



關聯式資料庫和非關聯式資料庫有何區別?
關聯式和非關聯式資料庫是應用程式資料儲存的兩種方法。關聯式資料庫 (或 SQL 資料庫) 會以包含資料列和資料欄的資料表格式存放資料。資料欄包含資料屬性,而資料列則包含資料值。您可以連結關聯式資料庫中的資料表,以深入了解不同資料點之間的互連情況。另一方面,非關聯式資料庫 (或 NoSQL 資料庫) 會使用各種資料模型來存取和管理資料。這些資料庫會透過放寬傳統關聯式資料庫的一些資料一致性限制,特別針對需要大量資料、低延遲和彈性資料模型的應用程式進行優化。
關聯式資料庫如何存放資料?
關聯式資料庫將資料存放在包含資料欄和資料列的資料表中。每個資料欄表示一個特定的資料屬性,而每個資料列表示該資料的一個執行個體。
您可以為每個資料表提供主索引鍵,也就是可唯一識別資料表的識別碼欄。您可以使用主索引鍵來建立資料表之間的關係。您可以使用其來將資料表之間的列關聯為另一個資料表中的外部索引鍵。
連接兩個資料表後,您可以透過單一查詢從這兩個資料表中擷取資料。您撰寫 SQL 查詢,以與關聯式資料庫互動。
存放資料的範例
例如,假設一個零售商建立了一個包含所有產品的資料表。在此資料表中,您可以包含產品名稱、描述和價格的資料欄。另一個資料表包含有關客戶、他們的姓名以及他們所購買內容的資料。
下表顯示了這種方法。
| Product_id (主索引鍵) |
Product_name |
Product_cost |
| P1 |
Product_A |
100 USD |
| P2 |
Product_B |
50 USD |
| P3 |
Product_C |
80 USD |
| Customer_id |
Customer_name |
Item_purchased (外部索引鍵) |
| C1 |
Customer_A |
P2 |
| C2 |
Customer_B |
P1 |
| C3 |
Customer_C |
P3 |
非關聯式資料庫如何存放資料?
由於管理和儲存無結構描述資料的方式多種多樣,因此有幾種不同的非關聯式資料庫系統。無結構描述資料是存放的不含關聯式資料庫所需條件約束的資料。
接下來,我們將解釋說明一些常見的非關聯式資料庫類型。
鍵值資料庫
鍵值資料庫可將資料存放為鍵值對的集合。在鍵值對中,該鍵可作為唯一識別碼。鍵和值不限種類,從簡單物件到複雜的複合物件皆可。
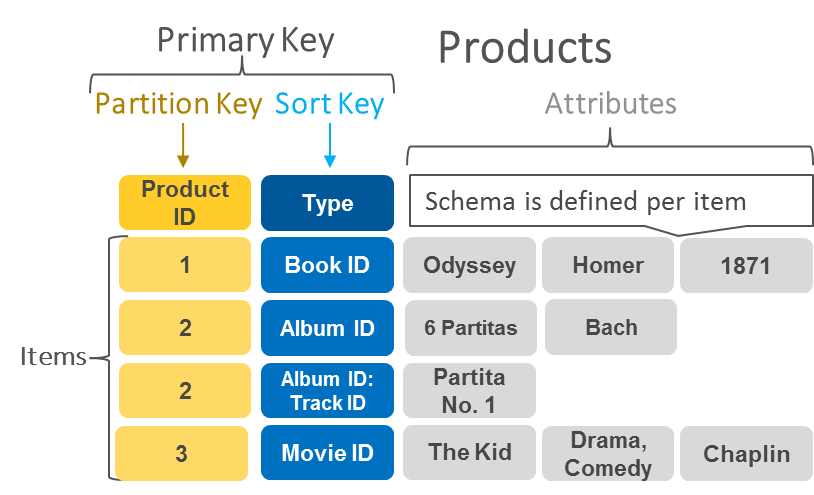
文件資料庫
文件導向資料庫使用的文件模型格式與開發人員在其應用程式碼中使用的相同。其將資料存放為本質上靈活、半結構化和分層化的 JSON 物件。
下列範例顯示了文件資料庫中存放的資料是什麼樣子的。
| { company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
圖形資料庫
圖形資料庫專門用於存放和導覽關係。其使用節點來存放資料實體,並利用邊緣來存放各實體間的關係。
邊緣一律具有起始節點、結束節點、類型和方向。例如,可以描述父子關係、動作和所有權。

主要差異:關聯式與非關聯式資料庫
關聯式和非關聯式資料庫存放和管理資料的方式完全不同。下列各節將討論特定差異。
結構
關聯式資料庫以表格格式存放資料,並遵循有關資料變化和資料表關係的嚴格規則。其可讓您處理結構化資料的複雜查詢,同時維護資料完整性和一致性。
對於需求不斷變化的資料,非關聯式資料庫更具彈性和實用性。您可以使用其來存放影像、影片、文件和其他半結構化和非結構化內容。
資料完整性機制
不可部分完成性、一致性、隔離性和耐久性 (ACID) 是指資料庫在資料處理出現錯誤或中斷時維護資料完整性的能力。
關聯式資料庫模型遵循嚴格的 ACID 屬性。這意味著一組後續操作將始終一起完成。如果單次操作失敗,則整組操作都會失敗。這可保證始終保持資料準確性。
相比之下,非關聯式資料庫提供了更靈活的基本可用、軟狀態和最終一致性 (BASE) 模型。
非關聯式資料庫可保證可用性,但不保證立即一致性。資料庫狀態可能會隨著時間而變更,並最終實現一致性。某些非關聯式資料庫可能會提供效能或其他權衡取捨方面的 ACID 合規性。
效能
關聯式資料庫的效能取決於其磁碟子系統。若要提升資料庫效能,您可以使用 SSD,並使用獨立磁碟備援陣列 (RAID) 來最佳化磁碟。若要取得最佳效能,您還必須最佳化索引、資料表結構和查詢。
相比之下,NoSQL 資料庫的效能視網路延遲、硬體叢集大小和呼叫應用程式而定。有幾種方法可以改善非關聯式資料庫的效能:
- 增加叢集大小
- 將網路延遲降至最低
- 索引和快取
與關聯式資料庫相比,NoSQL 資料庫可為特定使用案例提供更高的效能和可擴展性。
擴展
關聯式資料庫系統的嚴格的結構描述可能會帶來大規模挑戰。您通常可向伺服器新增更多 CPU 或 RAM 資源,以垂直擴展。您也可以透過跨伺服器複製唯讀工作負載的資料,實現水平擴展。但是,水平擴展讀寫工作負載需要特殊策略,例如分區和碎片化。
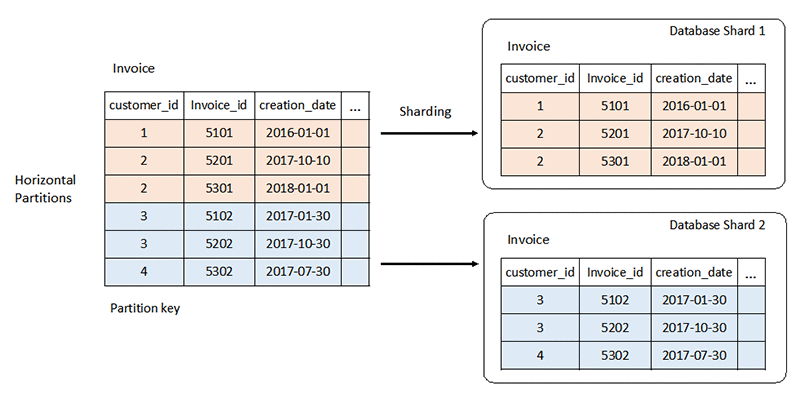
相比之下,NoSQL 資料庫具有高度可擴展性。您可以更輕鬆地將其工作負載分配到多個節點上。這些資料庫處理大量資料的方式是,將其分區為較小的集合並跨多個節點分配集合。

何時使用關聯式與非關聯式資料庫
如果您的資料在大小、結構和存取頻率方面具有可預測性,則關聯式資料庫是最佳選擇。如果實體之間的關係非常重要,則您也可能更偏好關聯式資料庫管理系統。例如,如果您有一個具有複雜結構和關係的大型資料集,則您希望這些關係在分析和易用性方面脫穎而出。
相比之下,非關聯式模型更適合存放形狀或大小靈活或未來可能變更的資料。
此外,在某些情況下,資料關係不適合表格式主索引鍵和外部索引鍵格式。例如,要在社交媒體網路中對朋友和關係進行建模,您需要在關聯式資料庫中包含數百列的資料表。
相比之下,這可以在非關聯式資料庫中以單一命令列表示。下列範例顯示非關聯式資料庫中具有四個朋友之成員的資料項目。
| Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{member name: “member 1” member friends: “member 2, member 3, member 4, member 5”} |
差異摘要:關聯式與非關聯式資料庫
| 類別 |
關聯式資料庫 |
非關聯式資料庫 |
| 資料模型 |
表格式。 |
鍵值、文件或圖形。 |
| 資料類型 |
結構化。 |
結構化、半結構化和非結構化。 |
| 資料完整性 |
ACID 合規性高且完整。 |
最終一致性模式。 |
| 效能 |
透過向伺服器新增更多資源來進行提升。 |
透過新增更多伺服器節點來進行提升。 |
| 擴展 |
水平擴展需要額外的資料管理策略。 |
水平擴展非常簡單。 |
AWS 如何支援您的關聯式和非關聯式資料庫需求?
Amazon Web Services (AWS) 針對關聯式和非關聯式資料庫需求提供多項服務。
適用於關聯式資料庫的 AWS 服務
Amazon Relational Database Service (Amazon RDS) 是受管服務的集合,方便在雲端設定、操作和擴展關聯式資料庫。雲端資料庫提供許多優勢,例如效能、規模和成本效益。您可以使用如下關聯式資料庫引擎:
- Amazon RDS for SQL Server,可部署多個版本的 SQL Server (2014、2016、2017 和 2019)
- Amazon RDS for MySQL,可支援 MySQL Community Edition 5.7 版和 8.0 版
- Amazon RDS for MariaDB,可支援 MariaDB Server 10.3、10.4、10.5 和 10.6 版
此外,Amazon RDS for Oracle 有兩種不同的授權模式,這表示如果您沒有授權,也無需單獨購買 Oracle 授權。
適用於非關聯式資料庫的 AWS 服務
AWS 還提供多種 NoSQL 資料庫服務,可滿足您的所有 NoSQL 需求。以下是一些範例:
- Amazon DynamoDB 是一種鍵值資料庫服務,對於任何規模的工作負載均可提供一致且低於 10 毫秒的延遲。
- Amazon DocumentDB (with MondoDB compatibility) 是廣受歡迎的文件導向資料庫,具有強大的直覺式 API,可實現彈性的反覆開發。
- Amazon MemoryDB 是一項耐用的記憶體資料庫服務。其能夠提供微秒級讀取和寫入延遲,從而實現超快效能。
- Amazon Neptune 是全受管圖形資料庫服務,可建置及執行高效能圖形應用程式。
- Amazon OpenSearch Service 專門用於提供機器產生之資料的近乎即時的視覺化和分析。
立即建立帳戶,開始在 AWS 上使用關聯式和非關聯式資料庫。