



What’s the Difference Between Supervised and Unsupervised Machine Learning?
Supervised and unsupervised machine learning (ML) are two categories of ML algorithms. ML algorithms process large quantities of historical data to identify data patterns through inference.
Supervised learning algorithms train on sample data that specifies both the algorithm's input and output. For example, the data could be images of handwritten numbers that are annotated to indicate which numbers they represent. Given sufficient labeled data, the supervised learning system would eventually recognize the clusters of pixels and shapes associated with each handwritten number.
In contrast, unsupervised learning algorithms train on unlabeled data. They scan through new data and establish meaningful connections between the unknown input and predetermined outputs. For instance, unsupervised learning algorithms could group news articles from different news sites into common categories like sports and crime.
Techniques: supervised vs. unsupervised learning
In machine learning, you teach a computer to make predictions, or inferences. First, you use an algorithm and example data to train a model. Then, you integrate your model into your application to generate inferences in real time and at scale. Supervised and unsupervised learning are two distinct categories of algorithms.
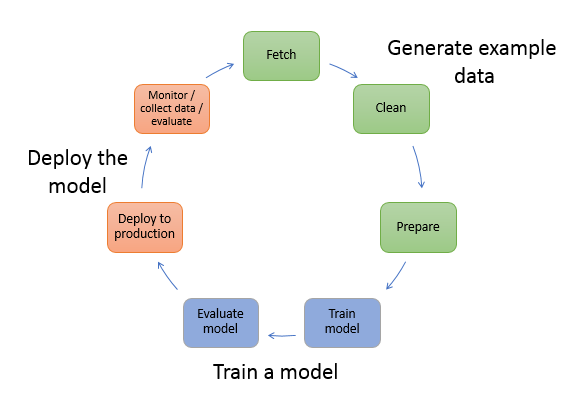
Supervised learning
In supervised learning, you train the model with a set of input data and a corresponding set of paired labeled output data. The labeling is typically done manually. Next are some types of supervised machine learning techniques.
Logistic regression
Logistic regression predicts a categorical output based on one or more inputs. Binary classification is when the output fits into one of two categories, such as yes or no and pass or fail. Multiple class classification is when the output fits into more than two categories, such as cat, dog, or rabbit. An example of logistic regression is predicting whether a student will pass or fail a unit based on their number of logins to the courseware.
Read about logistic regression »
Linear regression
Linear regression refers to supervised learning models that, based on one or more inputs, predict a value from a continuous scale. An example of linear regression is predicting a house price. You could predict a house’s price based on its location, age, and number of rooms, after you train a model on a set of historical sales training data with those variables.
Read about linear regression »
Decision tree
The decision tree supervised machine learning technique takes some given inputs and applies an if-else structure to predict an outcome. An example of a decision tree problem is predicting customer churn. For example, if a customer doesn’t visit an application after signing up, the model might predict churn. Or if the customer accesses the application on multiple devices and the average session time is above a given threshold, the model might predict retention.
Neural network
A neural network solution is a more complex supervised learning technique. To produce a given outcome, it takes some given inputs and performs one or more layers of mathematical transformation based on adjusting data weightings. An example of a neural network technique is predicting a digit from a handwritten image.
Unsupervised learning
Unsupervised machine learning is when you give the algorithm input data without any labeled output data. Then, on its own, the algorithm identifies patterns and relationships in and between the data . Next are some types of unsupervised learning techniques.
Clustering
The clustering unsupervised learning technique groups certain data inputs together, so they may be categorized as a whole. There are various types of clustering algorithms depending on the input data. An example of clustering is identifying different types of network traffic to predict potential security incidents.
Association rule learning
Association rule learning techniques uncover rule-based relationships between inputs in a dataset. For example, the Apriori algorithm conducts market basket analysis to identify rules like coffee and milk often being purchased together.
Probability density
Probability density techniques in unsupervised learning predict the likelihood or possibility of an output’s value being within range of what is considered normal for an input. For example, a temperature gauge in a server room typically records between a certain degree range. However, if it suddenly measures a low number based on the probability distribution, it may indicate equipment malfunction.
Dimensionality reduction
Dimensionality reduction is an unsupervised learning technique that reduces the number of features in a dataset. It’s often used to preprocess data for other machine learning functions and reduce complexity and overheads. For example, it may blur out or crop background features in an image recognition application.
When to use: supervised vs. unsupervised learning
You can use supervised learning techniques to solve problems with known outcomes and that have labeled data available. Examples include email spam classification, image recognition, and stock price predictions based on known historical data.
You can use unsupervised learning for scenarios where the data is unlabeled and the objective is to discover patterns, group similar instances, or detect anomalies. You can also use it for exploratory tasks where labeled data is absent. Examples include organizing large data archives, building recommendation systems, and grouping customers based on their purchasing behaviors.
Can you use both supervised and unsupervised learning together?
Semi-supervised learning is when you apply both supervised and unsupervised learning techniques to a common problem. It’s another category of machine learning in itself.
You can apply semi-supervised learning when it’s difficult to obtain labels for a dataset. You might have a smaller volume of labeled data but a significant amount of unlabeled data. Compared to using the labeled dataset alone, you’d have greater accuracy and efficiency if you combine supervised and unsupervised learning techniques.

Here are a few examples of semi-supervised learning applications.
Fraud identification
Within a large set of transactional data, there’s a subset of labeled data where experts have confirmed fraudulent transactions. For a more accurate result, the machine learning solution would train first on the unlabeled data then with the labeled data.
Sentiment analysis
When considering the breadth of an organization’s text-based customer interactions, it may not be cost-effective to categorize or label sentiment across all channels. An organization could train a model on the larger unlabeled portion of data first, and then a sample that has been labeled. This would provide the organization with a greater degree of confidence in customer sentiment across the business.
Document classification
When applying categories to a large document base, there may be too many documents to physically label. For example, these could be countless reports, transcripts, or specifications. Training on the unlabeled data to begin with helps identify similar documents for labeling.
Summary of differences: supervised vs. unsupervised learning
| Supervised learning |
Unsupervised learning |
|
| What is it? |
You train the model with a set of input data and a corresponding set of paired labeled output data. |
You train the model to discover hidden patterns in unlabeled data. |
| Techniques |
Logistic regression, linear regression, decision tree, and neural network. |
Clustering, association rule learning, probability density, and dimensionality reduction. |
| Goal |
Predict an output based on known inputs. |
Identify valuable relationship information between input data points. This can then be applied to new input to draw similar insights. |
| Approach |
Minimize the error between predicted outputs and true labels. |
Find patterns, similarities, or anomalies within the data. |
How can AWS help with supervised and unsupervised learning?
Amazon Web Services (AWS) offers a wide range of offerings to help you with supervised, unsupervised, and semi-supervised machine learning (ML). You can build, run, and integrate solutions of any size, complexity, or use case.
Amazon SageMaker is a complete platform to build your ML solutions from the ground up. SageMaker has a full suite of prebuilt supervised and unsupervised learning models, storage and compute capabilities, and a fully managed environment.
For example, here are SageMaker features you can use in your work:
- Use Amazon SageMaker Canvas to automatically explore different solutions and find the best model for your given dataset.
- Use Amazon SageMaker Data Wrangler to select data, understand data insights, and transform data to prepare it for ML.
- Use Amazon SageMaker Experiments to analyze and compare ML training iterations to choose the best-performing model.
- Use Amazon SageMaker Clarify to detect and measure potential bias. This way, ML developers can address potential bias and explain model predictions.
Get started with supervised and unsupervised machine learning on AWS by creating an account today.
Next Steps with AWS
Learn how to get started with Supervised Machine Learning on AWS
Learn how to get started with Unsupervised Machine Learning on AWS