



什麼是資料標記?
在機器學習領域裡,資料標記是識別原始資料 (影像、文字檔案、影片等等) 並新增一或多個有意義與資訊性的標籤來提供內容的過程,讓機器學習模型可從中學習。舉例來說,標籤會顯示相片中是否有鳥或車子,指出一段錄音中會說出哪些字詞,或者一張 X 光片中是否有腫瘤。對於各種使用案例 (包含電腦視覺、自然語言處理和語音識別) 而言,必須提供資料標記。
資料標記如何運作?
如今,大多數實用的機器學習模型都使用監督式學習,該學習應用算法將一個輸入對應到一個輸出。為了讓監督式學習產生效果,您需要一組標籤資料集,讓模型可從中學習,以作出正確決策。資料標記通常從要求人類對給定一段未標記的資料做出判斷開始。例如,標籤人員可能會被要求標記資料集的所有圖像,其中「照片是否包含鳥」的答案為真。標記可像是/否一樣粗糙,也可精細如識別有關鳥類影像的特定像素。機器學習模型使用人為提供的標籤在稱為「模型訓練」的過程中學習基礎模式。 結果是一個經過訓練的模型,可用於對新資料進行預測。
在機器學習,您用作為訓練和評估給定模型的目標標準的正確標記資料集通常被稱為「基本真相」。 訓練模型的準確性將取決於您的基礎真實的準確性,因此花費時間和資源來確保高度準確的資料標記極為重要。
一些常見資料標記類型有哪些?
電腦視覺
您在建立電腦視覺系統時,必須先標示影像、像素或關鍵點,或是建立完全包含數位影像 (稱為週框方塊) 的邊界,以產生訓練資料集。例如,您可按品質類型 (例如產品與生活方式影像) 或內容 (影像本身的實際內容) 來將影像分類,或者您可在像素層級區分影像。然後,您可使用此訓練資料來建立電腦視覺模型,可用於自動分類影像、偵測物件位置、識別影像的關鍵點或區段影像。
自然語言處理
自然語言處理需要您首先手動識別文字的重要部分,或使用特定標籤標記文字才能產生訓練資料集。例如,您可能需要識別文字摘要的情緒或意圖、識別語音部分、分類適當名詞,例如地點和人物,以及識別影像、PDF 或其他檔案的文字。為此,您可在文字周圍繪製邊界框,然後手動轉錄訓練資料集的文字。自然語言處理模型用於情緒分析、實體名稱識別和光學字元識別。
音訊處理
音訊處理將所有類型的聲音,例如語音、野生動物噪音 (叫聲、哨聲或尖叫聲) 以及建築聲音 (破玻璃、掃描或警報) 轉換為結構化的格式,以便可用於機器學習。音訊處理通常需要您先將其手動轉錄為書面文字。您可藉此加上標籤和分類音訊來發現有關音訊的深入資訊。此分類音訊會成為您的訓練資料集。
資料標記的最佳做法有哪些?
有許多技術可提高資料標記的效率和準確性。其中一些技術包括:
- 直觀且簡化的任務介面,有助於盡可能減少人類標記員的認知負載和上下文切換。
- 標記員共識有助於抵消個別標註者的錯誤/偏差。標籤人員共識涉及將每個資料集對象發送給多個標註者,然後將其回應 (稱為「標註」) 合併到單一標籤。
- 標籤稽核以驗證標籤的準確性,並視需要更新它們。
- 主動式學習使用機器學習識別人類要標記最有用的資料,使資料標記更有效率。
如何有效進行資料標記?
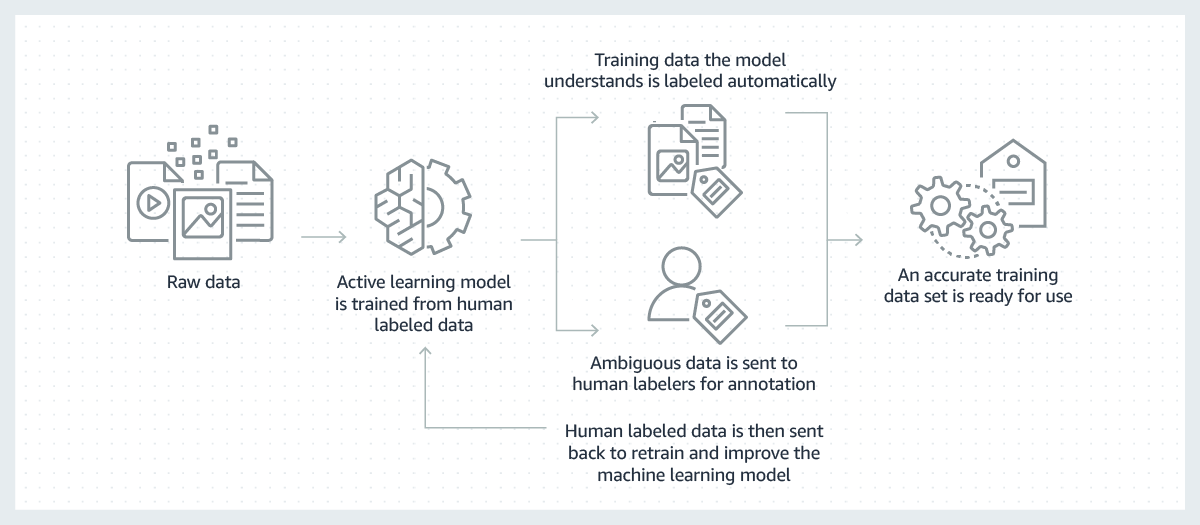
成功的機器學習模型仰賴於大量的高品質訓練資料。但是,建立這些模型必要訓練資料的流程通常費用高昂、做法複雜而且耗時。現今所建立的大多數模型都需要人員手動標籤資料,藉此讓模型學習如何正確做決策。為了克服這種挑戰,可使用機器學習模型自動標記資料來提高標籤效率。
在此過程,會先針對已由人類標記的原始資料子集上訓練用於標示資料的機器學習模型。若標籤模型依據目前所學結果有了高可信度時,就會自動套用標籤到原始資料。若標籤模型所得的結果可信度低,就會將資料傳給人員進行標籤。然後,人工生成的標籤會被提供回標籤模型,以便它從中學習並提高其自動標記下一組原始資料的能力。隨著時間經過,模型可自動標記更多資料,並且大幅加快建立訓練資料集的速度。
AWS 如何支援您的資料標記需求?
Amazon SageMaker Ground Truth 大幅減低建立訓練資料集所需的時間和精力,達到成本降低。SageMaker Ground Truth 讓您輕鬆取用公有和私有的標籤人員,並且為他們提供內建工作流程和常見標籤任務的界面。使用 SageMaker Ground Truth 開始使用很容易。入門教學課程可用於在幾分鐘內建立您的第一個標記工作。
立即建立帳戶,開始使用 AWS 上的資料標記。