Background on APIs and business logic: GraphQL vs. REST
Web APIs are changing the world. APIs allow us to connect and program the world like never before as they help abstract a complex domain behind a clean, simple interface. APIs can be used to control the physical world, such as mailing physical letters, to control the digital world, such as sending SMS messages, or a combination of the two, such as provisioning and configuring racks of servers.
There are two broad patterns of web APIs that are popular today. The first, called "REST APIs", are more traditional. REST APIs use the URL path and HTTP method in the HTTP request to indicate the desired operation to perform, such as creating a new user or retrieving a list of orders. While the original specification for REST APIs had more precise rules about the URL structure, the term "REST API" is generally used to refer to any web APIs that expose different operations on different URL paths.
A second, newer type of API is GraphQL. Unlike REST APIs, GraphQL APIs tend to have a single URL path. Rather than customizing the backend logic by the URL path and HTTP method, requests to the GraphQL endpoint are customized by the request payload. The data needed is included in the payload body of a GraphQL request, and the GraphQL server implementation will do the work to fetch that data. On the server backend, the different elements of a request will be handled by resolvers that are used to retrieve the requested data.
Regardless of the API type, REST-like or GraphQL, business logic must be written. The business logic is the core of an application. When a client makes a request to an API, the business logic is utilized to process the request, ensuring that it does not break any rules or constraints in the domain. There may also enqueue additional steps to work with the data or perform further actions to complete the request. Essentially, the business logic is the differentiated part of the application that adds value to users.
The sections below goes over options for implementing business logic in serverless APIs on AWS.
Building serverless REST APIs on AWS
When building serverless REST APIs on AWS, there are two decisions to make about the application’s core infrastructure: First, which service will be used to route HTTPS requests to the compute that is handling the business logic. This is commonly referred to as a "reverse proxy." Second, which patterns will be used for the business logic.
For the reverse proxy, there are three main options:
- AWS API Gateway REST APIs: This was the first option for connecting HTTP requests to AWS Lambda functions. It provides a full-featured API Gateway solution with path-based routing, authentication and authorization, request and response transformation, caching, and more.
- AWS API Gateway HTTP APIs: API Gateway HTTP APIs provide a more serverless-native reverse proxy layer. They have lower costs and latency than the traditional REST APIs. While they offer some higher-level features like authentication and authorization, they do not include all of the features of the traditional REST APIs. Refer to the API Gateway documentation for a detailed comparison between REST APIs and HTTP APIs.
- AWS Application Load Balancers (ALBs): To avoid the API Gateway family of services altogether, consider an Application Load Balancer ("ALB"). Rather than the pay-per-request billing model of API Gateway, ALBs use a combination of hourly fees plus usage-based costs. For high-traffic applications, this can be cheaper than API Gateway.
All three options can work for a serverless API, and the choice between them will come down to the specific needs of the application.
The second decision to make is the focus of this article -- how to handle the business logic in a serverless API. Like with HTTPS routing choice, there are three options:
- Mono-Lambda: Route all HTTP requests to a single Lambda function, and that function will internally route the requests to the relevant business logic based on the URL path and HTTP method.
- Use a separate Lambda function for each path + method combination: Rather than routing within a single Lambda function, the HTTPS routing layer can route to specific Lambda functions based on the URL path and HTTP method in the request. This is the pattern recommended by AWS where possible.
- Skip the Lambda function with direct service integrations: Skip the compute layer altogether by using config-like syntax to go directly from the reverse proxy to infrastructure services like Amazon DynamoDB, Amazon SQS, or Amazon S3.
Note that the structure of the business logic is separate from a decision of whether to use a microservice architecture. There can be multiple microservices, each of which use one of the three patterns above, in building serverless applications on AWS.
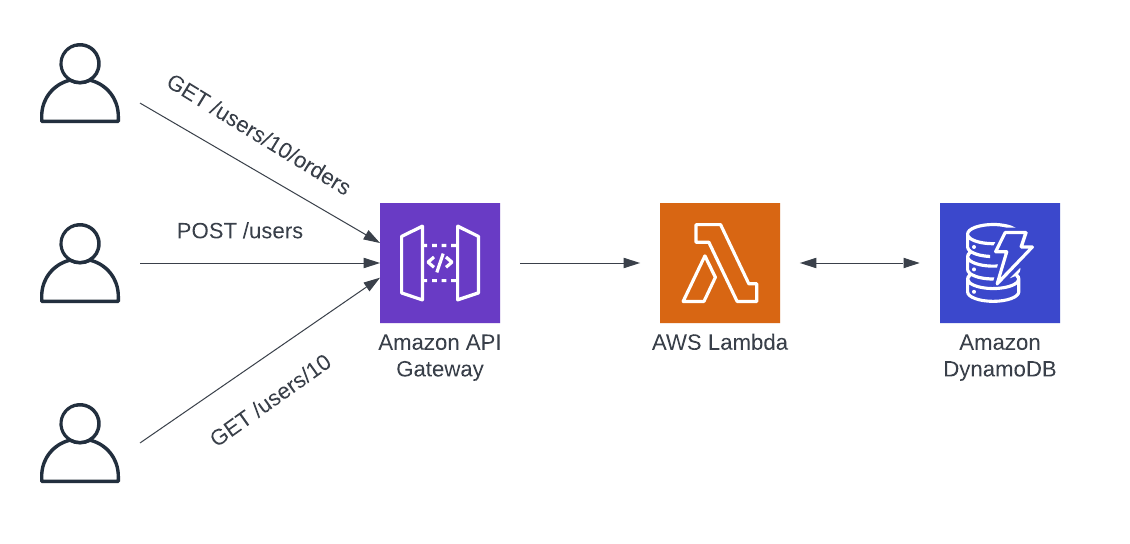
1. Building a mono-Lambda pattern for the serverless API
The first pattern for managing business logic in a serverless API is the "mono-Lambda" pattern. While this is not the recommended pattern for most applications, it is most similar to a pre-serverless world.
In a mono-Lambda pattern, all of the business logic is contained in a single Lambda function. The reverse proxy for the API will route all requests, regardless of URL path and method, to the same target Lambda function. The Lambda function will do the routing internally to handle the request properly based on the given path and method.
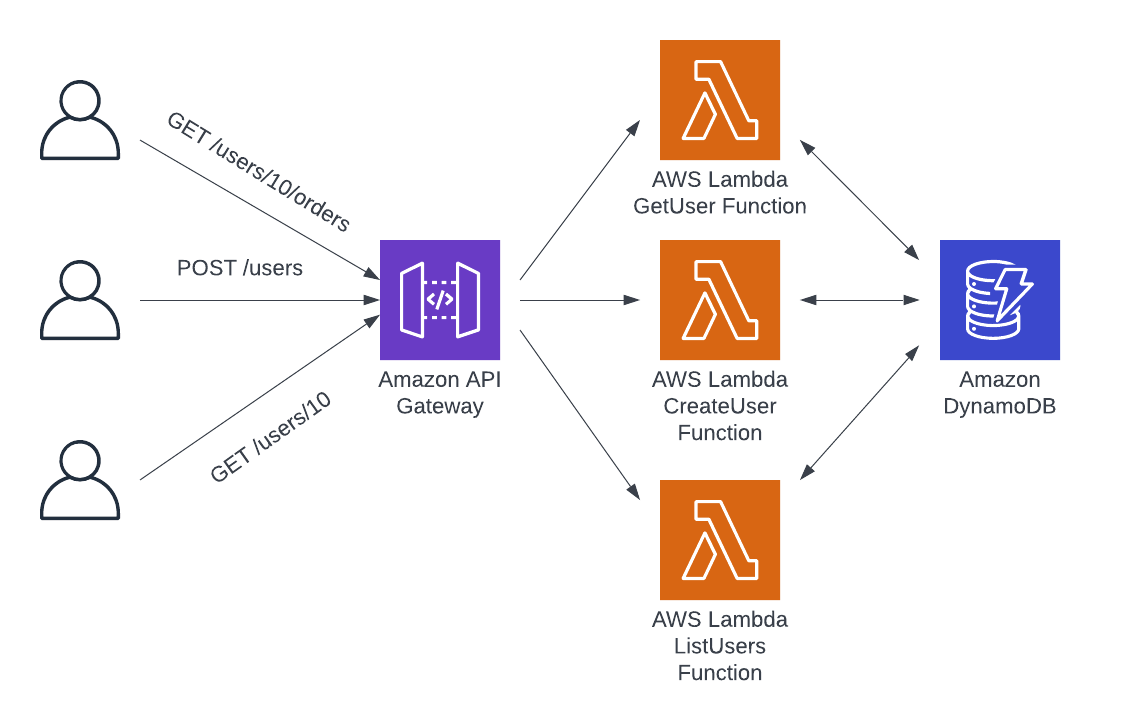
2. Using single-purpose Lambda functions in the API
The second pattern for implementing business logic in serverless REST APIs is to use separate Lambda functions for each unique combination of URL path and HTTP method in the API. This is the recommended design pattern for most serverless REST APIs.
In this pattern, the reverse proxy is doing more work. The last pattern had the reverse proxy route all incoming requests to the same target Lambda function. With the single-purpose pattern, each separate Lambda function is registered with the reverse proxy with a specified URL path and HTTP method. When a request is received, the reverse proxy will forward it to a specific Lambda target based on the path and method in the request.
Pros
The main benefits here are the inverse of the downsides from the previous pattern. Each Lambda function will have its own logs and metrics, so there will be fine-grained visibility into each endpoint in the application.
When an alert about unexpected errors is triggered, it pinpoints whether the issue is isolated to one endpoint or is a broad-based problem. If the errors are isolated to a single endpoint, it is more efficient to look at the logs for just that endpoint's function rather than a large mess of combined logs. It is easy to see whether the caching added to the getUser endpoint has reduced latency as expected rather than trying to parse overall application latency.
Further, function bundle sizes and initialization logic should be smaller with single-purpose functions, which will result in lower cold-start latency for functions.
Cons
One of the main objections to this pattern is around the unfamiliarity of it -- it feels different from the traditional web framework patterns, or it seems unwieldy to have so many separate functions to manage.
These objections are overstated. It is true that there might be a need to learn new patterns, but most previous knowledge will carry over. Further, it is ideal to use some infrastructure-as-code tool to manage the deployment of a serverless API. Nearly all of the popular infrastructure-as-code tools, such as AWS Serverless Application Model (SAM) or the AWS CDK, make it easy to manage the deployment and configuration of multiple functions.
In most situations, it is best to choose the single-purpose Lambda functions over the mono-Lambda pattern. However, there are certain occasions where even the Lambda itself is unnecessary.
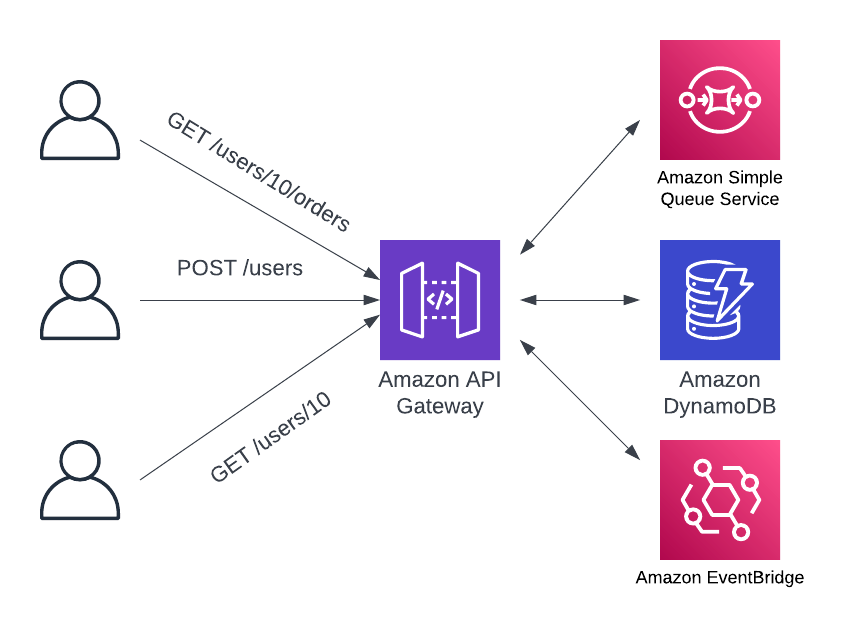
3. Skipping the Lambda function with direct service integrations
The third pattern for handling business logic in serverless REST APIs is to use a direct service integration from the reverse proxy. This pattern is commonly referred to as a "functionless" approach given that it does not use a Lambda function to handle the request.
When implementing focused, single-purpose Lambda functions, it is likely that some of them will be quite simple. It may be accepting an event and immediately shoving it into an SQS queue. Or, perhaps it is deleting a record from the database once it is verified that the requesting client is authorized to do so.
If there is not a lot of computation or manipulation in the business logic, the full power of a general-purpose programming language may not be needed. The API Gateway reverse proxies can provide authentication, authorization, and validation on your incoming requests. With a direct service integration, elements of the incoming request can assemble a new request to a supported AWS service. In doing so, it is possible to perform operations against DynamoDB or SQS directly from API Gateway without a Lambda function in the middle.
Building serverless GraphQL APIs on AWS
When deciding to build a serverless GraphQL API on AWS, there are a few options. In contrast with REST APIs, the decision of reverse proxy is less important. The reverse proxy layer is doing less in a GraphQL API as there is generally a single HTTP route in the application. With GraphQL, the main difference comes in the request body from the client.
When building a GraphQL API, decisions should focus on the best way to manage resolvers. In GraphQL, all of the business logic will be implemented within resolvers that specify how to retrieve a requested field. Because the shape of a GraphQL response is dictated by the GraphQL query submitted in the request body, it is likely that it will call multiple resolvers in a single request and even call the same resolver multiple times with different inputs. Read more about building GraphQL resolvers for AWS data sources.
Thus, the core concern should be around how to manage the implications of GraphQL in a way that gives the flexibility and end-user performance that GraphQL promises without adding to backend complexity or hiding operational visibility.
For implementing the business logic of a serverless GraphQL API on AWS, there are a few decisions to make.
- First, consider managed GraphQL API or self-hosted GraphQL. Many users choose to use AWS AppSync, a fully managed GraphQL service that takes on much of the burden for hosting GraphQL APIs. However, it is also possible for developers to manage their own GraphQL server using a combination of a reverse proxy and Lambda functions that were described in the REST API patterns above.
- Second, if using AWS AppSync, there is the option to use a Lambda function or a native AppSync function to implement the business logic. This decision is similar to the "Lambda function vs. direct service integration" tradeoffs discussed above.
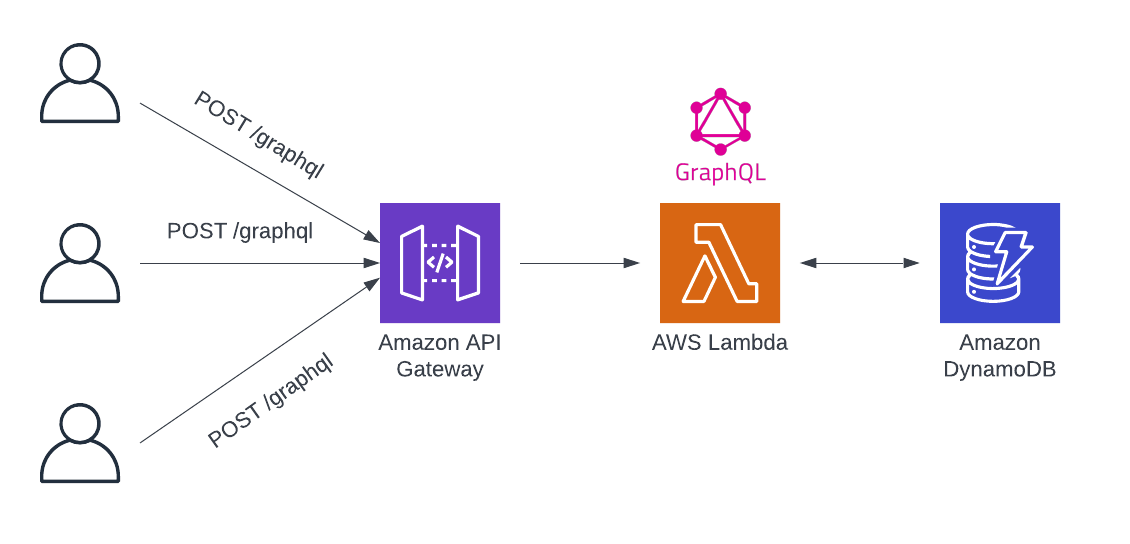
1. Self-hosted serverless GraphQL API with API Gateway and Lambda
The first option is to host GraphQL APIs using AWS API Gateway and AWS Lambda. Lambda is a general-purpose compute environment, so it can be used to handle GraphQL requests and invoke the necessary resolvers.
This is the self-hosted option, but it is nothing like spinning up servers, installing low-level system dependencies, and making sure there is enough disk space. AWS Lambda offers the benefits of managed compute, while API Gateway offers managed reverse proxy.
Further, because this option provides control over the compute environment, it is possible to customize the GraphQL implementation as desired. If there is a preference for the Apollo server implementation for JavaScript or other GraphQL servers, they can be brought in and tuned as needed.
However, managing a GraphQL server within Lambda comes with its own downsides. First, due to the way GraphQL works, it is necessary to use the "mono-Lambda" pattern mentioned above. It is strongly recommended to avoid synchronous communication between Lambda functions while handling a request. Because GraphQL can execute multiple resolvers to handle a request, the entire GraphQL server needs to be packed into a single Lambda function to avoid these synchronous requests.
Using the mono-Lambda pattern means all the downsides of the mono-Lambda pattern above, including slower cold starts and less isolated metrics. The specifics of GraphQL can even exacerbate these problems. Initializing a GraphQL server within a Lambda function is often slower than a comparable REST-based implementation. Further, there will be very little visibility into the performance of distinct GraphQL requests, let alone the performance of individual resolvers.
2. Using a managed GraphQL service with custom Lambda functions
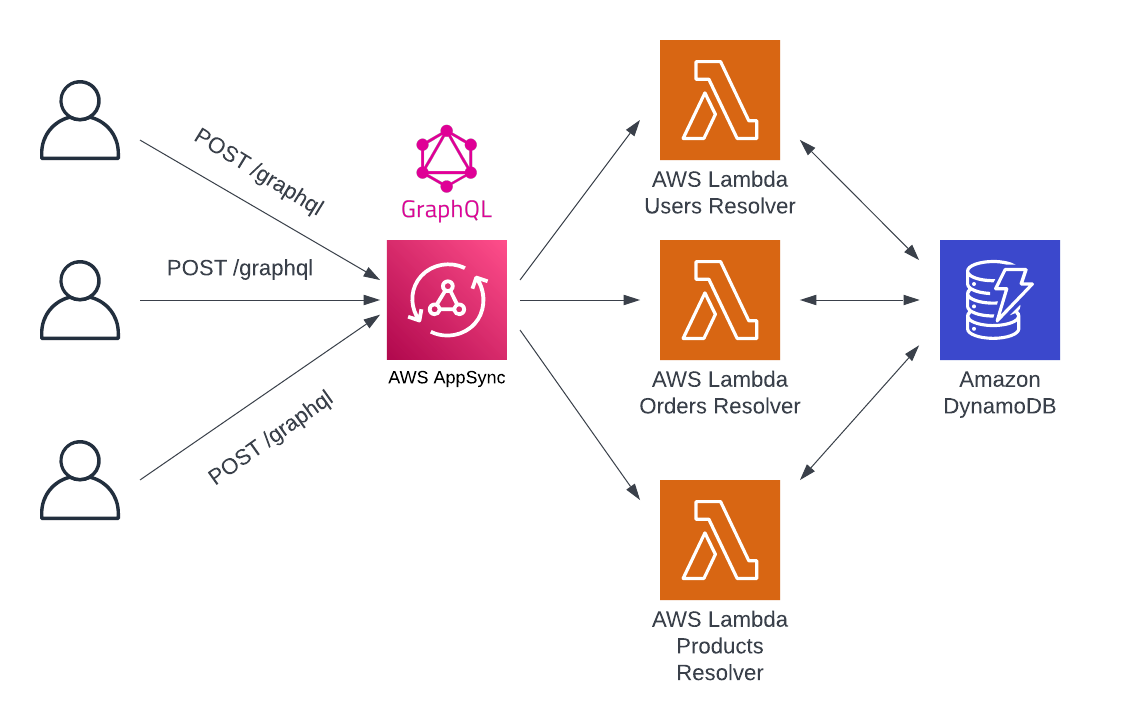
This approach provides flexibility where needed, and a managed solution otherwise. In Lambda function resolvers, the full power of a general-purpose programming language is available to resolve the required data. It’s possible to reach out to a database, call third-party APIs, or perform calculations and transformations as needed.
Further, AppSync provides field-level logging to get granular performance data all the way to individual fields in the GraphQL schema. Because GraphQL requests can vary so much from client to client, this can help to identify problem spots and slow areas in the schema.
However, as highlighted in the REST API section, sometimes a Lambda function is even more than needed. With Lambda, there are additional costs and latency for each request, and a need to deal with cold starts the first time a function is invoked. For more straightforward resolver implementations, a more lightweight approach might be preferable.
3. Connecting to data sources directly with AppSync Functions
The final way to implement business logic in serverless GraphQL APIs on AWS is by using AppSync Functions. With AppSync functions, AppSync still manages most of the aspects of the GraphQL API. However, rather than using a full Lambda function for the business logic, an AppSync Function connects directly to a data source.
An AppSync Function is similar to a direct service integration in API Gateway. In both cases, there is a direct connection from a reverse proxy to a downstream AWS service or another HTTP endpoint without a Lambda function in between. However, rather than handing an entire request to the REST API, AppSync Functions are used to handle specific resolvers in the GraphQL API.
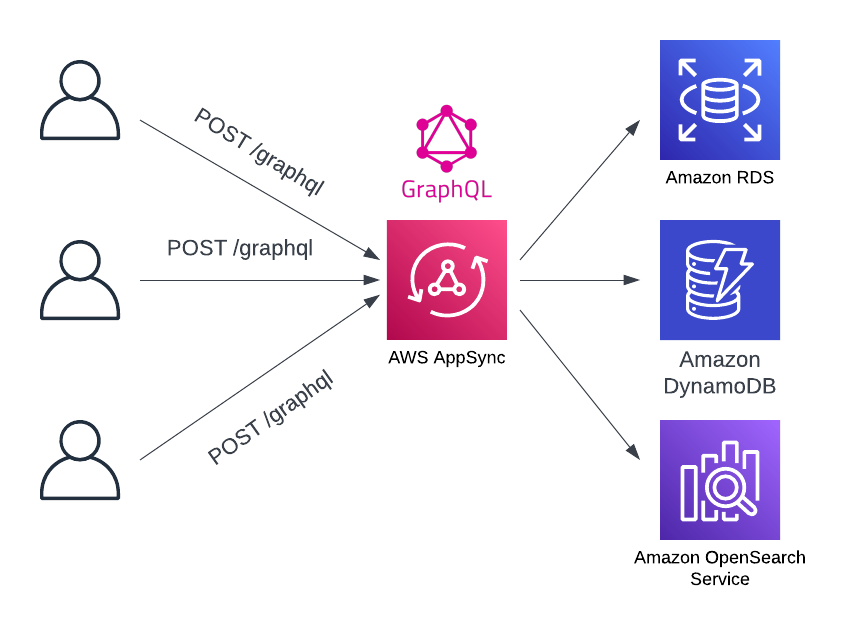
AppSync Functions have all the benefits of direct service integrations in API Gateway. There is no need to pay for the cost of a Lambda function or incur the extra latency of using the Lambda service between a proxy and downstream service. Further, there is no requirement to use VTL to compose AppSync Functions. AppSync Functions can be written in JavaScript. This allows to use a familiar language along with testing patterns and type definitions that are used in the rest of the application.
There are certain situations where AppSync Functions will not work for. AppSync Functions are designed around preparing a request to a data source and interpreting the response. If the business logic requires more complex computation or calls to multiple data sources in a single resolver, it may be best to rely on the full customizability of a Lambda function for the resolver. Read more about creating serverless GraphQL APIs on AWS.
Conclusion
This article discussed the main options for building Serverless APIs on AWS. First, it covered the two most common types of web APIs: REST-like APIs and GraphQL APIs, including their pros and cons.
Then, it provided details on the patterns available to implement the business logic for each type of API. Each of these patterns have different strengths and weaknesses that need to be considered carefully to make the right decision.
Looking for a fully managed GraphQL service?

Explore AWS AppSync
AWS AppSync is an enterprise level, fully managed serverless GraphQL service with real-time data synchronization and offline programming features. AppSync makes it easy to build data driven mobile and web applications by securely handling all the application data management tasks such as real-time and offline data access, data synchronization, and data manipulation across multiple data sources.