概觀
要完成的內容
在本指南中,您將:
- 對資料進行視覺化和分析,以理解重要的關係
- 套用轉換,以清理資料並產生新的特徵
- 自動為可重複的資料準備工作流程產生筆記本
先決條件
在開始本教學之前,您需要具備:
- AWS 帳戶:如果您還沒有,請按照設定您的 AWS 環境快速入門指南進行操作。
AWS 經驗
初階
完成時間
30 分鐘
完成成本
請參閱 Amazon SageMaker 定價以估算本教學的成本。
要求
您必須登入 AWS 帳戶。
使用的服務
Amazon SageMaker Data Wrangler
上次更新日期
2022 年 7 月 1 日
實作
步驟 1:設定 Amazon SageMaker Studio 網域
藉助 Amazon SageMaker,您可以使用主控台視覺化地部署模型,也可以使用 SageMaker Studio 或 SageMaker 筆記本以程式設計方式部署模型。在本教學中,您將使用 SageMaker Studio 筆記本以程式設計的方式部署模型,而該筆記本需要一個 SageMaker Studio 網域。
每個 AWS 帳戶在每個區域只能擁有一個 SageMaker Studio 網域。如果您在美國東部 (維吉尼亞北部) 區域已有 SageMaker Studio 網域,請按照 SageMaker Studio 設定指南將所需的 AWS IAM 政策連接到您的 SageMaker Studio 帳戶,然後略過步驟 1,並直接進行步驟 2。
如果您沒有現有的 SageMaker Studio 網域,請繼續進行步驟 1 以執行 AWS CloudFormation 範本,該範本將建立 SageMaker Studio 網域,並新增本教學其餘部分所需的許可。
選擇 AWS CloudFormation 堆疊連結。此連結將開啟 AWS CloudFormation 主控台,並建立您的 SageMaker Studio 網域和名為 studio-user 的使用者。它還會向您的 SageMaker Studio 帳戶新增所需的許可。在 CloudFormation 主控台中,確認右上角顯示的 Region (區域) 是 US East (N. Virginia) (美國東部 (維吉尼亞北部))。 Stack name (堆疊名稱) 應為 CFN-SM-IM-Lambda-catalog,且不應變更。 此堆疊大約需要 10 分鐘來建立所有資源。
此堆疊假定您已經在您的帳戶中設定了公有 VPC。如果您沒有公有 VPC,請參閱具有單一公有子網路的 VPC,了解如何建立公有 VPC。

選取 I acknowledge that AWS CloudFormation might create IAM resources (我認知 AWS CloudFormation 可能會建立 IAM 資源),然後選擇 Create stack (建立堆疊)。

在 CloudFormation 窗格中,選擇 Stacks (堆疊)。建立此堆疊約需要 10 分鐘。建立該堆疊後,堆疊狀態從 CREATE_IN_PROGRESS 變更為 CREATE_COMPLETE。

步驟 2:建立新的 SageMaker Data Wrangler 流程
SageMaker Data Wrangler 接受來自各種來源的資料,包括來自 Amazon S3、Amazon Athena、Amazon Redshift、Snowflake 和 Databricks 的資料。在此步驟中,您將使用儲存在 Amazon S3 的 UCI 德國信用風險資料集來建立新的 SageMaker Data Wrangler 流程。此資料集包含有關個人的人口統計和財務資訊,以及表示個人信用風險水平的標籤。
在管理主控台搜尋列中輸入 SageMaker Studio,然後選擇 SageMaker Studio。

從 SageMaker 主控台右上角的 Region (區域) 下拉式清單中選擇 US East (N. Virginia) (美國東部 (維吉尼亞北部))。對於 Launch app (啟動應用程式),選取 Studio 以開啟 SageMaker Studio 並使用 studio-user 設定檔。

開啟 SageMaker Studio 介面。在導覽列上,選擇 File (檔案)、New (新增)、Data Wrangler Flow (Data Wrangler 流程)。

在 Import (匯入) 標籤的 Import data (匯入資料) 下方,選擇 Amazon S3。
在 S3 URI path (S3 URI 路徑) 欄位中,輸入 s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv,然後選擇 Go (前往)。在 Object name (物件名稱) 下方,按一下 german_credit_data.csv,然後選擇 Import (匯入)。

步驟 3:分析資料
在此步驟中,您將使用 SageMaker Data Wrangler 評估訓練資料集的品質。 您可以使用快速模型功能來大致預估預測的品質,以及資料集中特徵的預測能力。
在 Data Flow (資料流程) 標籤的資料流程圖表中,選擇 + 圖示,然後選擇 Add analysis (新增分析)。
在 Create analysis (建立分析) 窗格下方,為 Analysis type (分析類型) 選取 Histogram (長條圖)。
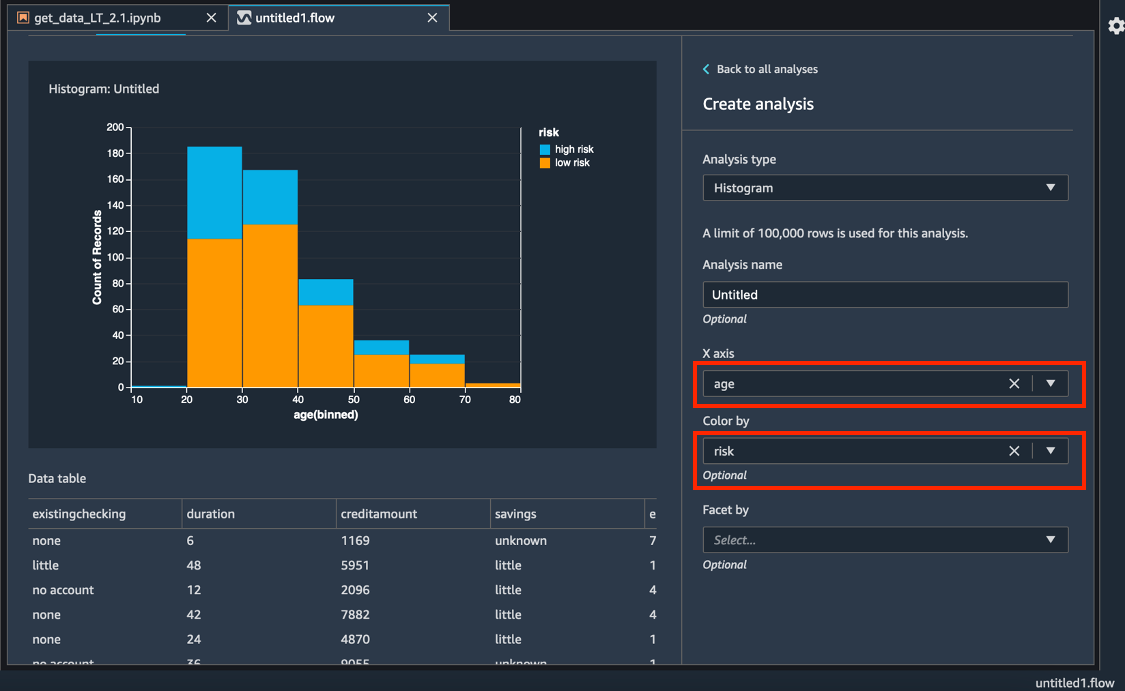
對於 X axis (X 軸),選取 age (年齡)。
對於 Color by (顏色依據),選取 risk (風險)。
選擇 Preview (預覽),以產生 credit risk (信用風險) 欄位的長條圖,該圖依據 age (年齡) 段塗色。
選擇 Save (儲存) 以便將此分析儲存到流程中。
若要了解該資料集有多適合用於訓練預測 risk (風險) 目標變數的模型,請執行 Quick Model (快速模型) 分析。在 Analysis (分析) 標籤中,選擇 Create new analysis (建立新的分析)。
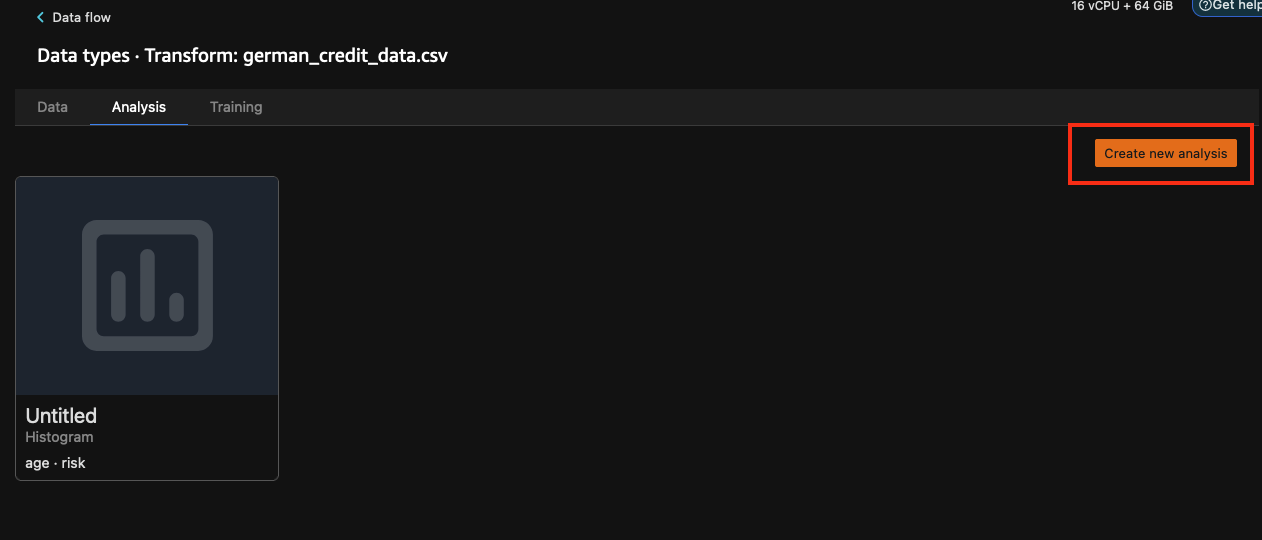
在 Create analysis (建立分析) 窗格的下方,為 Analysis type (分析類型) 選擇 Quick Model (快速模型)。對於 Label (標籤),選取 risk (風險),然後選擇 Preview (預覽)。 Quick Model (快速模型) 窗格將顯示所用模型以及一些基本統計資料的簡要概覽 (包括 F1 分數和特徵重要性等),以協助您評估資料集的品質。選擇 Save (儲存)。
步驟 4:新增轉換到資料流程
SageMaker Data Wrangler 透過提供視覺化介面來簡化資料處理,您可以使用該介面新增各種預建置的轉換。您還可以使用 SageMaker Data Wrangler 編寫自訂轉換。 在此步驟中,您將使用視覺化編輯器壓平合併複雜的字串資料、編碼類別、重新命名欄,以及刪除不必要的欄。 然後,您要將 status_sex 欄拆分成兩個新的欄:marital_status 和 sex。
若要導覽到資料流程圖表,請選擇 Data flow (資料流程)。

在資料流程圖表中,選擇 + 圖示,然後選擇 Add transform (新增轉換)。

在 ALL STEPS (所有步驟) 窗格下方,選擇 Add step (新增步驟)。

在 ADD TRANSFORM (新增轉換) 清單中,選擇 Search and edit (搜尋並編輯),它是用於操作字串資料的轉換。

在 SEARCH AND EDIT (搜尋並編輯) 窗格下方,為 Transform (轉換) 選取 Split string by delimiter (以分隔符號拆分字串)。 對於 Input columns (輸入欄),選取 status_sex。 在 Delimiter (分隔符號) 方塊中,輸入符號 :。 在 Output column (輸出欄) 中,輸入 vec。選擇 Preview (預覽),然後選擇 Add (新增)。
此轉換會拆分 status_sex 欄,在 DataFrame 的末尾建立名為 vec 的新欄。status_sex 欄包含以冒號分隔的字串,而新的 vec 欄則包含以逗號分隔的向量。

若要拆分 vec 欄並建立兩個新欄 sex_split_0 和 sex_split_1:
在 ALL STEPS (所有步驟) 下方,選擇 + Add step (+ 新增步驟)。
在 ADD TRANSFORM (新增轉換) 清單中,選擇 Manage vectors (管理向量)。
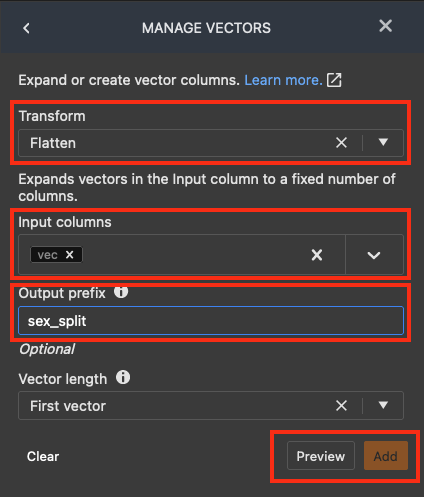
在 MANAGE VECTORS (管理向量) 窗格下方,為 Transform (轉換) 選取 Flatten (壓平合併)。 對於 Input columns (輸入欄),選取 vec。對於 output_prefix,輸入 sex_split。
選擇 Preview (預覽),然後選擇 Add (新增)。
若要重新命名由拆分轉換建立的欄:
在 ALL STEPS (所有步驟) 窗格下方,選擇 + Add step (+ 新增步驟)。
在 ADD TRANSFORM (新增轉換) 清單中,選擇 Manage columns (管理欄)。
在 MANAGE COLUMNS (管理欄) 窗格下方,為 Transform (轉換) 選取 Rename column (重新命名欄)。對於 Input column (輸入欄),選取 sex_split_0。 在 New name (新名稱) 框中,輸入 sex。
選擇 Preview (預覽),然後選擇 Add (新增)。
重複此程序,將 sex_split_1 重新命名為 marital_status。

步驟 5:新增類別編碼
在此步驟中,您將建立建模目標,並對類別變數進行編碼。類別編碼會將字串資料類型類別轉換為數字標籤。這是一項常見的預處理任務,因為數字標籤可被用於許多模型類型。
在該資料集中,信用風險分類以字串 high risk (高風險) 和 low risk (低風險) 表示。在此步驟中,您要將此分類轉換為二進位表示,即 0 或 1。
在 ALL STEPS (所有步驟) 窗格下方,選擇 + Add Step (+ 新增步驟)。在 ADD TRANSFORM (新增轉換) 清單中,選擇 Encode categorical (編碼類別)。SageMaker Data Wrangler 提供三種轉換類型:循序編碼、獨熱編碼和相似度編碼。在 ENCODE CATEGORICAL (編碼類別) 窗格下方,為 Transform (轉換) 保留預設的 Ordinal encode (循序編碼)。 對於 Input columns (輸入欄),選取 risk。 在 Output column (輸出欄) 中,輸入 target。 本教學將忽略 Invalid handling strategy (無效處理策略) 方塊。 選擇 Preview (預覽),然後選擇 Add (新增)。

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

使用 Encode categorical (編碼類別) 轉換對其餘欄 (housing、job、sex 和 marital_status) 進行編碼,方法如下:在 ALL STEPS (所有步驟) 下方,選擇 + Add Step (+ 新增步驟)。 在 ADD TRANSFORM (新增轉換) 清單中,選擇 Encode categorical (編碼類別)。在 ENCODE CATEGORICAL (編碼類別) 窗格下方,為 Transform (轉換) 保留預設的 Ordinal encode (循序編碼)。 對於 Input columns (輸入欄),選取 housing、job、sex 和 marital_status。Output column (輸出欄) 留空,從而讓編碼值會取代類別值。選擇 Preview (預覽),然後選擇 Add (新增)。

若要縮放數字欄 creditamount,對信用金額套用縮放器以便對此欄中的資料分佈進行標準化:在 ALL STEPS (所有步驟) 窗格下方,選擇 + Add Step (+ 新增步驟)。 在 ADD TRANSFORM (新增轉換) 清單中,選擇 Process numeric (處理數值)。對於 Scaler (縮放器),選取預設選項 Standard scaler (標準縮放器)。對於 Input columns (輸入欄),選取 creditamount。選擇 Preview (預覽),然後選擇 Add (新增)。


若要刪除完成轉換的原始欄:在 ALL STEPS (所有步驟) 窗格下方,選擇 + Add Step (+ 新增步驟)。在 ADD TRANSFORM (新增轉換) 清單中,選擇 Manage columns (管理欄)。在 MANAGE COLUMNS (管理欄) 窗格下方,為 Transform (轉換) 選取 Drop Column (刪除欄)。 對於 Columns to drop (要刪除的欄),選取 status_sex、existingchecking、employmentsince、risk 和 vec。選擇 Preview (預覽),然後選擇 Add (新增)。

步驟 6:執行資料偏差檢查
在此步驟中,您將使用 Amazon SageMaker Clarify 檢查資料偏差,更清楚地了解訓練資料和模型,以便識別和限制偏差,並解釋預測。
選擇左上角的 Data flow (資料流程) 以返回至資料流程圖表。選擇 + 圖示,然後選擇 Add analysis (新增分析)。在 Create analysis (建立分析) 窗格中,為 Analysis type (分析類型) 選取 Bias Report (偏差報告)。對於 Analysis name (分析名稱),輸入任何名稱。對於 Select the column your model predicts (target) (選取您的模型預測的欄 (目標)),選取 target (目標)。保持勾選 Value (值) 核取方塊。在 Predicted value (s) (預測值) 方塊中,輸入 1。對於 Select the column to analyze for bias (選取要進行偏差分析的欄),選取 sex。對於 Choose bias metrics (選擇偏差指標),保留預設的選擇。選擇 Check for bias (檢查偏差)。
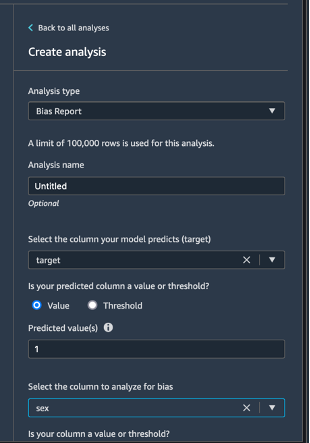
幾秒後,SageMaker Clarify 會產生一份報告,顯示目標和測試欄在一些偏差相關指標上的分數,其中包括類不平衡 (CI)和標籤中正比例的差異 (DPL)。在此例中,資料在 sex 方面有些許偏差 (-0.38),在 labels 方面的偏差較小 (0.075)。根據此報告,您可能需要考慮偏差補救方法,例如使用 SageMaker Data Wrangler 的內建 SMOTE 轉換。在本教學中,我們將略過補救步驟。選擇 Save (儲存) 以便將偏差報告儲存到資料流程。

步驟 7:匯出資料流程
將資料流程匯出到 Jupyter 筆記本,以將這些步驟作為 SageMaker 處理任務執行。這些步驟會根據您定義的資料流程處理資料,並將輸出儲存到 Amazon S3 或 Amazon SageMaker Feature Store。
在資料流程圖表中,選擇 + 圖示、Export to (匯出到)、Amazon S3 (via Jupyter Notebook) (Amazon S3 (透過 Jupyter 筆記本))。這將會在 SageMaker Studio 中建立筆記本,您可以在其中執行產生的 SageMaker 處理任務,來建立經過轉換的資料集。 執行此筆記本,以將結果儲存到預設的 S3 儲存貯體。



步驟 8:清除資源
最佳實務是刪除不再使用的資源,以免產生意外費用。
若要刪除 S3 儲存貯體,請執行以下操作:
- 開啟 Amazon S3 主控台。在導覽列上,選擇 Buckets (儲存貯體)、sagemaker-<您的區域>-<您的帳戶 ID>,然後選取 data_wrangler_flows 旁邊的核取方塊。然後選擇 Delete (刪除)。
- 在 Delete objects (刪除物件) 對話方塊中,確認您已選取要刪除的物件,然後將 permanently delete (永久刪除) 輸入到 Permanently delete objects (永久刪除物件) 確認方塊。
- 當此操作完成且儲存貯體為空時,您可以透過再次執行相同程序來刪除儲存貯體 sagemaker-<您的區域>-<您的帳戶 ID>。

本教學中用於執行筆記本映像的資料科學核心將不斷產生費用,直到您停止核心或執行以下步驟刪除應用程式。 如需詳細資訊,請參閱《Amazon SageMaker 開發人員指南》中的關閉資源。
若要刪除 SageMaker Studio 應用程式,請執行以下操作:在 SageMaker Studio 主控台中,選擇 studio-user,然後透過選擇 Delete app (刪除應用程式程式) 來刪除 Apps (應用程式) 下列出的所有應用程式。等待片刻直到 Status (狀態) 變更為 Deleted (已刪除)。

如果您在步驟 1 中使用了現有的 SageMaker Studio 網域,請略過步驟 8 的其餘部分並直接進入「結論」部分。
如果您在步驟 1 中執行 CloudFormation 範本來建立新的 SageMaker Studio 網域,請繼續執行下列步驟以刪除由 CloudFormation 範本建立的網域、使用者和資源。
若要開啟 CloudFormation 主控台,請在 AWS Console 搜尋列中輸入 CloudFormation,然後從搜尋結果中選擇 CloudFormation。

在 CloudFormation 窗格中,選擇 Stacks (堆疊)。從狀態下拉式清單中,選取 Active (作用中)。在 Stack name (堆疊名稱) 下,選擇 CFN-SM-IM-Lambda-catalog 開啟堆疊詳細資訊頁面。

在 CFN-SM-IM-Lambda-catalog 堆疊詳細資訊頁面上,選擇 Delete (刪除) 以刪除在步驟 1 中建立的堆疊及資源。

結論
您成功地使用 Amazon SageMaker Data Wrangler 準備了用於訓練機器學習模型的資料。SageMaker Data Wrangler 提供 300 多種精選的預先設定資料轉換,例如欄類型轉換、獨熱編碼、使用均值或中值插補缺失資料、重新縮放欄和日期/時間內嵌,因此您可以將資料轉換為可有效用於模型的格式,而無需編寫任何程式碼。