



什麼是綜合資料?
綜合資料是非人類建立的資料,用於模仿真實世界的資料。它是由以生成式人工智慧技術為基礎的運算演算法和模擬建立的。綜合資料集具有與其所基於的實際資料相同的數學屬性,但不包含任何相同的資訊。組織將綜合資料用於研究、測試、新開發和機器學習研究。最近的人工智慧創新不僅提高了綜合資料的產生效率和速度,還提升了其在資料監管問題中的重要性。
綜合資料有哪些優勢?
綜合資料為組織提供多種優勢。我們將在下面討論其中一些優勢。
無限量產生資料
可以隨需產生幾乎無限規模的綜合資料。綜合資料產生工具是取得更多資料的一種經濟高效的方式。這些工具還可以預先標注 (分類或標記 ) 為機器學習使用案例產生的資料。您無需經歷從頭開始轉換原始資料的程序,即可存取結構化的標注資料。還可以將綜合資料新增至擁有的總資料量中,從而產生更多用於分析的訓練資料。
隱私權保護
醫療保健、金融和法律部門等領域制定了許多保護敏感性資料的隱私權、著作權和合規法規。但是,這些領域必須使用資料進行分析和研究,通常必須將資料外包給第三方以最大限度地利用資料。它們可以使用綜合資料代替個人資料來達到與這些私有資料集相同的目的。它們建立類似的資料,在不暴露私有或敏感性資料的情況下顯示相同的統計相關資訊。以醫學研究依據即時資料集建立綜合資料為例,綜合資料保持與原始資料集相同的生物學特徵和遺傳標記百分比,但所有姓名、地址和其他個人患者資訊都是虛假的。
偏差減少
可以使用綜合資料來減少人工智慧訓練模型中的偏差。由於大型模型通常在公開提供的資料上進行訓練,因此文字中可能會存在偏差。研究人員可以使用綜合資料來對比 AI 模型收集的任何帶偏差的語言或資訊。例如,如果某些以觀點為基礎的內容偏向特定群體,則可以建立綜合資料來平衡整個資料集。
綜合資料有哪些類型?
綜合資料主要有兩種類型 — 部分和完整。
部分綜合資料
部分綜合資料用綜合資訊取代真實資料集的一小部分。可以使用此類型保護資料集的敏感部分。例如,如果需要分析客戶特定的資料,則可以綜合諸如姓名、聯絡方式以及其他可以追溯到特定人員的真實世界資訊之類的屬性。
完整綜合資料
在完整綜合資料中,您完全產生新的資料。完整綜合資料集將不包含任何真實世界的資料。但是,它將使用與真實資料相同的關係、繪圖分佈和統計屬性。雖然這些資料不是來自實際記錄的資料,但它可以讓您得出相同的結論。
在測試機器學習模型時,您就可以使用完整綜合資料。如果想要測試或建立新模型,但沒有足夠的真實訓練資料來提高機器學習準確性,完整綜合資料就會很有用。
如何產生綜合資料?
綜合資料的產生涉及使用運算方法和模擬來建立資料。結果模仿現實世界資料的統計特性,但不包含實際的真實觀測結果。產生的資料可以採用各種形式,包括文字、數位、資料表或更複雜的類型,例如影像和視訊。產生綜合資料主要有三種方法,每種方法都提供不同層級的資料準確性和類型。
統計分佈
在這種方法中,首先分析真實資料以確定其潛在的統計分佈,例如正態分佈、指數分佈或卡方分佈。然後,資料科學家從這些已識別的分佈中產生綜合範例,以建立在統計學上與原始資料集相似的資料集。
以模型為基礎
在這種方法中,訓練機器學習模型以理解和複寫真實資料的特徵。經過訓練的模型可以產生與真實資料具有相同統計分佈的人工資料。這種方法對於建立混合資料集特別有用,混合資料集將真實資料的統計特性與其他綜合元素相結合。
深度學習方法
可以使用生成對抗網路 (GAN)、變分自動編碼器 (VAE) 等進階技術來產生綜合資料。這些方法通常用於更複雜的資料類型,例如影像或時間序列資料,並且可以產生高品質的綜合資料集。
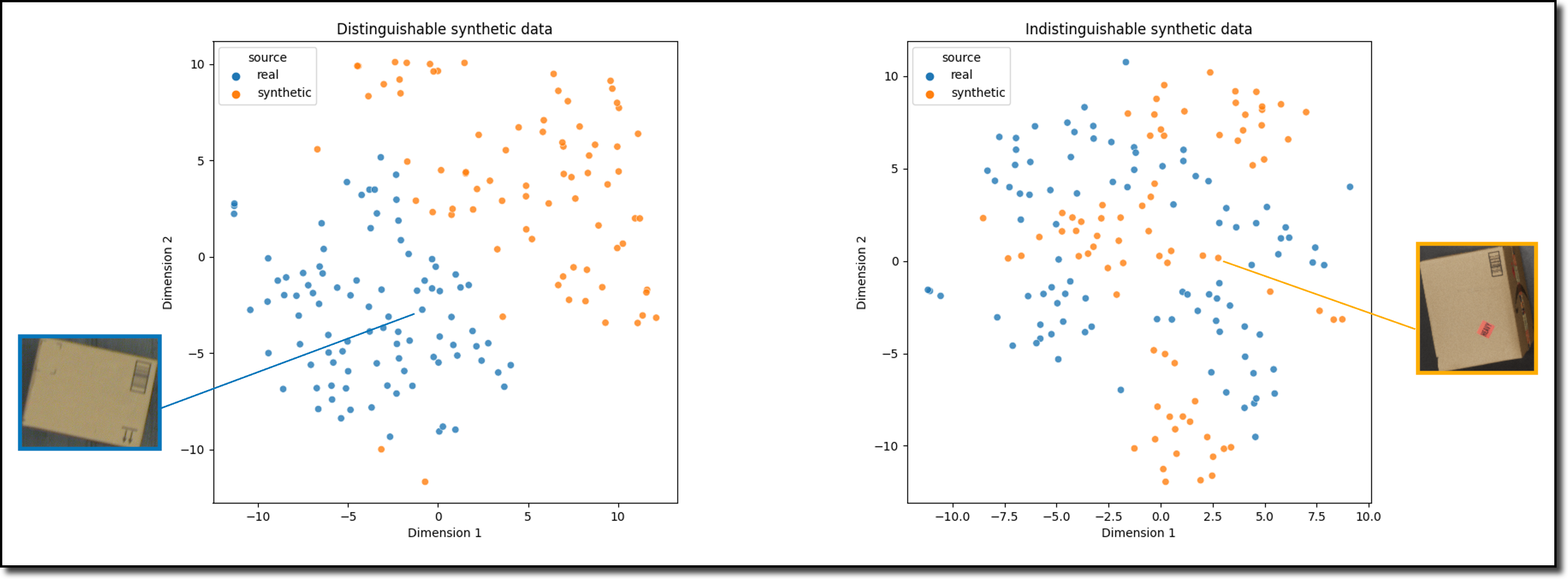
什麼是綜合資料產生技術?
我們在下面概述了一些可用于產生綜合資料的進階技術。
生成式對抗網路
生成式對抗網路 (GAN) 模型使用兩個神經網路,它們協同工作來產生和分類新資料。一個網路使用原始資料生成綜合資料,而第二個網路則對該資訊進行評估、特徵化和分類。這兩個網路相互競爭,直到評估網路無法再區分綜合資料和原始資料。
可以使用 GAN 建立人工產生的資料,這些資料高度自然,可以密切呈現現實世界資料的變化,例如逼真的視訊和影像。
变分自动编码器
變分自動編碼器 (VAE) 是依據原始資料的表示產生新資料的演算法。非監督式演算法學習原始資料的分佈,然後使用編碼器-解碼器架構透過雙重變換產生新資料。編碼器將輸入資料壓縮成低維表示形式,解碼器依據這種潛在表示形式重建新資料。該模型使用概率計算來實現順暢的資料重建。
在生成具有變化的非常相似的綜合資料時,VAE 最有用。例如,您可以在產生新影像時使用 VAE。
以轉換器為基礎的模型
生成式預訓練轉換器或以 GPT 為基礎的模型使用大型原始資料集來了解資料的結構和典型分佈。主要在自然語言處理 (NLP ) 生成中使用這些模型。例如,如果以轉換器為基礎的文字模型在大型英語文字資料集上訓練,它就會學習該語言的結構、語法甚至細微差別。產生綜合資料時,模型從種子文字 (或提示) 開始,並依據所學的概率預測下一個字詞,從而產生完整的序列。
綜合資料產生面臨哪些挑戰?
建立綜合資料時會面臨一些挑戰。以下是您在使用綜合資料時可能會遇到的一些一般限制和挑戰。
品質控制
資料品質在統計和分析中至關重要。在將綜合資料納入學習模型之前,必須檢查其準確性以及是否達到最低資料品質水準。但是,確保沒有人能夠透過綜合資料點追溯到真實資訊可能需要降低準確性。在隱私權和準確性方面進行權衡可能會影響品質。
在使用綜合資料之前,您可以對其進行手動檢查,這可以幫助解決此問題。但是,如果您需要產生大量綜合資料,則手動檢查可能會變得很耗時。
技術挑戰
建立綜合資料很困難 — 必須了解技術、規則和當前方法,以確保其準確性和實用性。在產生任何有用的綜合資料之前,您需要在該領域具有很高的專業知識。
無論您掌握多少專業知識,要產生綜合資料來完美模仿現實世界中的資料都是一項艱巨的任務。例如,現實世界的資料通常包含異常值和異常狀況,綜合資料生成演算法很少能重現這些異常值和異常狀況。
利害關係人的困惑
儘管綜合資料是一種有用的補充工具,但並非所有利害關係人都能理解其重要性。作為一項較新的技術,一些企業使用者可能不認為綜合資料分析與現實世界息息相關。另一方面,由於產生的受控方面,其他人可能會過分強調結果。向利害關係人傳達這項技術的局限性及其結果,確保他們瞭解優缺點。
AWS 如何支援您的綜合資料產生工作?
Amazon SageMaker 是一項完全受管的服務,用來準備資料以及建置、訓練和部署機器學習 (ML) 模型。這些模型適用于任何具有完全受管基礎設施、工具和工作流程的使用案例。SageMaker 提供兩個選項,可讓您標記原始資料,例如影像、文字檔案和視訊,並產生標注綜合資料,以建立用於訓練 ML 模型的高品質資料集。
- Amazon SageMaker Ground Truth 是一款自助服務,可輕鬆標注資料。藉助該服務,您可以選擇透過 Amazon Mechanical Turk、第三方供應商或自己的私人員工使用人工標注人員。
- Amazon SageMaker Ground Truth Plus 是一項完全受管的服務,可讓您建立高品質的訓練資料集。您不必自己建置標注應用程式或管理標注人員。
首先,您可指定綜合影像要求或提供 3D 資產和基準影像,例如電腦輔助設計 (CAD) 影像。然後,AWS 數位藝術家從頭開始建立影像或使用客戶提供的資產。產生的影像會模仿物件的姿勢和放置,包括物件或場景變化,並可選地加入特定包含物件,例如划痕、凹痕和其他變更。這可避免收集資料的耗時程序,也無需損壞部件以擷取影像。可以產生數十萬張綜合影像,這些影像會自動進行高精度標註。
立即建立免費帳戶,開始在 AWS 上產生綜合資料。