönlendirmek yerine, kullanılabilir bulut sunucularına akıllıca yönlendirerek ML modelleri için çıkarım gecikmesini azaltabilir ve ortalama olarak %20 daha düşük çıkarım gecikmesi elde edebilirsiniz.
Operasyonel yükü azaltın ve değer elde etme süresini hızlandırın
Tam olarak yönetilen model barındırma ve yönetimi
Tam olarak yönetilen bir hizmet olan Amazon SageMaker AI; bulut sunucularının kurulumu, yönetimi, yazılım sürümü uyumlulukları ve düzeltme eki sürümleriyle ilgilenir. Ayrıca uyarıları izleyip almakta kullanabileceğiniz uç noktalar için yerleşik ölçüm ve günlükler sağlar.
MLOps özelliklerine sahip yerleşik entegrasyon
Amazon SageMaker AI model dağıtım özellikleri; SageMaker İşlem Hatları (iş akışı otomasyonu ve düzenlemesi), SageMaker Projeleri (ML için CI/CD), SageMaker Özellik Deposu (özellik yönetimi), SageMaker Model Kayıt Defteri (kökeni izlemek ve otomatik onay iş akışlarını desteklemek için model ve yapıt kataloğu), SageMaker Clarify (sapma algılama) ve SageMaker Model İzleyici (model ve kavram sapması algılama) dahil olmak üzere MLOps yetenekleriyle yerel olarak entegre edilmiştir. Sonuç olarak ister tek bir modelle ister on binlercesiyle dağıtım gerçekleştiriyor olun SageMaker AI, ML modellerini dağıtma, ölçeklendirme ve yönetmeye ilişkin operasyonel yükleri azaltmasının yanında bunları üretime daha hızlı bir şekilde alır.