



什麼是機器學習中的提升?
提升是一種用於機器學習的方法,可用來減少預測性資料分析的錯誤。資料科學家訓練機器學習軟體 (稱為機器學習模型),利用已標記資料來猜測未標記資料。單一機器學習模型可能會在預測時出現錯誤,是否會出錯取決於訓練資料集的準確度。舉例來說,假如有一個辨識貓咪的模型,僅受過辨識白貓咪影像的訓練,它偶爾可能會將黑貓誤認為白貓。提升嘗試透過依序訓練多種模型,改善整體系統的準確度以克服這個問題。
為什麼提升很重要?
提升可將多個弱學習程式轉換為單一強學習模型,進而提高機器模型的預測準確度和效能。機器學習模型可分為弱學習程式或強學習程式:
弱學習程式
弱學習程式的預測準確度較低,類似於隨機猜測。它們容易出現過度擬合,也就是說,它們無法對與其原始資料集差異太大的資料進行分類。例如,如果您訓練模型將貓咪辨識為尖耳動物,那麼它可能無法辨識卷耳貓咪。
強學習程式
強學習程式具有更高的預測準確度。提升可將弱學習程式系統轉換為單一強學習系統。例如,為了辨識貓咪影像,它結合了一個猜測尖耳的弱學習程式和另一個猜測貓形眼睛的學習程式。在分析完尖耳的動物影像後,系統會再次分析它的貓形眼睛。這樣一來,即可提高系統的整體準確度。
提升如何運作?
要了解提升如何運作,我們先來描述下機器學習模型做出決策的方式。儘管在實作時會出現諸多變化,但資料科學家經常會使用藉助決策樹演算法的提升:
決策樹
決策樹是機器學習中的資料結構,它會根據資料集的功能將資料集劃分為較小的子集。其想法是,決策樹重複分割資料,直到只剩下一個類別。例如,樹可能會提出一系列是非題,並在每一個步驟中將資料拆分為類別。
提升集合方法
提升透過將幾個弱決策樹依序進行組合,建立了一個集合模型。它可為個別樹的輸出指派權重。然後,它會為來自第一個決策樹的錯誤分類賦予更高的權重並輸入到下一個樹。經過多次循環後,提升方法會將這些弱規則組合成一個強大的預測規則。
提升與裝袋演算法相比
提升和裝袋演算法是提高預測準確度的兩種常見集合方法。這些學習方法之間的主要區別在於訓練方法。在裝袋演算法中,資料科學家透過在多個資料集上同時訓練其中的幾個來提高弱學習程式的準確度。相比之下,提升則是依次獨立訓練每個弱學習程式。
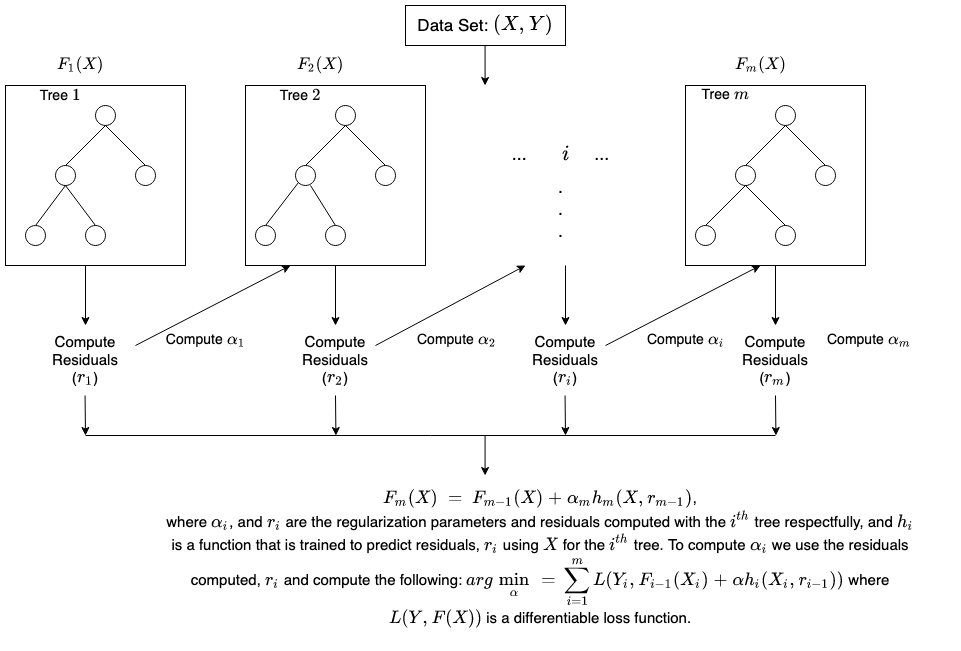
提升訓練是如何進行的?
訓練方法將因名為提升演算法的提升流程類型而異。但是,演算法會採用以下一般步驟來訓練提升模型:
步驟 1
提升演算法為每個資料範例指派相同的權重。它會將資料餽送給第一個機器模型,稱為基本演算法。基本演算法會對每個資料範例進行預測。
步驟 2
提升演算法評估模型預測,並增加具有更顯著錯誤的範例的權重。它還會根據模型效能來指派權重。可提供卓越預測的模型將對最終決策產生很大影響。
步驟 3
該演算法會將加權資料傳遞給下一個決策樹。
步驟 4
該演算法會重複步驟 2 和 3,直到訓練執行個體的錯誤率低於特定閾值。
AWS 如何在提升方面提供協助?
AWS 聯網服務目的在於為企業提供:
Amazon SageMaker
Amazon SageMaker 整合了專門為機器學習建置的一組廣泛功能。您可用它來快速準備、建置、訓練和部署高品質的機器學習模型。
Amazon SageMaker Canvas
Amazon SageMaker Canvas 能消除建置機器學習模型的繁瑣作業,協助您根據資料來自動建置和訓練模型。SageMaker Canvas 為您提供表格式資料集,並選擇目標欄進行預測,它可以是數值或類別。SageMaker Autopilot 會自動探索不同的解決方案,尋找最佳模型。接著,只要點選滑鼠一次,就能將模型直接部署至生產,或用 Amazon SageMaker Studio 反覆使用建議的解決方案,增進模型品質。
Amazon SageMaker 模型訓練
Amazon SageMaker 模型訓練透過即時捕捉訓練指標以及在偵測到錯誤時傳送提醒,可讓您輕鬆最佳化機器學習模型。這有助於您立即修復不準確的模型預測,例如對影像的錯誤識別。
Amazon SageMaker 可為訓練大型深度學習模型和資料集提供快速簡便的方法。SageMaker 分散式訓練程式庫可以更快地訓練大型資料集。
立即建立 AWS 帳戶,開始使用 Amazon SageMaker。