



什麼是認知搜尋?
認知搜尋是一種搜尋引擎技術,它使用人工智慧 (AI) 快速尋找各類查詢的相關和準確的搜尋結果。現代企業可在各種系統上存放大量資訊,例如手冊、常見問答集、研究報告、客戶服務指南和人力資源文件等。認知搜尋技術可掃描不同資訊的大型資料庫,並關聯資料以找到使用者問題的答案。例如,您可以提出「去年在機械維修上花了多少錢?」等問題 然後,認知搜尋會將問題映射到相關文件,並傳回特定的答案。
認知搜尋有哪些優點?
認知搜索具有許多有點,這使其成為有用的搜尋引擎技術。以下是認知搜尋的一些主要優點。
理解自然語言
認知搜尋服務無需使用者提供太多規範即可產生更精確的結果。該服務可以透過考慮多種來源並從結構化和非結構化資料中爬取來產生精確的搜尋結果。認知搜尋引擎技術在傳回結果時還可理解情境。該技術使用自然語言處理 (NLP) 來確定人類語言的情境、模式和含義。
提升工作效率
認知搜尋結合多個資料來源的資訊,並且產生全面的回應作為輸出。在傳統的關鍵字搜尋中,您必須在多個頁面中定位所有必需的資訊。然後,您自己閱讀、分析和總結資訊。
相比之下,可以使用綜合搜尋功能同時從多個文件中取得答案。可以更快地存取所需的資料。這就可以提高工作效率,簡化整個組織中與資料相關的業務流程。
個人化搜尋結果
認知搜尋使用機器學習 (ML),可以不斷為使用者個人化結果。機器學習不會持續輸出相同的資訊,而是收集所使用的資料和搜尋模式。透過記錄使用者在初始查詢後可能點按的結果,該技術可以改進並更快地產生高度相關的結果。 該技術會不斷變得更智慧、更精確、更有用。
認知搜尋有哪些使用案例?
認知搜尋使用自然語言處理和其他人工智慧技術來提供精確的搜尋。以下是認知搜尋使用的一些步驟。
資料擷取
認知搜尋首先需要資訊才能在其中進行搜尋。該技術可以從文件、網站、電子郵件、內部儲存庫、手冊以及您要使用的任何其他資訊中擷取資料。它使用光學字元辨識 (OCR)、實體識別和 NLP 技術等擷取技術從資源中擷取資訊。
擷取程序旨在使認知搜尋能夠理解資訊,類似於人類隨後將內容編目。
資料索引
擷取資料後,認知搜尋會針對您提供的所有已擷取資訊建立可搜尋的索引。除了使用關鍵字標記資料外,該技術還使用中繼資料、資料之間的關係和補充資訊來有效地對所有資訊進行分類。
當使用者搜尋內容時,認知搜尋會參考這些索引,以更快地找到相關資訊。
使用者輸入
當使用者將查詢寫入認知搜尋時,後者會使用自然語言處理來分解和理解他們提出的問題。在傳統的關鍵字搜尋中,搜尋引擎可以識別關鍵字並產生與該關鍵字一致的資料。
相比之下,認知搜尋嘗試瞭解查詢的完整上情境,以及個人使用者因素,例如他們的偏好設定。該技術結合了字符分析和語義分析等 NLP 技術,以了解使用者想要從搜尋中取得的結果。
搜尋和擷取
然後,認知搜尋使用使用者的查詢,掃描其資料索引,並在其儲存庫中查找相關資訊。該技術在索引中移動,尋找最近的鄰居,然後逐層篩選出結果。每個相關結果都被指派一個相關性分數。認知搜尋透過依據分數對結果進行排序來顯示最相關的資訊。
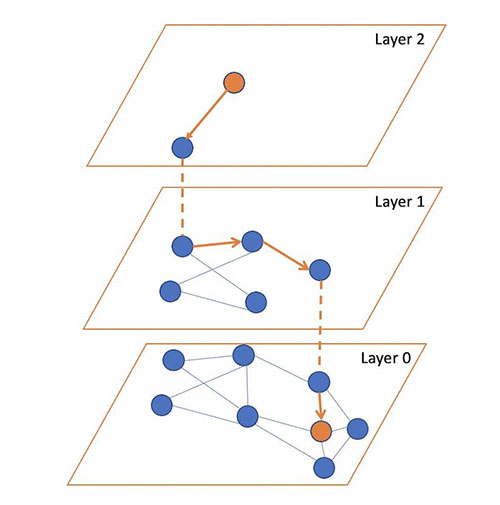
持續改善
使用者在使用認知搜尋時可以新增其他篩選條件或規範,以協助產生更具體的結果。認知搜尋依據以前的互動完善其查詢方法。
例如,認知搜尋會記錄使用者搜尋的內容及其搜尋查詢的順序。如果使用者通常在查詢後立即提出某個問題,認知搜尋也會主動包含有關後續問題的資訊。
認知搜尋還會隨時間推移更多地了解使用者搜尋查詢背後的情緒和意義。這可改進其對查詢的直接回應。
例如,當有人提出特定的問題時,認知搜尋會給出具體的答案。或者,使用者更籠統的問題會得到更長的答案。透過不斷記錄互動並從中學習,認知搜尋會變得更加精確,並且不斷提供更相關的資訊。
認知搜尋如何運作?
以下是一些使用認知搜尋可帶來益處的機會。
統一的搜尋體驗
可以使用認知搜尋打造統一的搜尋體驗。由於認知搜尋使用自然語言處理,因此可以透過從多個非結構化和結構化資料儲存庫中擷取資訊來取得高度詳細和準確的回應。通過利用多種來源和資料類型,可以更輕鬆地做出以資料為依據的決策。
例如,生物技術公司 Gilead Sciences, Inc. 使用 AWS 進行認知搜尋。公司使用該技術來組織結構化和非結構化資料。這些資訊來源於多達九個企業系統,而文件來源於知識程式庫。
認知搜尋大幅度減少了 Gilead 的手動資料管理任務。搜尋資訊所需的時間約為原來的 50%。這推動了極具價值的研究、實驗和藥物突破。
自助式機器人
可以在自助式機器人中使用認知搜尋解決方案,這有助於改善現場客戶支援。想要知道如何執行某個任務或函數的使用者可以輸入人類語言並獲得自訂的回應。認知搜尋透過從各種手冊、支援文件和資源中擷取資訊來支援知識發現。
例如,Citibot 使用 AWS 為市民及其地方和州政府提供通訊工具。它將聊天機器人技術與認知搜索相結合,以提高與選民互動的可擴展性和有效性。市民透過與聊天機器人互動,快速找到他們尋求的答案,這可將等待時間縮短高達 90%。
資料封存搜尋
許多組織都擁有歷史資料存放區,其中包含數百萬個文件、影像和轉錄的文字檔案。認知搜尋可以解鎖資料存放區中的資訊,並對其進行匯總以供分析和研究。
例如,The Wall Street Journal 使用 AWS 進行認知搜尋。認知搜尋有助於加速 Talk2020 的發展。Talk2020 是一款智慧搜尋工具,可幫助該出版物的讀者快速搜尋和分析 30 年來總統候選人發表的公開聲明。該技術透過探索語音模式和執行文字分析,可以更輕鬆地深入調查問題。
員工入職
認知搜尋可以協助員工完成任何需要執行的自助任務,例如入職或學習新技能。它充當面向員工的交叉參考。員工不必聯絡經理解釋如何做某事,而是可以詢問認知搜尋。這種用法有助於簡化自助服務任務並提高工作效率。
例如,Workgrid Software 使用 AWS 在員工體驗平台中提供軟體解決方案。這使員工的工作更加互聯互通、高效和富有成效。透過認知搜尋,員工可以查詢組織資料庫中的數位內容。這樣,他們可以找到工作時出現的任何問題的答案。
生成式 AI 如何改善認知搜尋?
生成式人工智慧 (生成式 AI) 是一種可以創造新內容和想法的人工智慧,包括創造對話、故事、影像、視訊和音樂。生成式 AI 有助於簡化認知搜尋,更妥善地了解使用者意圖並改進整體回應。接下來給出一些範例。
情境分析
許多生成式 AI 工具都使用基於轉換器的機器學習模型。這些模型具有用於分析文字資料以理解其含義的神經網路。
基於轉換器的 AI 模型對於自然語言處理和理解非常有用。透過考慮使用者、資料情境和使用者意圖,這些模型可以更充分地理解查詢背後的真正目的。借助改進的查詢理解,認知搜尋可以找到更精確的資訊以傳回給使用者。
結果總結
生成式 AI 可以將較大的文字總結成較小的區段。認知搜尋可以找到不同文件中語義上最相關的部分。然後,該技術可以使用生成式 AI 將這些部分組合起來,並準確返回使用者想要看到的內容。生成式 AI 還可以透過理解傳回的文字並消除任何冗餘內容來最大限度地提高結果的品質。
內容篩選
生成式 AI 可以按不同的參數篩選認知搜尋結果,包括使用者授權、查詢相關性和使用者偏好設定。產生結果文字時,它可以確保僅利用使用者有權存取的資源。結果仍然相關且有用,而不會影響安全性。
AWS 如何改善您的認知企業搜尋解決方案?
Amazon Web Services (AWS) 提供 Amazon Kendra 作為認知搜尋解決方案。
Amazon Kendra 是一項由機器學習提供支援的認知搜尋服務,其完全受管、高度準確且易於使用。開發人員可以使用該服務為應用程式新增搜尋功能。這意味著最終使用者可以發現儲存在公司內大量內容中的相關資訊。
以下是您可以透過 Amazon Kendra 獲益的方式:
- 在結構化和非結構化的內容儲存庫中取得統一的搜尋體驗
- 使用 ML 支援的工具提供查詢回應
- 採用全受管的答案排序功能,這些功能有助於提高答案的準確性
- 依據自己的特定標準以及其他屬性 (例如使用者行為和內容新鮮度) 微調回應
立即建立帳戶,開始在 AWS 上使用認知搜尋。